Thank You. That seems to have worked. It looks like you just borrowed a couple lines of code from a few cells down the line. I’ll work with this more tomorrow. It’s late for me and time to go to bed. Thank You again.
1 Like
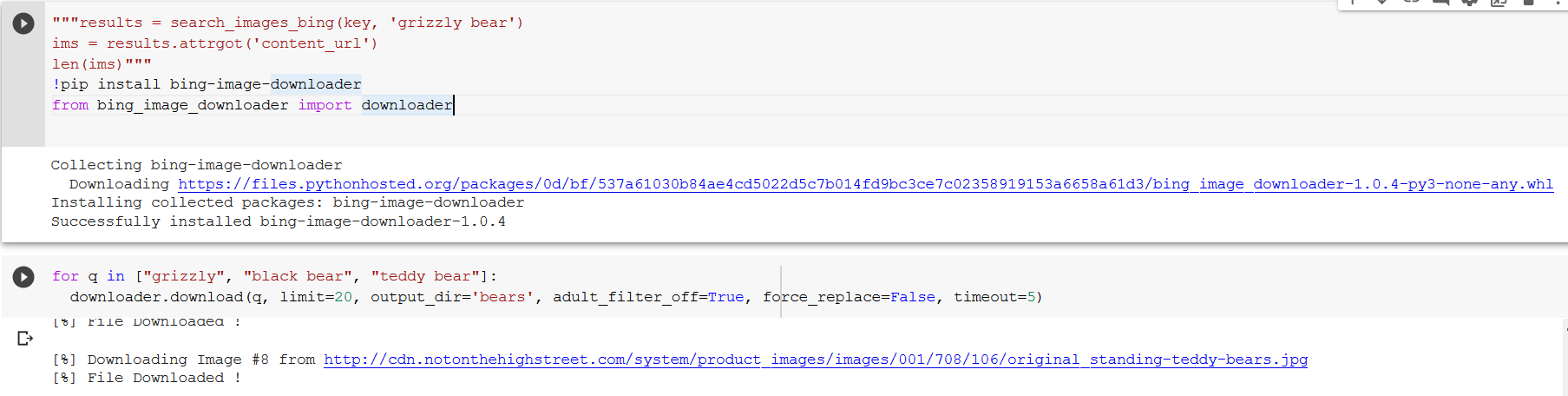
I am getting stuck right before the data augmentation section, I have used the
!pip install bing-image-downloader as the bing image search is not a viable option for me. Please help!
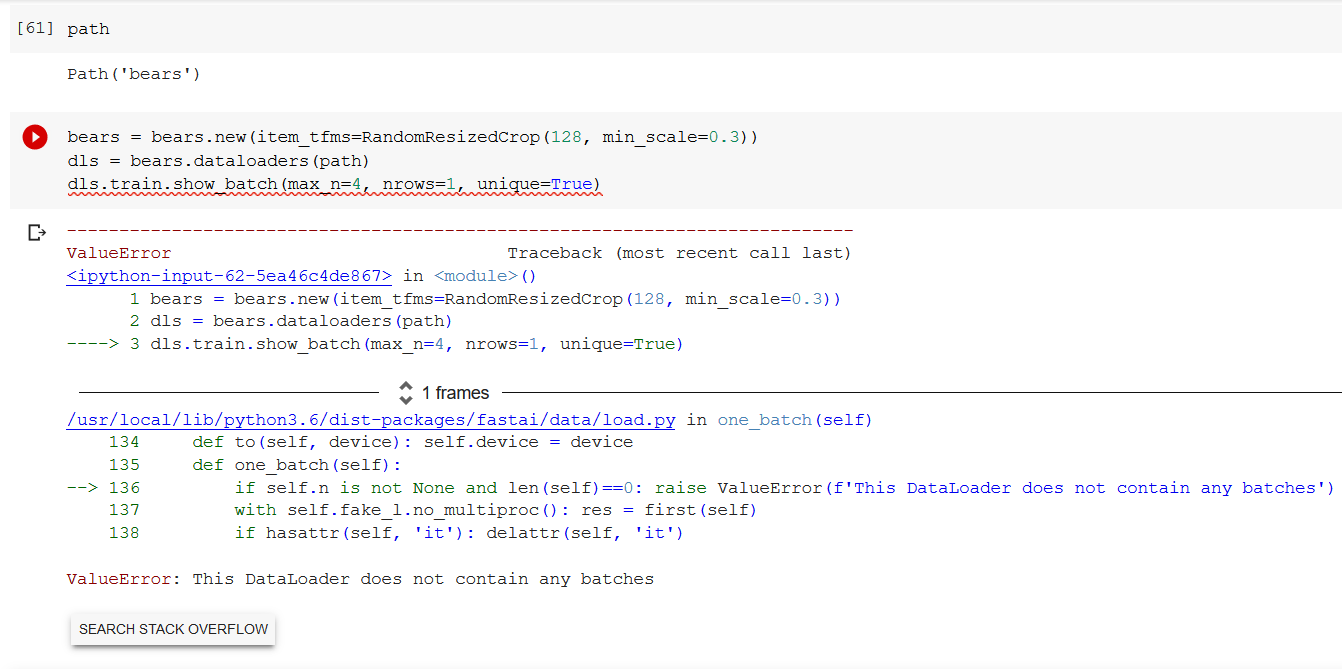
@sha52 Please review the code above. Try resetting your Kernel as well, the cell that you provided does not provide any information on your error. Please provide a code sample.
@Alignedmind I have tried resetting my kernel, resulted in no change of things, the error that I am facing, as mentioned in the screenshot is "The Dataloader does not contain any batches.
This is right above the data augmentation section, where we resize and pad zero the pictures, those two(resizing and padding) seemed to work just fine, except for this step. Hope this makes it a little clearer.
Here’s a working notebook based on the code that @klty0988 shared for the updated image search API:
https://github.com/Congitron/fastai-stuff
I’ve only tried this in Paperspace gradient, but it worked there.
The gist is just to create a new image search function:
def search_images_bing_2(subscription_key , search_term):
search_url = "https://api.bing.microsoft.com/v7.0/images/search"
headers = {"Ocp-Apim-Subscription-Key" : subscription_key}
params = {"q": search_term, "license": "public", "imageType": "photo", "count": "150"}
response = requests.get(search_url, headers=headers, params=params)
response.raise_for_status()
search_results = response.json()
return search_results
Then use it to get the URLs:
search_results = search_images_bing_2(key, 'grizzly bear')
img_urls = [img['contentUrl'] for img in search_results['value']]
or
if not path.exists():
path.mkdir()
for o in bear_types:
dest = (path/o)
dest.mkdir(exist_ok=True)
results = search_images_bing_2(key, f'{o} bear')
