I would like to team, I am currently implementing a simple fastai solution to start.
1 Like
Has anyone worked with planet labs data? They have an Open California https://www.planet.com/products/open-california/ dataset which allows access to daily imagery for the entire state of California with varying resolutions. They also have notebooks https://github.com/planetlabs/notebooks/tree/master/jupyter-notebooks on how to use their data with an awesome API (IMO  ). Also, if you are a student/faculty member, you may request access here https://www.planet.com/markets/education-and-research/ and that will give you the world(literally - daily imagery of the entire planet).
). Also, if you are a student/faculty member, you may request access here https://www.planet.com/markets/education-and-research/ and that will give you the world(literally - daily imagery of the entire planet).
Here are a couple of papers I have been reading recently and intend to begin implementing sometime this week, so let me know if anyone would like to collaborate and potentially create useful datasets and brainstorm applications using planet data.
https://research.fb.com/wp-content/uploads/2016/12/feeback-neural-network.pdf? : This paper is proposing a new segmentation architecture(feedback neural nets) and the results look quite a lot better than the previous SOTA(U-nets). Might also be interesting to compare the new architecture to Tiramisu as well(https://arxiv.org/pdf/1611.09326.pdf)
There is also this recent work out of Stefano Ermon’s group at Stanford who applied the “Distribution Hypothesis” from NLP to come up with representations analogous to word2vec for satellite imagery. They call it Tile2Vec and they claim to achieve representations that “achieve performance comparable to fully supervised CNNs trained on 50k+ labeled examples on a difficult land cover classification task.” (https://ermongroup.github.io/blog/tile2vec/#mikolov2013efficient)
Also, thanks for starting this thread @daveluo. Glad folks from the geospatial community are interested in leveraging fastai.
Finally, I am based out of Seattle, so if there are folks from the area interested in hack/brainstorming/geospatial nerding out sessions, I would totally be down
12 Likes
Interesting that Tile2Vec work. It’s the same methodology that can be used for person re-identification and image retrieval with TripletLoss to learn and embedding representation. And one of the components of the recent 1st place solution of Human Protein Atlas competition (I don’t know if triplet loss was used but the idea is the same, finding similar images). Also being used by some people in the current Whales Identification competition.
I think it’s amazing that the same idea can be used in so many different contexts to provide new insights. That’s the beauty of deep learning
5 Likes
thanks for sharing that! @mnpinto
Posting for a different cause.
DataKind is looking for volunteers with experience in managing and manipulating drone/satellite imagery data sets for the following project:
Develop building footprint segmentation models using high quality drone imagery for regions of Dar es Salaam, identify changes in the buildings present in imagery over time, display those changes for stakeholders, and produce a production ready data processing and inference pipeline.
Please check the announcement here : https://twitter.com/DataKind/status/1093990144984662016
6 Likes
I am interested, I am actually working with drone imagery right now, to segment photovoltaic modules.
Hi all, Esri - the world leader in mapping and geospatial analysis, is starting a new R&D center in New Delhi, focussed on Geospatial deep learning!
We’re looking for fast.ai alums to work as data scientists, developers and product engineers. See https://newdelhi.esri.com for open positions, learn more, apply online and see examples of what we’re working on. Feel free to contact me if you have any questions… Thanks!
Rohit
5 Likes
Great ! Please refer to the tweet and fill up the form mentioned there.
You were right! WiDS Datathon 2019 was an accessible competition with excellent results from models trained for just a few minutes on a single GPU. It is a shame that there was no location data to analyse which means, to my mind, it is not really geospatial, just image classification.
I’m thrilled that using just the content of the first three lessons of this course gave us second place. 
4 Likes
Congratulations @AlisonDavey for the second prize. That was indeed an accessible competition. Not at all intimidating like huge datasets in other competitions with less noise and I really enjoyed it. We also had third place although nothing particular to geospatial domain experience, the fastai lessons were the learning and inspiration sources. Congratulations.
3 Likes
Congratulations to you too  . A difference of .00001 between 2nd and 3rd is just noise. I wholly endorse your thanks to fastai.
. A difference of .00001 between 2nd and 3rd is just noise. I wholly endorse your thanks to fastai.
2 Likes
I’m exploring solar panel detection as well I’d love to hear your approach.
1 Like
I am working with solar panel segmentation. Detecting modules an segmenting the cells form the frame.
