Sorry - looks like I’m not going to be able to make it this time. See you next time!
Hi all,
I suggest we take a break with the calls until the new year and start back up on the week of the 12th of January. I personally have some course homework catch-up to do so I will try and use some of my upcoming holidays to get caught up!
I’ll make sure to post a reminder in Jan for the first session of the new year.
I think that’s a great idea. I actually just got caught up on watching all of the lectures on YouTube over the weekend, but it would be nice to go back and try some of the code assignments.
Just to clarify (and maybe for the benefit of anyone new who stumbles upon this thread), which lesson will be covering on January 12?
I hope everyone here has a great holiday break!
I suggest we pick up again from lesson 7 
Happy new year everyone! Hope everyone managed to have a good break. Just a reminder we’ll meet again on January 12th to discuss lesson 7. As usual, I’ll post zoom link on the day.
There is currently a call from European for the assembly of Artificial Intelligence/ Machine Learning (AI/ML) datasets drawn from the extensive collections on the Europeana website.
I hope some of you will submit an application
Zoom details for later
https://turing-uk.zoom.us/j/94966641522?pwd=TXR1VW4zWXRhNlhuemdmOGprR29GUT09
Meeting ID: 949 6664 1522
Passcode: 428917
Hi,
I’m afraid I can’t make the call today due to a conflicting call. I’ve just watched lesson 7 which I found really useful and more approachable than some of the other sessions. One thing I’d like to hear if your able to discuss it on the call is, examples of Cultural Heritage datasets that might work well with these tabular prediction methods.
Thanks hope the call goes well.
Glen
I have worked with one very nice tabular dataset at work which should be made public at some point. I will ask for an update on how that is going.
I think one potential in a Cultural Heritage is predicting additional metadata based on already available metadata. I think often the tabular part of the data might also be useful as an additional signal for another type of model e.g. for a text classification model it might be useful for the model to also know the date of publication, publisher etc. A nice example of this (which is much simpler than concatenating different types of models) is outlined in https://www.novetta.com/2019/03/introducing_me_ulmfit/.
There are a few datasets derived from BL’s 19th Century books collection that contain tabular data + some genre predictions: https://bl.iro.bl.uk/work/ns/ff82a4ff-12a3-4abe-8108-2c9b1172ccc4. The labels are definitely noisy but it’s a sort of interesting experiment to see whether some of the tabular fields can give enough information to predict the genre of a book.
The web archive classification dataset is also semi tabular but I think it’s probably tricky to get a good performing model on that but it might be fun to try!
I’ll keep an eye out for more tabular data. It might be nice to pick one or two for us to work on and compare results
zoom details for this evening
Topic: fastai4glams
Time: Jan 26, 2021 05:00 PM London
Join Zoom Meeting
Meeting ID: 979 6335 6599
Passcode: 902752
Apologies for missing the final meeting yesterday, I hope it was good!
I’d just like to say thank you to Daniel for setting this up and running it for so long - I’ve found it really helpful to talk through this stuff with other people. So, thank you!
No worries and thanks  I found it really useful too. I will hopefully post the ad for the full stack course tomorrow and probably aim to start that in a month or so. I’ll also send you an email about the other project I vaguely mentioned in the last call.
I found it really useful too. I will hopefully post the ad for the full stack course tomorrow and probably aim to start that in a month or so. I’ll also send you an email about the other project I vaguely mentioned in the last call.
Spotted a nice usage of fastai in a library context!
