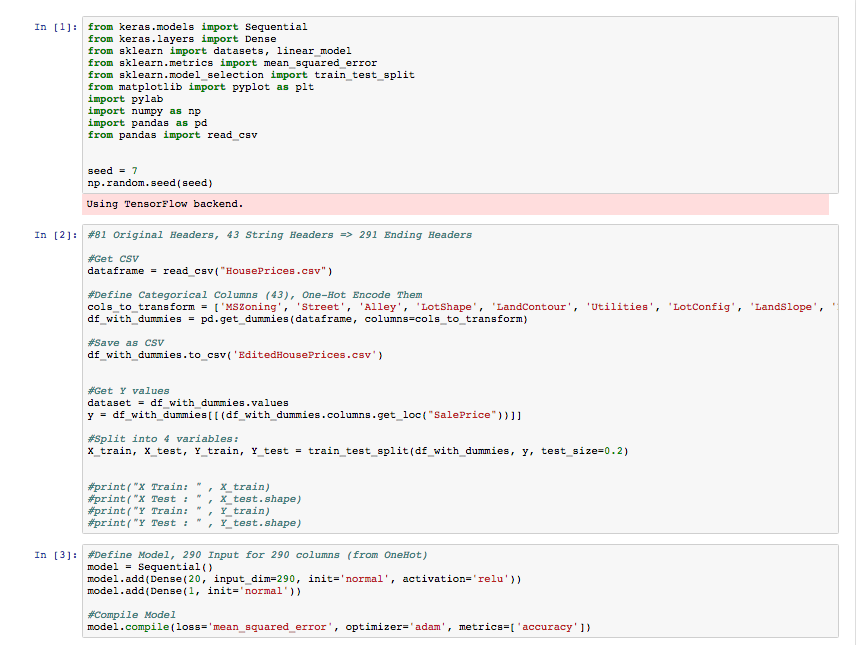
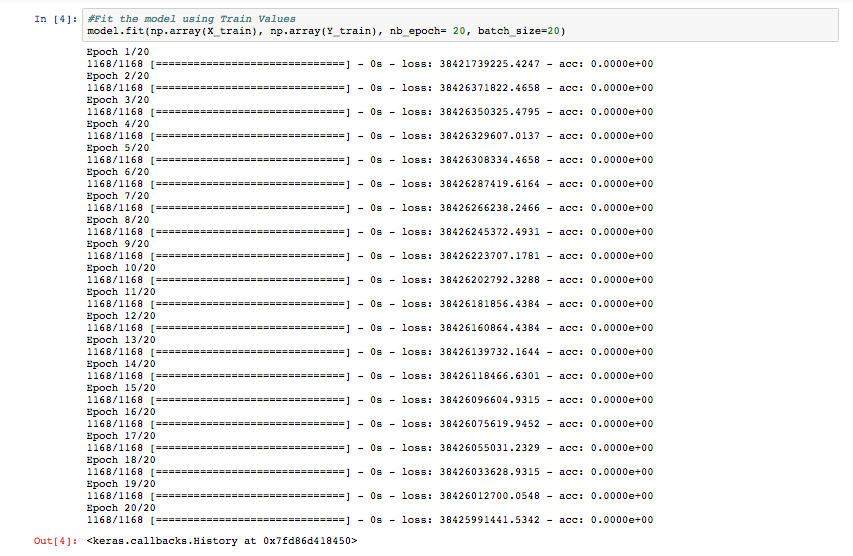
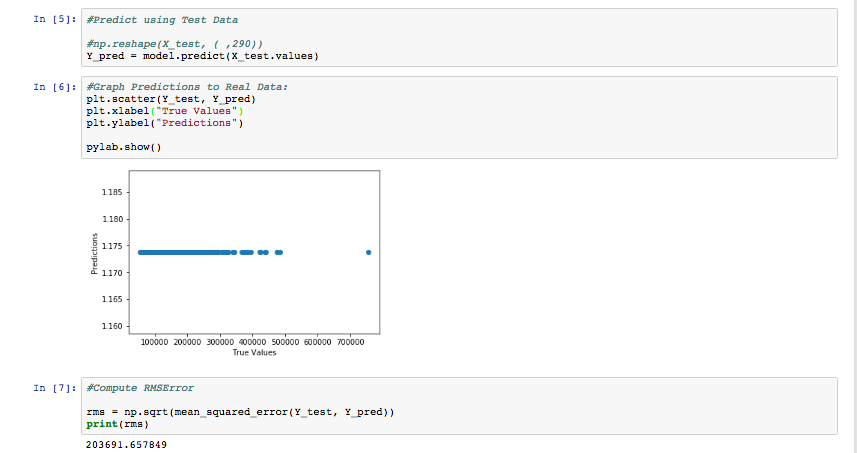
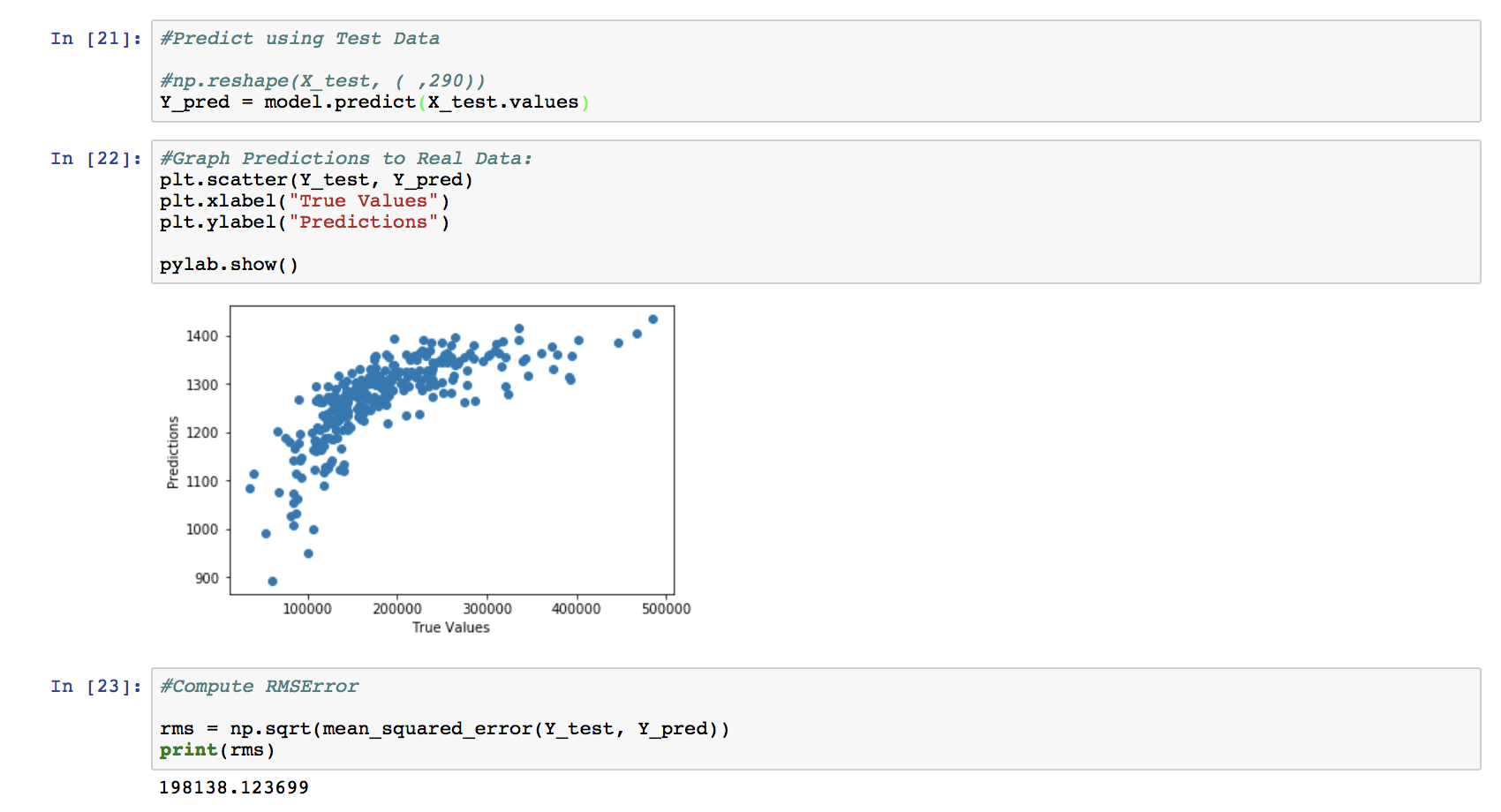
Hello all! I’m having a ever-persistant problem with the Kaggle Housing Competition. I use OneHot encoding (pd.get_dummies) to convert the data into all numbers. A CSV file of the converted data can be found below in the DropBox. However, upon using model.fit, I get 0% accuracy (image posted below). I then go on to doing predictions (Test), and the MatPlotLib graph indicates that my model is predicting the same number every time! Perhaps there is a problem with compatibility or something?