download_images(dest, urls=[img['contentUrl'] for img in results['value']])
6 Likes
Then if you want, to make this a little more wieldy:
def get_image_urls(search_results):
return [img['contentUrl'] for img in search_results['value']]
so it can be reduced to:
search_results = search_images_bing_2(key, 'grizzly bear')
img_urls = get_image_urls(search_results)
2 Likes
As another alternative, the cell below
- Fixes the existing issues with
search_images_bing - Is compatible with the rest of the notebook (e.g. it returns an
Land not alist, so it’s compatible with the variousattrgotcalls. - Doesn’t require an external library to be added
Simply copy this cell into your notebook, right underneath where search_images_bing is called. Hope this helps!
def search_images_bing(subscription_key, search_term, size = 150):
search_url = "https://api.bing.microsoft.com/v7.0/images/search"
headers = {"Ocp-Apim-Subscription-Key" : subscription_key}
params = {"q": search_term,
"license": "public",
"imageType": "photo",
"count": size}
response = requests.get(search_url, headers=headers, params=params)
response.raise_for_status()
search_results = response.json()
reformatted_results = L(search_results["value"], use_list=True)
# Uses the FastAI class L, a
# "drop-in" replacement for Lists. Mixes Python standard library and numpy arrays.
# I'm putting this here so, again, we minimize the amount of individual cells rewritten.
# Many of the later cells assume .attrgot is a valid thing you can call.
for result in reformatted_results:
result["content_url"] = result["contentUrl"]
# Bing changed their API. They return contentUrl instead of content_url.
# Again, this will help in the long run.
return reformatted_results
8 Likes
Thanks for this, curious thing though, this solution worked well for me the first time. So after a couple of days I decided to review the notebook by training a model on a different type of data, but the downloader keeps downloading irrelevant images. So much so, that I tried the bears again and got a bunch of irrelevant images in those too.
