Tried several times to go through the lesson 3 imdb notebook but I’m hitting OOM errors even with a really small batch size.
data_lm = (TextFileList.from_folder(path)
#grab all the text files in path
.label_const(0)
#label them all wiht 0s (the targets aren't positive vs negative review here)
.split_by_folder(valid='test')
#split by folder between train and validation set
.datasets()
#use `TextDataset`, the flag `is_fnames=True` indicates to read the content of the files passed
.tokenize()
#tokenize with defaults from fastai
.numericalize()
#numericalize with defaults from fastai
.databunch(TextLMDataBunch, bs=8))
#use a TextLMDataBunch
data_lm.save('tmp_lm')
Do I need to set the batch size somewhere else or is there something else I’m missing?
I’ve been able to train with the defaults (bs=64, bptt=70) using the old fastai and the new fastai (as of a couple of weeks ago) so this really seems odd that even with a bs=4 I’m getting OOM errors.
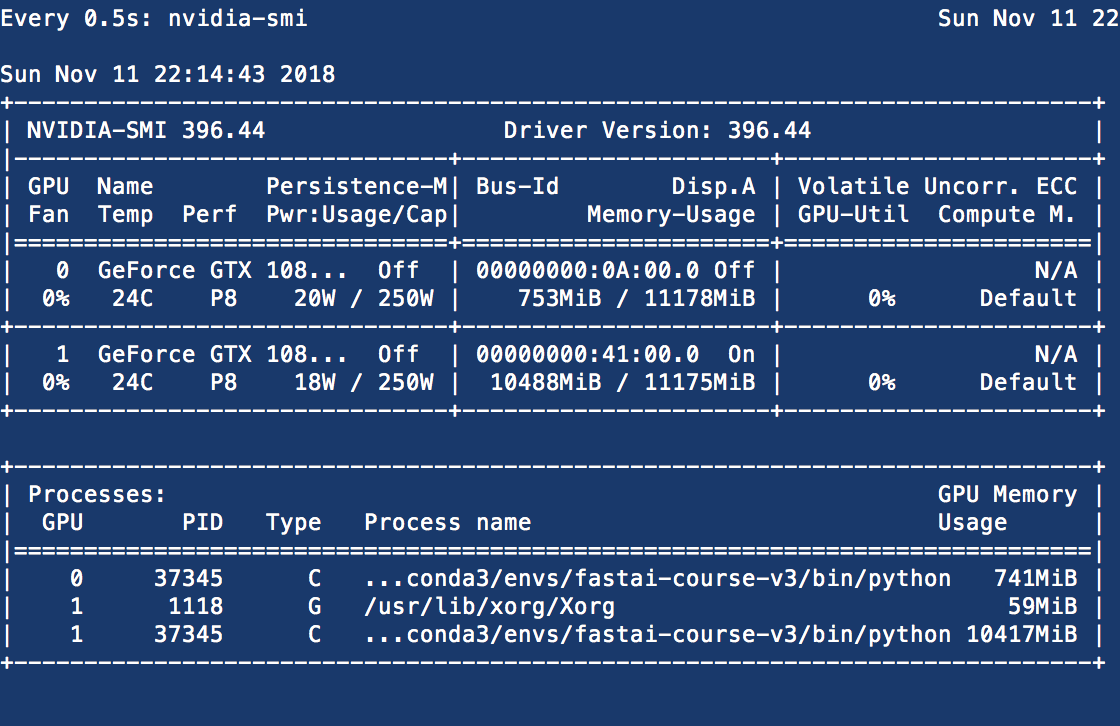
Another strange thing I just noticed, is that when I try to do my first fit via learn.fit_one_cycle(1, 1e-2, moms=(0.8,0.7)), another process spins up that is using my non-default GPU (which I set to 1). Its PID is 37345 in the screenshot below:
Like I said, I could build an LM no problem as of a couple of weeks ago with the defaults (which my GPU should be able to handle) … but no more. Been trying all day with smaller batch sizes and bptt. Not sure if it might be something in the latest production fastai v1 code or perhaps the latest pytorch build.