I am extremely grateful for any help - this problem has been plaguing me for about a month now! - all pictures and files (data/CSV/ipynb) can be found below!
HousePrices.csv - Original Data - Also available for download on Kaggle website
EditedHousePrices (1).csv - OneHot Encoded Data Made by Code
HousePrices.ipynb - Python Notebook of the Code
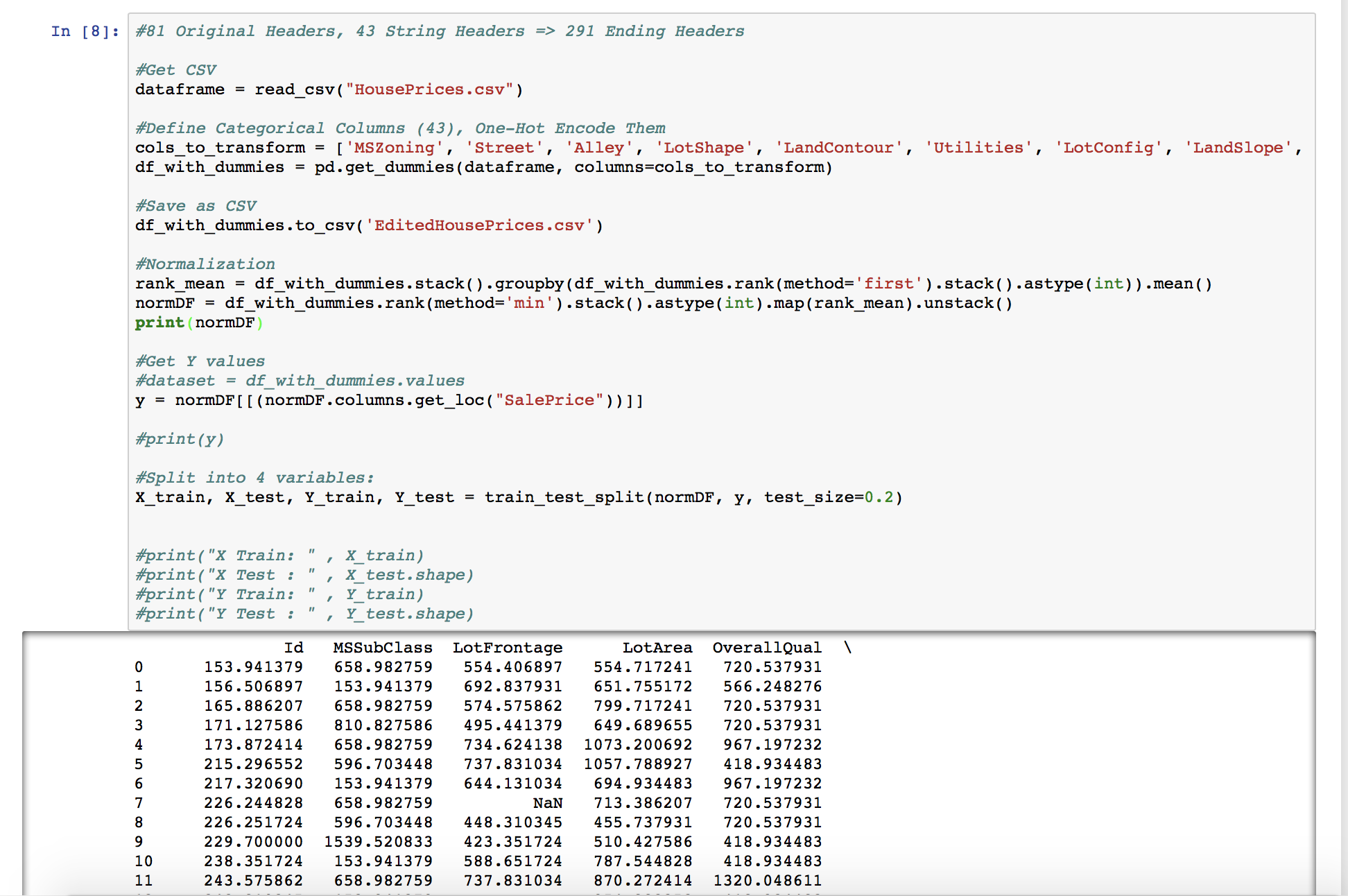
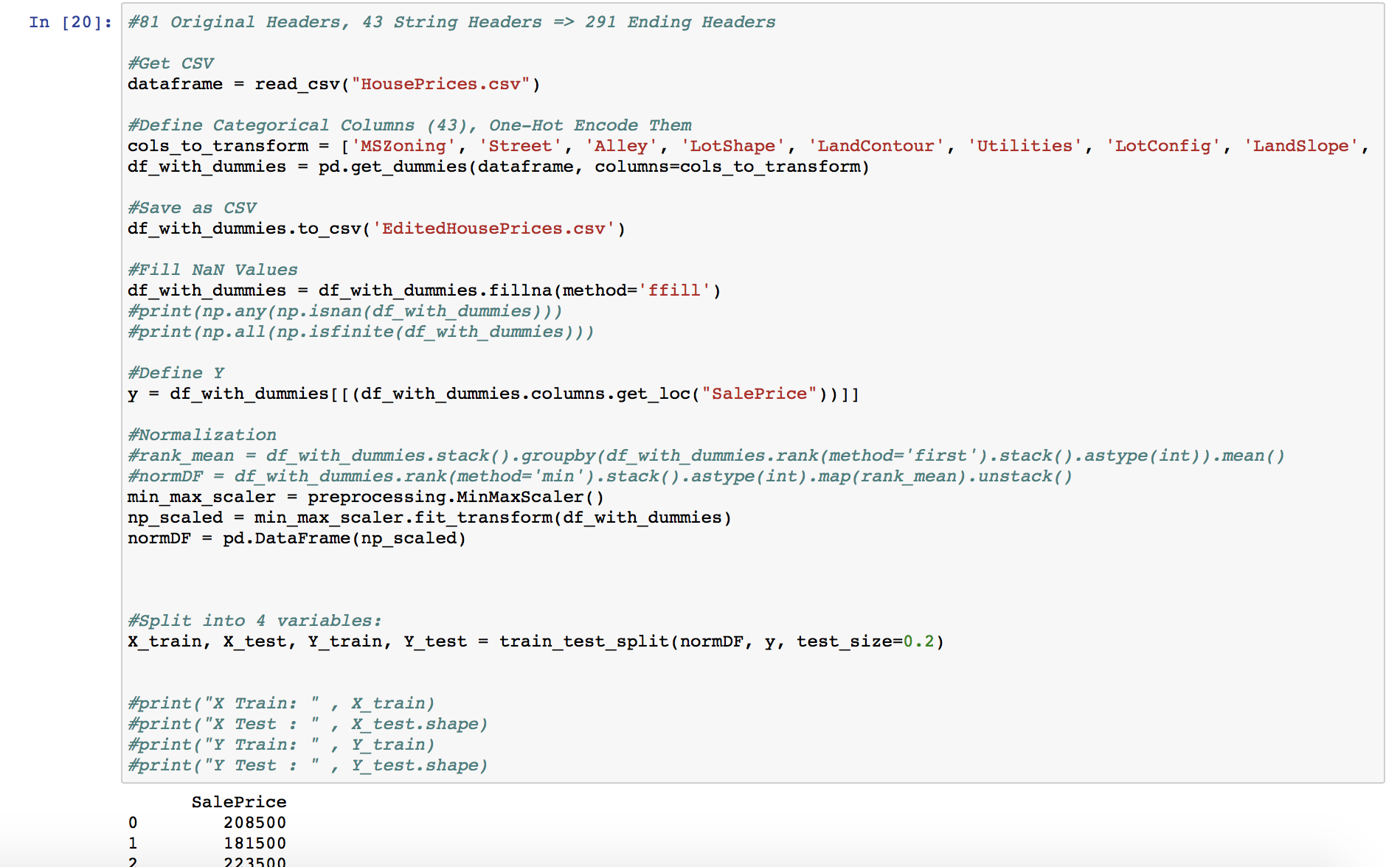
Further investigation shows that my deep learning data (EditedHousingPrices) has some infinite/nan values - print(np.all(np.isfinite(df_with_dummies))) returns false! np.isnan returns true!
How would I remove/edit these values? Wasn’t able to find much info regarding this.