Machine Learning Based Chat Analysis
The BYU library implemented a Machine Learning-based tool to perform various text analysis tasks on transcripts of chat-based interactions between patrons and librarians. These text analysis tasks included estimating patron satisfaction and classifying queries into various categories such as Research/Reference, Directional, Tech/Troubleshooting, Policy/Procedure, and others. An accuracy of 78% or better was achieved for each category. This paper details the implementation details and explores potential applications for the text analysis tool.
https://journal.code4lib.org/articles/15660
I really liked that they didn’t just use an out of the box chat solution for this. They ended up using a Huggingface transformer model wrapped in fastai for the training. The breakdown of the types of question was surprising to me, I expected way more to be generic ‘what time do you close’ type questions:
| Question Type | Total | Percentage |
|---|---|---|
| Research/Reference | 2936 | 65.6% |
| Policy/Procedure | 124 | 20.4% |
| Tech/Troubles | 397 | 8.9% |
| Directional | 314 | 2.8% |
This survey might be of interest to people in this thread:
What could be the digital humanities’ Hugging Face?
[TL;DR]
We seek to understand what are the most sought after computational resources which, if made available, could greatly facilitate and accelerate digital humanities research for the years to come.
Another link that is probably of interest to people in this thread:
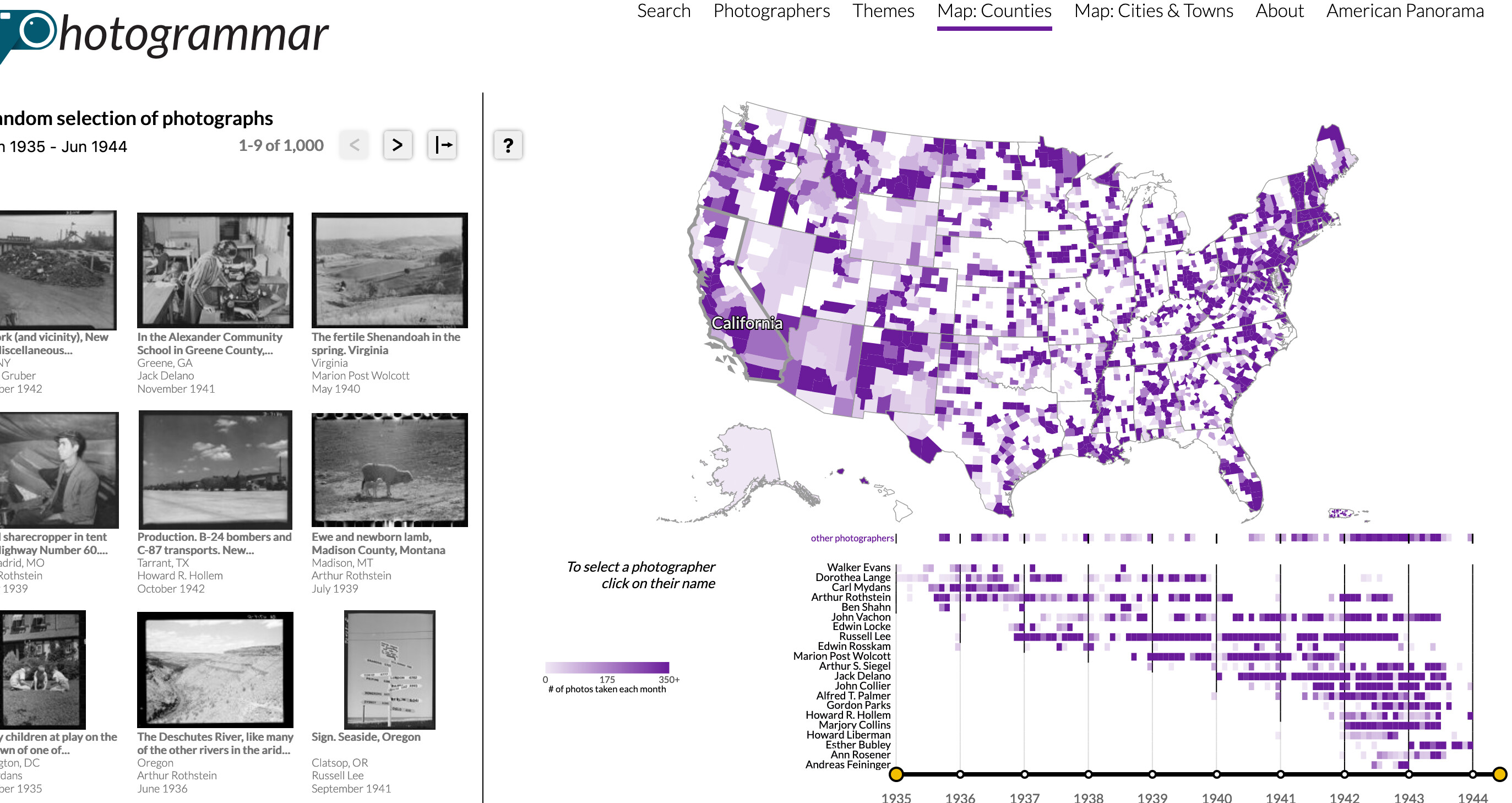
Photogrammar provides a web-based visualization platform for exploring the 170,000 photographs taken by the FSA and OWI agencies of the U.S. Federal Government between 1935 and 1943. The project is maintained by the Digital Scholarship Lab (DSL) and Distant Viewing Lab (DV Lab) at the University of Richmond. Lauren Tilton is the director of the project. Taylor Arnold leads the data curation and analysis. Rob Nelson develops and maintains the web-based application. Nathaniel Ayers designed the site and Justin Madron provided GIS support. Laura Wexler managed the grants. Publications, additional contributors, and major milestones of the project are described in the sections below. The project has been supported by grants from the National Endowment for the Humanities (NEH), American Council of Learned Societies (ACLS), and Yale University with ongoing support from the University of Richmond. The FSA-OWI archive is housed at the Library of Congress, which digitized and maintains the collection including details about rights and restrictions.