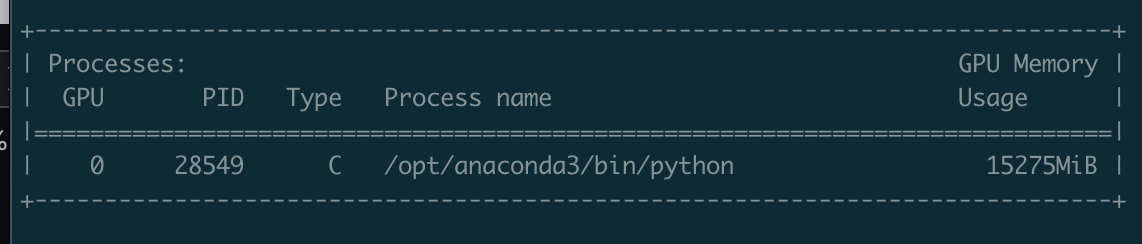
For me, I am using a P100 instance with a batch size of 64. Below is the screenshot of the GPU usage at the peak, which lasted for only several seconds.
Then it stayed near 10 GB. IMHB, a sudden surge of 5GB in GPU usage that lasted only such a short period of time looks a bit abnormal. It could also be the reason why you ran out of memory. Since later it stayed around 10GB, it probably has a cause other than the large batch size.
I am inclined to agree with you. I’ve seen this behavior before but I can’t remember what it was that caused it (was something with the data setup; like setting the LM targets to be equal the LM inputs or something like that).
Going to look at the text data block code this morning to see if I can find the source of all this … my spidey-senses tell me that is where the bug lies.
1. data_lm.save('tmp_lm') does not save data_lm … if ‘tmp_lm’ exists.
data_lm.save('tmp_lm') uses whatever is cached in there if it exists instead of overwriting it’s contents. Thus, if you run the lesson3-imdb code as is, it will always load whatever you used to build data_lm initially because of this line right before the learner:
You would need to delete the ‘tmp_lm’ folder each time you run the data block code (or skip the loading line) if you change anything in your data block code above it.
I’d recommend the save method be updated to include an overwrite flag : def save(..., overwrite=False)
If set to True, it would force saving whatever data is passed into regardless of the existence of the cache_key. Glad to submit a PR if you all would like else its a simple enough change anyone can make.
Currently, I’m able to train comfortably with a bs=50 (also adding clipping (clip=0.25). … but I still don’t know why GPU 0 is being used at all given that I’ve told pytorch to use device 1 at the top of the notebook. Curious thing also I just noticed is that the PID for the process training on device 0 is the same as device 1 (see screenshot above).
Also curious if there is a reason that the old LM could train at 64 but not the latest (I imagine the model might be beefier now than it was in old fastai???)
I saw this thread this morning and thought I’d give it a try when I got home as I have a similar setup.
The first thing I did was to update the fastai library which put it at 1.0.22 and then updated the repo, but it appears that the notebook is the same.
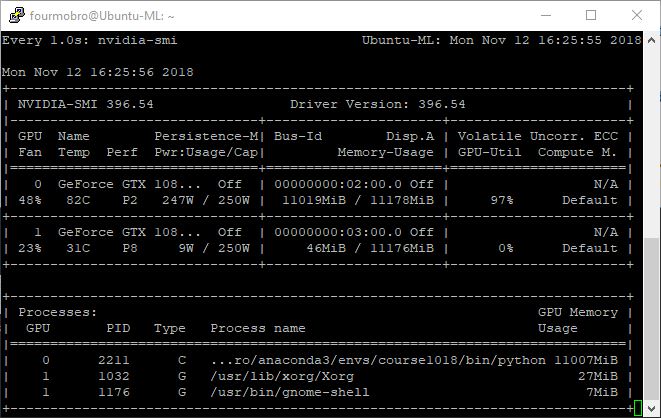
Running the code as-is showed that using the default batch size uses almost the entire realm of video ram as shown below.