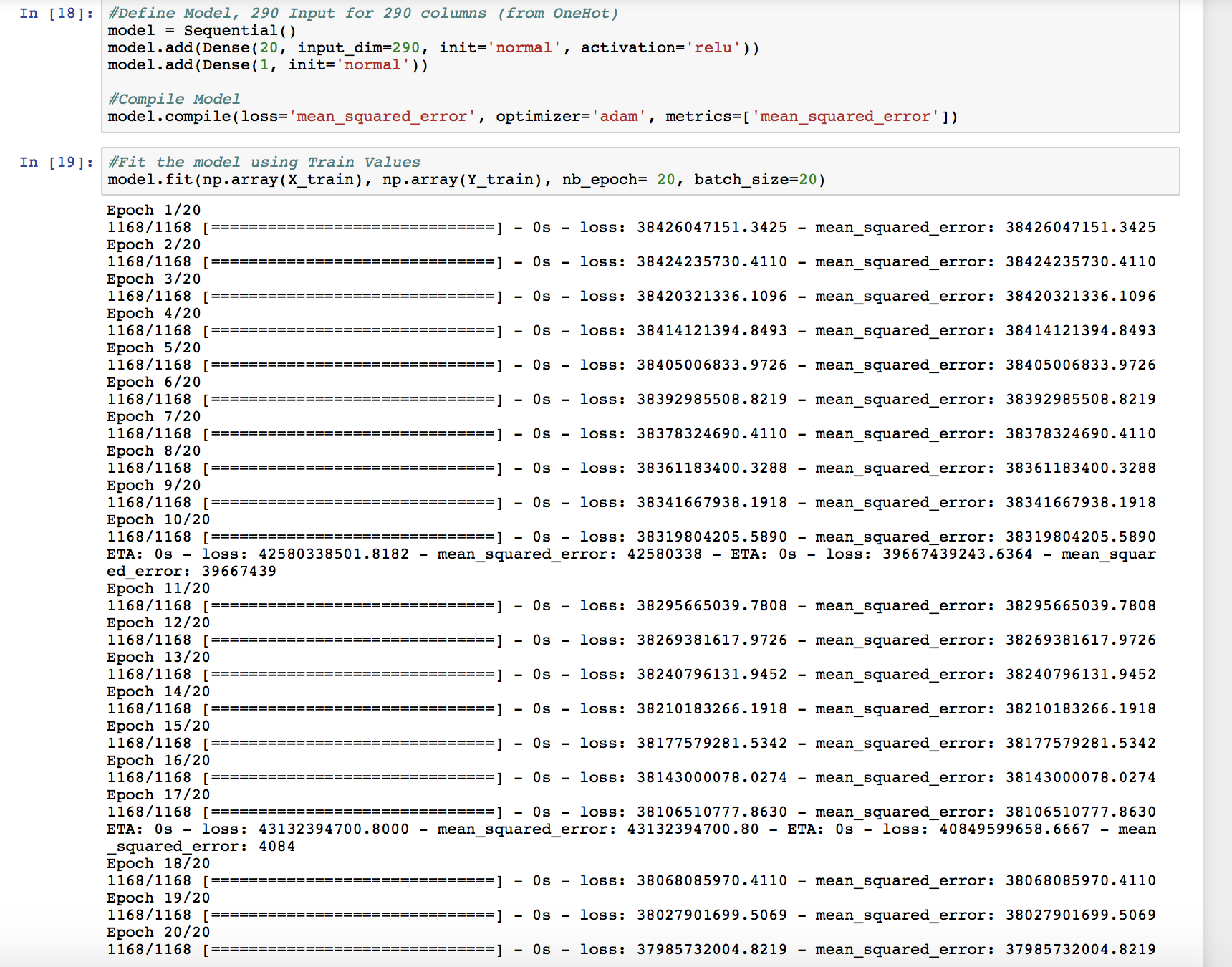
I’ve figured out how to replace the NaN/Infinite values. Training gives a ridiculously big loss/MSE of numbers around 38426047151.3425. Then test predictions give an RMS of 198,138. Which is terrible given that the home prices in the data are all around $200,000. Am I doing something wrong?
I’ve increased the Neurons in the first dense layer to 290 and increased the epochs to 300, which has gotten my RMS down to 25,000! Other than increasing epochs, are there any other things I can do to make my model better? e.g. Increasing the number of dense layers?