1 Like
@tcapelle and @Ljsweeny you should both checkout the Locate solar panels section of Open Climate Fix. It’s a collaborative effort to reduce climate emissions, and identifying solar panels from satellite data is a key problem to solve.
3 Likes
Hi everybody, awesome to see this group! * bookmarks *
I usually work with GIS within urban planning for the city of Helsingborg. So far I tried some image segmentation - basically replacing the images in the camvid exercise with aerial photography and trying to find buildings and roads. I used vector data to create masks with the ETL-software FME.
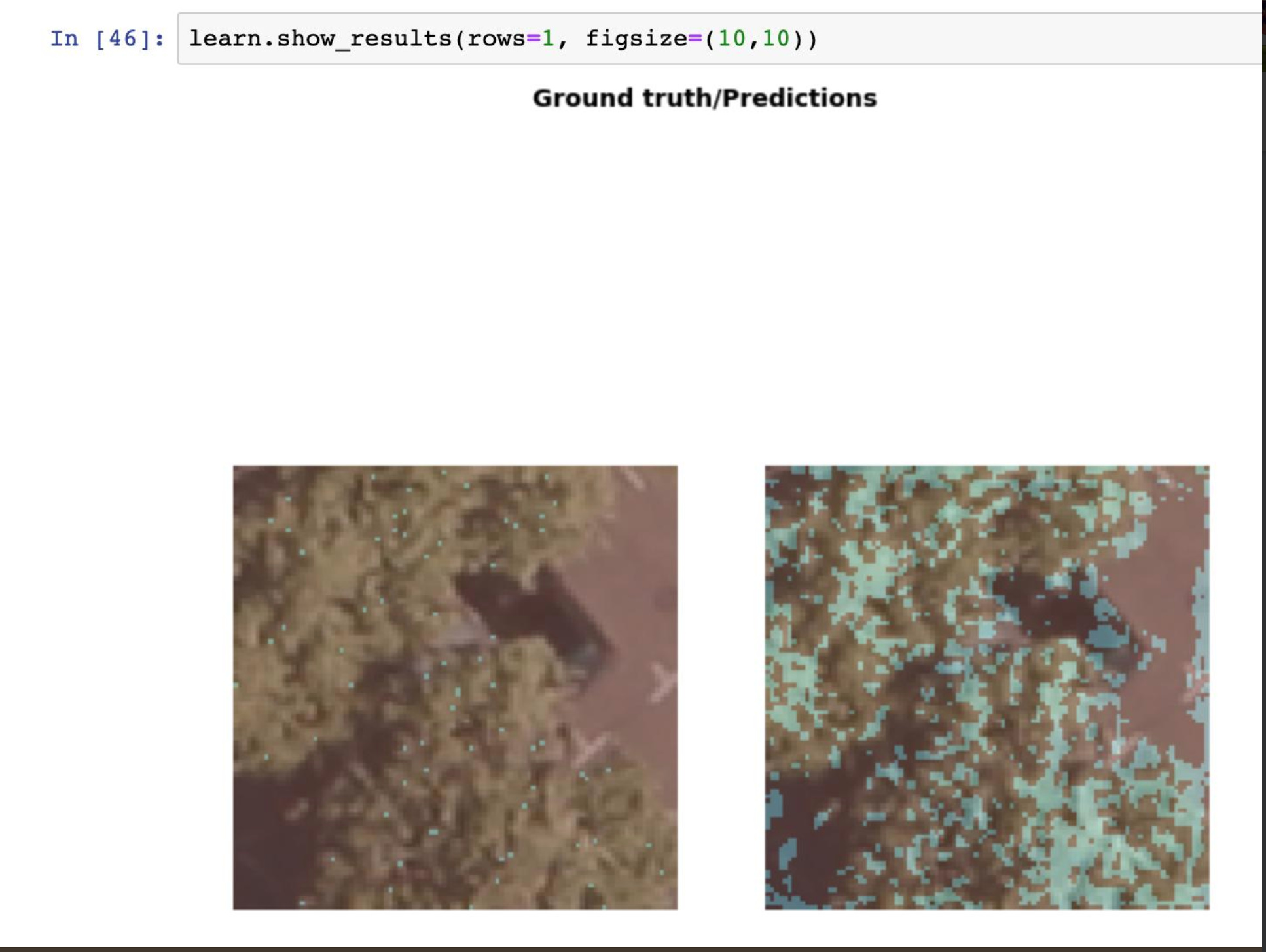
Horrible accuracy - 45% for three classes [Building, Road, Vegetation] I suspect due to ambiguous training data (parking lots marked as vegetation etc…) Anyways, it was a fun exercise!