Although the ‘theme’ tags were human-generated I think the interface for this project has a lot of features which you might want to replicate if you were working with large scale visual collections with ML tags.
I’m not in GLAM myself, but I want to share an interesting project that someone here might find useful.
PixPlot is written by someone from the Yale DH lab. It gives an end-to-end tool that takes JPGs as input and can generate a dimensionality-reduction visualization in the browser.
I work with massive image datasets in a scientific field and PixPlot is a tool I had been seeking for some time. In general, I think GLAM folks can have some very nice insights about understanding our artifacts that apply to broader knowledge work and dataset understanding. Glad to have stumbled on an active community here!
Thanks for sharing 
What kind of images do you work with? Something I’m curious about with using image embeddings + dimensionality reduction is how well the embeddings ‘translate’ to images in new domains. Is this something you’ve had to deal with?
My data is like this or this. It’s terabyte- or even petabyte-scale, so we need any tricks we can find. In this case, PixPlot calls an InceptionV3 model trained on ImageNet and it gives me useful embeddings.
All the thinking about data interactions, like the Generous Interfaces link @phivk shared, can also apply well–we’re just some more humans trying to puzzle through complex, multi-dimensional datasets. Sometimes I think it can be easier to flesh out interface ideas on more human-adjacent datasets than I normally work with!
2 Likes
That sounds like a really interesting application of PixPlot I’m also going to keep your data in mind when I stress about a few 100Gbs of data 
1 Like
This workshop series might be of interest to anyone following this thread.
5 workshops will take place from the 29th of March to 2 April 2021. The workshops are organised by AI4LAM (Teaching and Learning Working Group) and co-hosted by LIBER and the BnF.
Workshops:
29 March 2021 (18:00-20:00 CEST) – The Role of Data Curation in AI
host: Stanford University Libraries
30 March 2021 (15:00-17:00 CEST) – Beta Test of Library Carpentry Introduction to AI and Machine Learning
host: Smithsonian Data Science Lab
31 March 2021 (15:00-17:00 CEST) – Historical Newspaper Content Mining: findings from the impresso project
host: LIBER
1 April 2021 (18:00-20:00 CEST) – Introduction to visual AI in GLAMs
host: BnF
2 April 2021 (15:00-17:00 CEST) – Introduction to Spark for Machine Learning
host: BnF