Is this an issue for any of you guys who implemented this solution as well?
Hi guys,
Can somebody tell me why this code is not doing what it is intended to do? Am getting an empty list when I run the next cell.
!pip install bing-image-downloader
from bing_image_downloader import downloader
import os
if not path.exists():
path.mkdir()
for o in bear_types:
dest = (path/o)
dest.mkdir(exist_ok=True)
#results = search_images_bing(key, f’{o} bear’)
#for count,list in enumerate(bear_types):
os.chdir(dest)
downloader.download(o,limit=50, output_dir=o, adult_filter_off=True, force_replace=False, timeout=60)
#download_images(dest, urls=results.attrgot(‘content_url’))
Am running this in Colab
Hi @russnagel1, did you solve this? @nn.Charles offers a good solution for this.
I noticed a typo in your code. You have a bracket ) where you typed:
!pip install bing)image_downloader
it needs to read:
!pip install bing-image-downloader
from bing_image_downloader import downloader
for q in [‘grizzly’, ‘black bear’, ‘teddy bear’]:
downloader.download(q, limit=20, output_dir=‘bears’, adult_filter_off=True, force_replace=False, timeout=5)
I hope this helps
1 Like
@Rxthew
Hey Richard, I hope all is well. The API work-around I know is not the best implementation to grab images. However there is a method listed in the course to remove unwanted images manually, or to swap images for their proper labels. In fast.ai you can use the ImageClassifierCleaner GUI.
1 Like
Thanks Jeremy, I’m just frustrated because it worked so well the first time. In fact, I let it go for a while and then I was about to try the more conventional methods, but I’m suddenly deep into the documentation of how this downloader works, and why it returns images that have nothing to do with my query. Probably an ill-advised detour, but there you go.
Thanks to everyone for the suggestions on this topic!
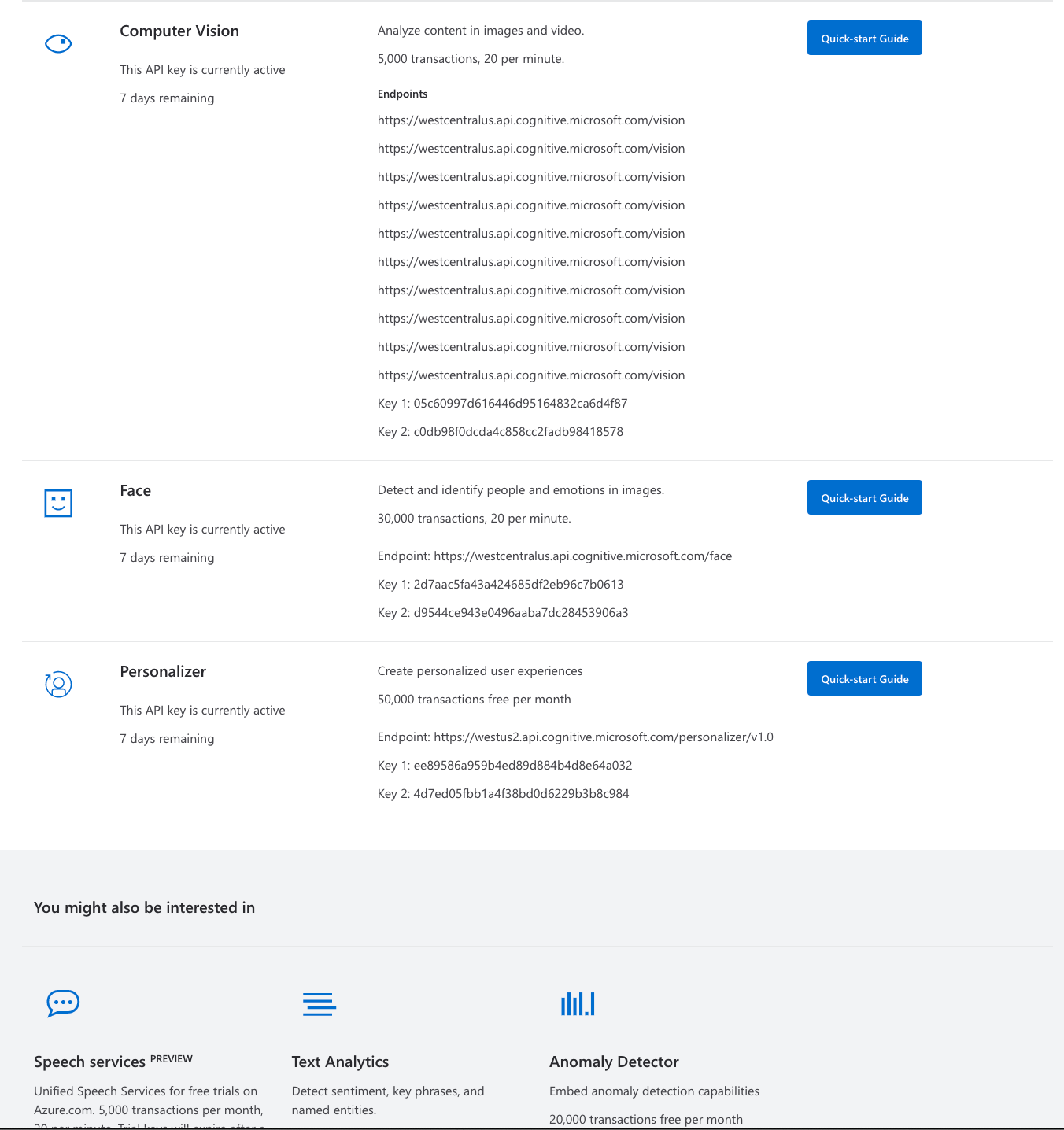