The only significant difference that I see is that my driver is 396.54 as opposed to your 396.44. Running the fit_one_cycle completed without error as follows:
Looking ahead I could see that fine tuning was going to take 2hrs+ so I decided to go back and try to add the DataParallel portion to use both GPU, but that code failed right off the bat:
~/anaconda3/envs/course1018/lib/python3.6/site-packages/torch/nn/modules/module.py in __getattr__(self, name)
516 return modules[name]
517 raise AttributeError("'{}' object has no attribute '{}'".format(
--> 518 type(self).__name__, name))
519
520 def __setattr__(self, name, value):
AttributeError: 'DataParallel' object has no attribute 'reset'
So I went back and ran the code as it was for a single GPU, loading the saved weights from the first trial. I will update in a couple hours when it has finished.
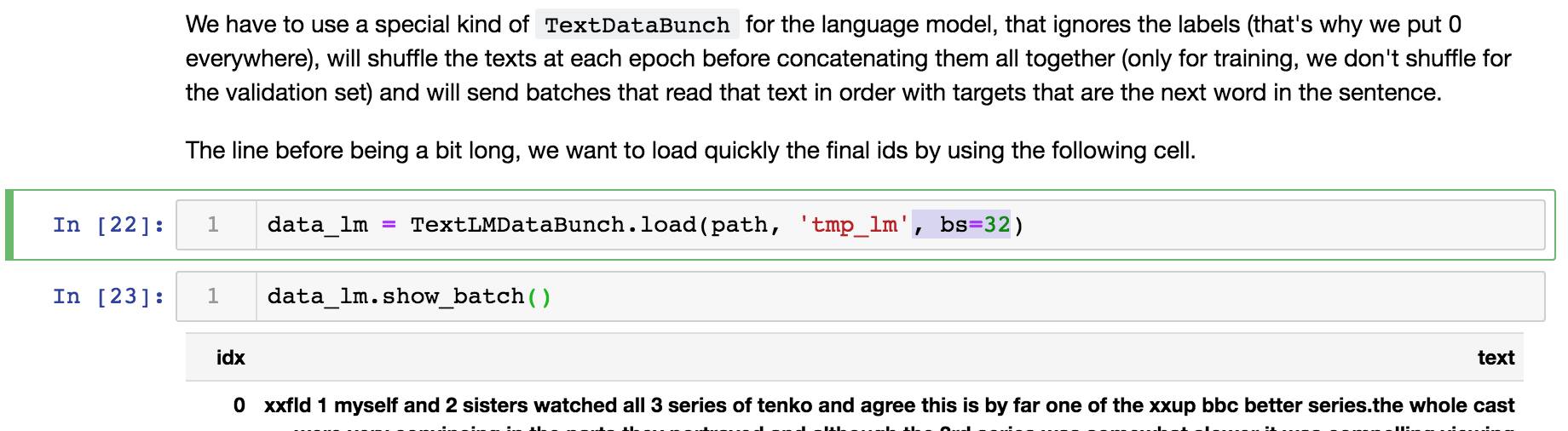
If you reload the data_lm (ie: after OOM error), you should specify new “bs” even in TextLMDataBunch.load function. Probably load function uses default bs (=64)…
To make it works in 8GB board I should add “bs=32”:
Between clearing the cuda cache, and setting the bs to 32 during the loads, I was able to get through the notebook. I did have nvidia-smi watching and still I noticed occasional spikes in vram during processing, sometimes within a few MB of max VRAM only for it to settle down in a comfortable range. So there is something else going on with the code or the drivers (396.54 on mine).
Hi - I have a 1050 Ti with 4GB dedicated GPU memory.
With bs=16 & “torch.cuda.empty_cache()” between every save/load I am able to get to unfreezing the last 2 layer. Training with unfreezing the last 3 layers throws GPU OOM.
Is there a way I can tweak further to be able to complete the exercise?
E.g. reduced batch size? or a simpler architecture? v2018 of the course had a bptt setting - and i see references to that in learner.py - is there a way i can set that while creating the learner?