1 Like
Hi, my name is Tom, work as a software engineer in Slovakia and data science enthusiast in free time, mostly engaged with databases(all kinds) and geoprocessing at the moment.
This forum is a great idea, I would definitely like to be involved… I am currently solving this one - is there a way how to process small tiles of huge satellite image into CNN fastai training without copying them manually(ie. output from Google earth engine)? Would cloud optimized geotiff work?
Thanks for any hints.
1 Like
Facebook has just published a building detection dataset at 30x30m scale for all of Africa.
Resulting data:
https://data.humdata.org/dataset/high-resolution-settlement-layer
Not a lot of technical detail in that post, but does at least touch on their approach, namely that they used a Resnet18 arch to do binary classification:
In the case of Africa, the process is reduced to classifying 11.5 billion 64x64-pixel images. While this is a large number, the infrastructure at Facebook — in particular, FBLearner and Presto’s Geospatial operations — made this practical. After switching to this classification approach and training a ResNet18 on around 1 million images, we significantly improved results in 66 of the 73 regions that we used both approaches on, with the average F1 score increasing from .818 to .907.
I’m impressed by the scale but a little worried about the implications. If this dataset is supposed to be used by NGOs for asset allocation or disaster relief prioritisation then I’d want them to be a lot better than 90% accurate. How many homes is 10% of the whole continent? And I’d love to know more about the “regional” differences. Is it better in urban or rural ares? Desert or jungle climates? Imagine if aid didn’t get allocated to a flooded region because FB’s classification didn’t work well on thatched homes, so NGOs didn’t believe they exist. Hopefully there’s plenty of ground truth effort and care going in to validation. I’m sure their heart is in the right place and it does sound like they’re working with ground truth teams. Interesting stuff and a little scary.
4 Likes
Hello, I am working on segmentation model for classifying basic land cover types from aerial imagery and I’m facing several challenges that I hope to get some advice on.
Background
- I am using a unet learner with resnet 34 (For no particular reason other than it was the example shown for segmentation classification)
- I am trying to do a basic land cover classification (developed, field/crop, wooded, water) plus a special case, driftwood/woody debris (WD).
- I have been using labelbox to create my training set
Questions
- Is there a way to indicate ‘no data’ for regions in my training masks? I have some regions that are unclassified in the training data and I have set the weight of the ‘no data’ class to 0 in my accuracy formula, but the learner is categorizing some output as unclassified.
- Does anyone have any recommendations for labeling training data for segmentation? All of the free tools out there seem to focus on boxes or polygons, but when trying to work quickly it’s hard to make the polygons line up exactly, creating unclassified areas.
- My initial run with a few hundred samples looks good, and the predictions are even better than my training data for delineating edges. I’d like to export the predictions, make some minor edits, then use the refined training data for future training. Is there a free tool somewhere that is capable of this? Right now it seems like this is going to be very laborious, converting predictions to png, then converting png to some sort of paletted image, manually opening the mask image and the underlying image in a photo editor, and then using a paintbrush to correct details of the mask. There’s got to be a better way.
- My special class, WD, is very small, so the learner appears to be ignoring it. If 2% of an image is of that class and 98% is wooded, the learner outputs 100% wooded and gets a 98% score. I’m planning on turning up the weight of finding this class, like 50% of the accuracy score will be getting the WD class correct, and the rest will be all other classes. Is there a recommended way I should do this, or just scale up the value of the WD class?
- A general question about classifiers, will features outside of the bounding box influence the identification of an object? In my imagery, trees cast noticable shadows, but the shadows are cast onto fields. If the mask is of the tree, but not the shadowed area, will the learner infer that something next to the object is an indicator that the object is present?
5 Likes
I’m lost. As in say 10,000 feet in the air somewhere over land. Where am I?
Okay, we can restrict this to say mainland Europe. I have all the satellite imagery I need.
The ‘typical’ way to address this, I claim is to convert everything to feature space (e.g., corners) and then search the world using a sliding window approach. The best match is where you’re at.
