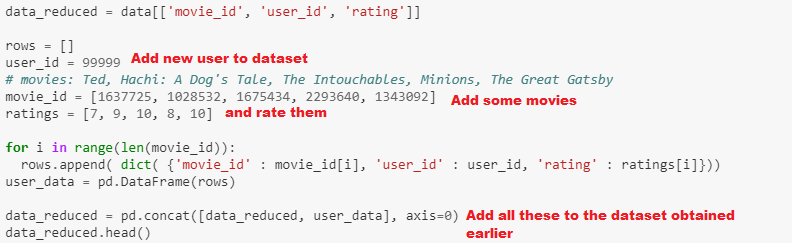
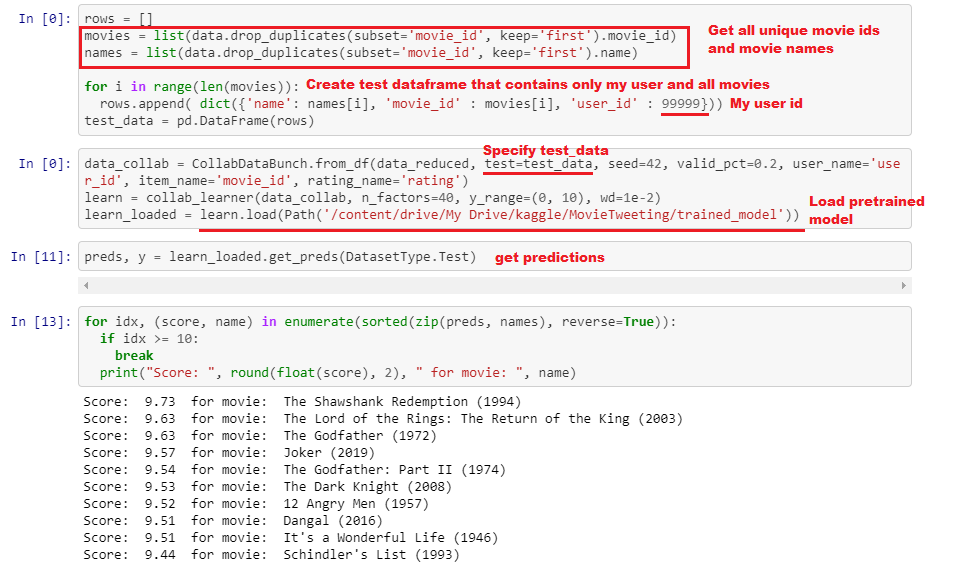
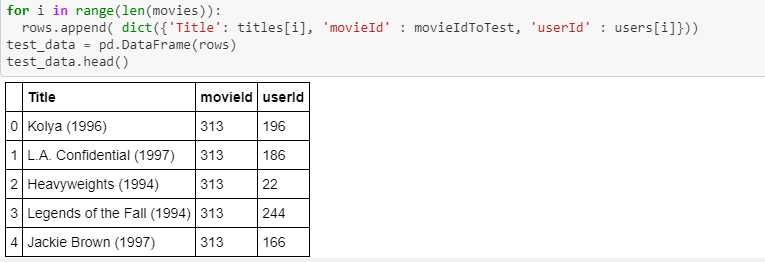
I want to build a little movie recommender system. The model works fine, but, then I`ve came up with the question: how do I predict with this model? My goal is to recommend the top 10 movies for a given user (user already presented in the dataset with 5-10 movie reviews).
I was not able to get_preds on test data using CollabDataBunch
gives me an error.
It is clearly that I`m doing smth wrong. How should I properly define the test dataset and predict it using a collab learner?
It is not feasible to retrain the model every time I want to make predictions. I was able to solve the problem by calling learn.predict() for each user_id - movie_id pair. But this is very slow and is not taking advantage of any type of parallelism.
How can I make fast predictions on large amount of data?
preds, y = learn_loaded.get_preds(DatasetType.Test)
As I understood we can use different test dataset when defining the CollabDataBunch and it will not cause any problem when loading model (seems logic, as model is not changed) trained before.
Hi @IRailean, i’m having the same requirement, also i’m fairly new to AI/ML domain, can you please tell me how you got it done?
Btw, i followed the code from https://jovian.ml/aakashns/movielens-fastai/v/14 for the movie recommendations. Now i’m trying to predict top 10 movies for any particular user.
Struggling since 2 days to get that done, any help will be highly appreciated.
Note: User for which you want to make predictions must be introduced in the dataset before training. Otherwise it will not have his embedding vector calculated (the same with movies).
Thanks a Lot @IRailean, my hearty thanks to you. You saved my day. I’ll take a look at the code and try to see how the predictions are. Once again thank you very much.
Hi @IRailean, how to test the model with the test data? We supply valid_pct=0.2 (20% of the data as test data) to CollabDataBunch.from_df?
How to grab a user from that 20% test data and test it against the trained model?
y_range specifies range of your scores. As I`ve seen you use 0-5 ratings, so change this to y_range=(0,5)
Do not forget also to load your model before predictions.
In your case smth like that:
learn1 = learn.load("trained_model')
valid_pct=0.2 shows how much of your initial data will be chosen as validation data.It means that from rating_movie dataset you use 20% as validation data.
Please, check out this video by Andrew Ng about train/dev/test distribution.
How to get that 20% data and test it? (i don’t know whether this question makes sense or not). In the past i have seen from other Neural Network tutorials where they train the NN with 80% of the data and remaining 20% they’ll test and validate the model. Similar to that is there a way to validate the model from that 20% test data?
Sorry, If this question isn’t relevant/doesn’t make sense please ignore.
You may not know from the start which architecture or hyperparameters will be the best choice for your NN. Therefore you often want to separate your data into 3 categories: train/val/test data.
Training data/Validation data.
NN uses training data to learn. Then you validate your NN on validation data.
If your metrics` values(accuracy, mse, rmse, etc.) are still not satisfactory, you may change hyperparameters or alter architecture of an NN.
Test data
Once you have found the best hyperparameters and architecture using train/val data, you evaluate your model on the test data. It is used as unbiased evaluation of a final model.
When creating databunch in fastai you just give it your data and this coefficient valid_pct which tells how much of this data will be used as validation set. It is up to fastai which entries of your data will be used as validation (I believe it does split data randomly).
Now it makes sense and i’m able to connect the dots. Thanks @IRailean for clearing my doubts. You mentioned the data is split into Training set and Validation set - how to validate the model with the Validation Data? Is there a way to extract the validation set?
fastai does this for you. Just specify how much data you want to use as validation data using valid_pct.
You can take a look at validation data in the following way:
data.valid_ds[0]
This will give you first entry of your validation data.
You have built a test dataset, where it is only 1 movieId and all users. From this dataset, you will predict how each user would rate this movie (313).
Regarding your question:
You want to find similar movies. As for each movie you have an embedding vector that represents this movie, for a given movie you want top-10 similar movies, when similar means with the
nearest embedding vector.
For this, you can retrieve weights and biases for each movie, calculate the distance between your movie and each movie in the dataset, and then sort them. Here is told how to get bias and weight for a given movie.
Sorry my bad on using movieId wrongly.
I made some changes to my code -https://github.com/jaganlal/NCFMovie100k/blob/master/NCFMovie100K.ipynb to extract bias and weights for movieId. Trying to find top 10 recommendations for a movie given its id. Is there any direct way to supply the movieId and get the bias and weights for that movie (i mean top recommendations)?
To be honest, I do not understand what do you mean by “Trying to find top 10 recommendations for a movie given its id”. You want to find 10 users that would rate this movie with the highest rating or top-10 similar movies to a given one?