Hi guys, it is now 2 hours that I am trying to get the “right key” to start working, and I am still failing at it even following these instructions. The problem is the following: As you can see here (I hope the resolution is good enough), I don’t have the Bing Search API as option to be accessed. I tried several others (Computer vision, Face, Personalizer) but of course they are failing. Anyone having the same issue or having an idea on how to solve it? Many many thanks in advance!
NOTE: This is actually not working for me at the moment. It downloads images, but I just get multiple copies of very few images, and at least half do not contain what is being queried. If I can get it fixed, I’ll repost, but for now, I’m assuming that the Python module is simply flawed!!!
Please be sure to import downloader using this (not ‘import downloader’ as in one of the previous posts):
from bing_image_downloader import downloader
then download images using:
downloader.download(‘grizzly bear’, limit=100, output_dir=‘images’)
I haven’t yet incorporated the downloaded images into the jupyter notebook, so I can’t help there yet. Also, take the following into consideration:
-
The default limit is 100, but you may want to change that value. Other options, I’m good with defaulting. You should probably look at the docs for the module at https://pypi.org/project/bing-image-downloader/
-
A subfolder, named according to the search term, will automatically be created inside the directory that you specify.
-
If you search on the term “grizzly” rather than “grizzly bear”, you will get images that don’t even contain a bear. Whatever search term you use, you should browse through the images that you retrieve and delete any that don’t contain an image that you expect.
-
This is probably quite a bit slower than using an API key and the recommended libraries, but it is free and so far has worked for me. I probably wouldn’t use it for getting thousands of images.
-
I got this to work in a simple python shell - just enter the command ‘python’ in your shell. Then enter the commands above. No need to create an actual python program file.
1 Like
I am having the same issue…
I’ve been reading this topic and I followed @klty0988’s post. Thanks! It seems to be working.