What if we trained a CNN on patches of satellite imagery covering the broad space, each mapped to the lat/long of the center of each patch. (And oriented north to limit the challenge.) . The target image, which is smaller than a patch is then tested against the CNN - hopefully providing a lat/long as an answer.
Alternatively/similarly, treat this as a classification problem where there are N patches (say N=1000) and the CNN is trained for each patch that it shows up in that class. This would at least simplify the problem. This might also work well for multiple altitudes - both of the imagery and the target…
Thoughts? Thanks!
1 Like
A colleague who works in climate modeling recently asked if it is possible to replace a physics model with a deep learning model. So, for example the input would be an image like this one:
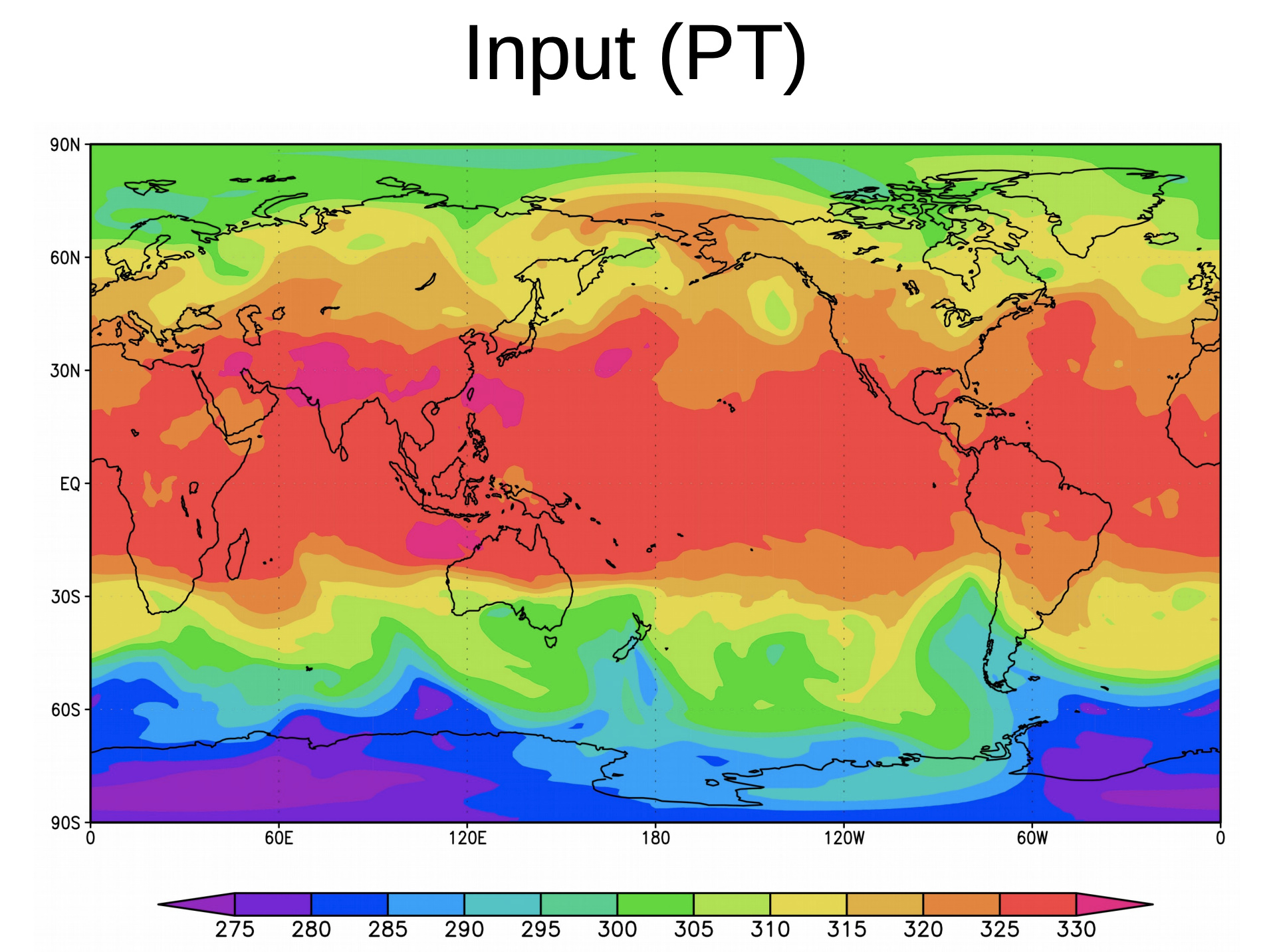
and the output would be an image like this one:
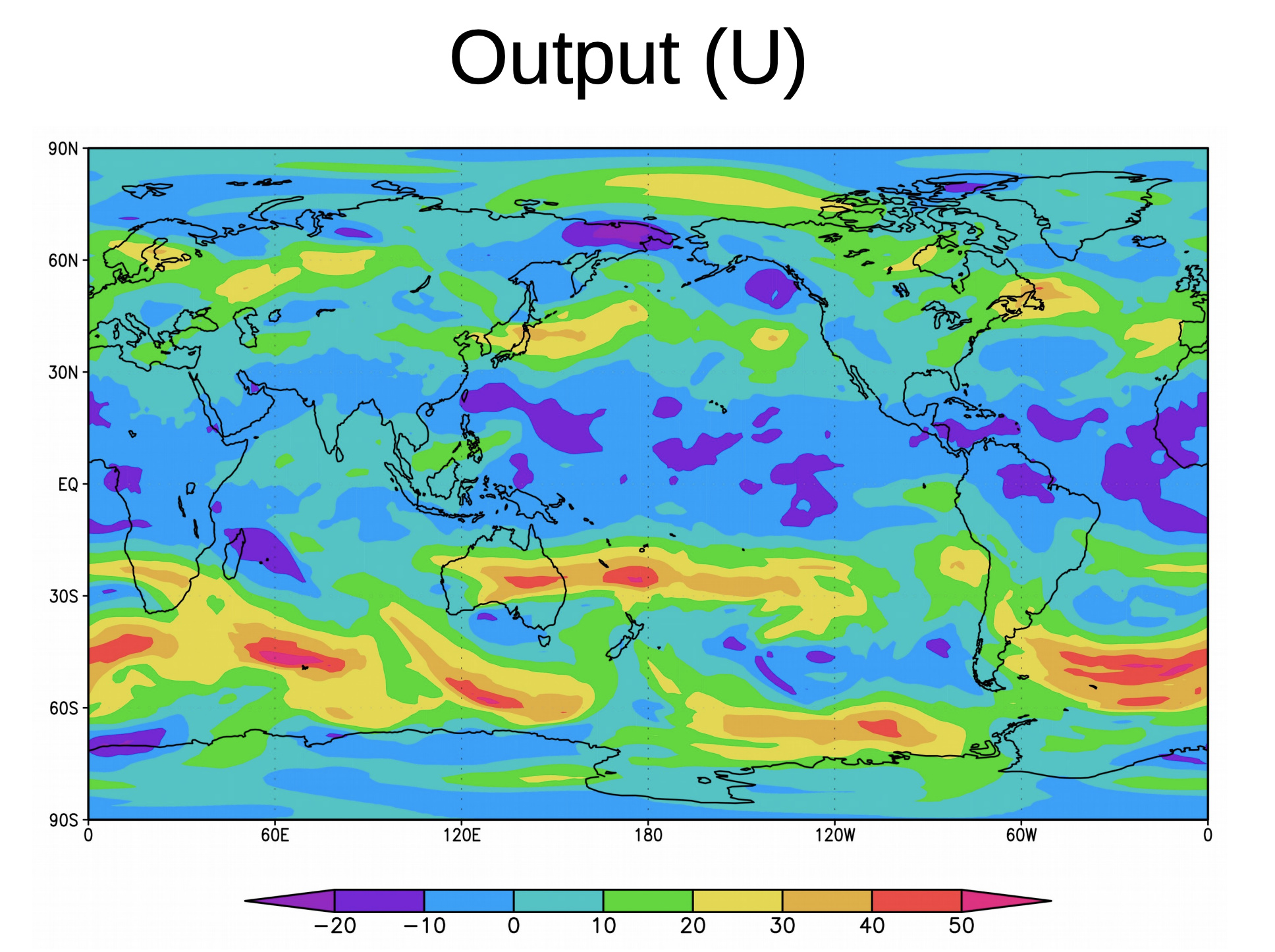
These are the kind of data that one finds on Google Earth Engine. Does anyone know if this sort of thing is at all solvable using deep learning techniques? I’m guessing that seeing that the output is an image, some sort of generative model is required. Any pointers will be much appreciated.
1 Like