I’ll leave my two cents for anyone coming after me, hopefully it will save time.
Unfortunately I can only put 2 urls and 1 image on my reply.
1.Register on Azure
1.1Google azure and click on Azure’s website
1.2Click the green “Start Free” button
1.3 Follow the registration process
2. Create a resource - Bing Search V7
2.1 Login to Azure Portal - Home: https://portal.azure.com/#home
2.2 Click “Create a resource”
2.3 on the search bar type “Bing Search V7”, click create
2.4 Fill in all fields and create - You have created a Container and BingSearch resource
3 - Get the Key
3.1 Go again to the link on point 2.1
3.2 Click on the bingsearch resource (you might have given it a different name when you created it)
3.3 On the left side panel, click keys and endpoints
3.4 And Key 1 will be the key to replace on the code
From here just follow the post @klty0988 did - Thanks Kenneth once again! =)
https://towardsdatascience.com/classifying-images-of-alcoholic-beverages-with-fast-ai-34c4560b5543
9 Likes
Thanks a lot!
This seemed to solve the issue for me. But then, down the road, when I run:
if not path.exists():
path.mkdir()
for o in bear_types:
dest = (path/o)
dest.mkdir(exist_ok=True)
results = search_images_bing(key, f’{o} bear’)
download_images(dest, urls=results.attrgot(‘content_url’))
I get an error at the download_images() line. The error is as the following. Any idea why the download_images() function is not working?
---------------------------------------------------------------------------
_RemoteTraceback Traceback (most recent call last)
_RemoteTraceback:
“”"
Traceback (most recent call last):
File “/opt/conda/envs/fastai/lib/python3.8/concurrent/futures/process.py”, line 239, in _process_worker
r = call_item.fn(*call_item.args, **call_item.kwargs)
File “/opt/conda/envs/fastai/lib/python3.8/concurrent/futures/process.py”, line 198, in _process_chunk
return [fn(*args) for args in chunk]
File “/opt/conda/envs/fastai/lib/python3.8/concurrent/futures/process.py”, line 198, in
return [fn(*args) for args in chunk]
File “/opt/conda/envs/fastai/lib/python3.8/site-packages/fastcore/xtras.py”, line 475, in _call
return g(item)
File “/opt/conda/envs/fastai/lib/python3.8/site-packages/fastai/vision/utils.py”, line 25, in _download_image_inner
url_path = Path(url)
File “/opt/conda/envs/fastai/lib/python3.8/pathlib.py”, line 1038, in new
self = cls._from_parts(args, init=False)
File “/opt/conda/envs/fastai/lib/python3.8/pathlib.py”, line 679, in _from_parts
drv, root, parts = self._parse_args(args)
File “/opt/conda/envs/fastai/lib/python3.8/pathlib.py”, line 663, in _parse_args
a = os.fspath(a)
TypeError: expected str, bytes or os.PathLike object, not NoneType
“”"
The above exception was the direct cause of the following exception:
TypeError Traceback (most recent call last)
in
5 dest.mkdir(exist_ok=True)
6 results = search_images_bing(key, f’{o} bear’)
----> 7 download_images(dest, urls=results.attrgot(‘content_url’))
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastai/vision/utils.py in download_images(dest, url_file, urls, max_pics, n_workers, timeout, preserve_filename)
35 dest = Path(dest)
36 dest.mkdir(exist_ok=True)
—> 37 parallel(partial(_download_image_inner, dest, timeout=timeout, preserve_filename=preserve_filename),
38 list(enumerate(urls)), n_workers=n_workers)
39
Hey folks, I ran into an issue getting the api key as well and so far this is what has worked for me.
- Make sure you have the azure account created
- go to Bing Search API Pricing | Microsoft Bing while logged in already
- click on try now and it should take you to where the resource can be created. which is this url: Create - Microsoft Azure
- create the resource and then click the “go to resource” button and the key is in the “keys and endpoints” section on the left hand side.
this worked for me. Hopefully it works for anyone else struggling with this until microsoft fixes the issue.
7 Likes