Please refer to the Lesson 2 thread
If you specified a test directory path when creating your ImageDataBunch you can call get_preds and specify is_test=True as in:
learn.get_preds(is_test=True)
4 Likes
Thanks, let me try that.
I added the test data to the data bunch using the data block API: .databunch(test=“test”).
Then I got predictions using: multi_label_classification_predictions,target_values = learn.TTA()
1 Like
Even better! Don’t forget to flag is_test=True in TTA.
1 Like
When I do: multi_label_classification_predictions,target_values = learn.TTA(is_test=True), it throws an error: TypeError: object of type ‘NoneType’ has no len()
Can you explain how you created your ImageDataBunch object?
Here’s my code
np.random.seed()
data = (ImageFileList.from_folder(path)
.label_from_csv(‘train.csv’, sep=’ ‘, folder=‘train’, suffix=’.jpg’)
.random_split_by_pct(0.2)
.datasets(ImageMultiDataset)
.transform(tfms, size=224)
.databunch(test=“test”)
.normalize(imagenet_stats))
1 Like
Try creating a DataBunch object by using:
ImageDataBunch.from_csv
I think it will help you do this much easier.
Remember to send the fn_col and label_col arguments to tell your object in which columns of the csv it can find filenames and labels, the label_delim argument to tell it how labels are delimited in your csv, and suffix to be able to find the images in the path.
Please let me know if you get stuck.
1 Like
Okay, I’ll try that. Thanks
1 Like
Can the “from_csv” dataloader have an optional column in the csv file to specify which files are in the training set and which are in the validation set? That would help when you have separate images derived from the same object (you would want to keep them as a group in either the training or validation group).
Not currently no. The .from_csv method currently only supports creating a random validation set.
This error comes when there is an outdated or no c++ complier on the system. The work around would be to either update visual studio or install the latest version of visual studio code on your computer. The first answer for the question may be helpful for your reference: https://stackoverflow.com/questions/48541801/microsoft-visual-c-14-0-is-required-get-it-with-microsoft-visual-c-build-t
How to use ReduceLROnPlateau Callback ? Do we pass on like metrics or call on learn ? It’s not mentioned in docs yet.

Does someone have a good way to preserve a notebook’s cell output? I really like Jeremy’s experimentation approach and do it a lot. I copy cells, change something, then run to compare to the previous output. I generally comment out the code in the old cell to avoid accidentally rerunning it. Here’s a simple example:
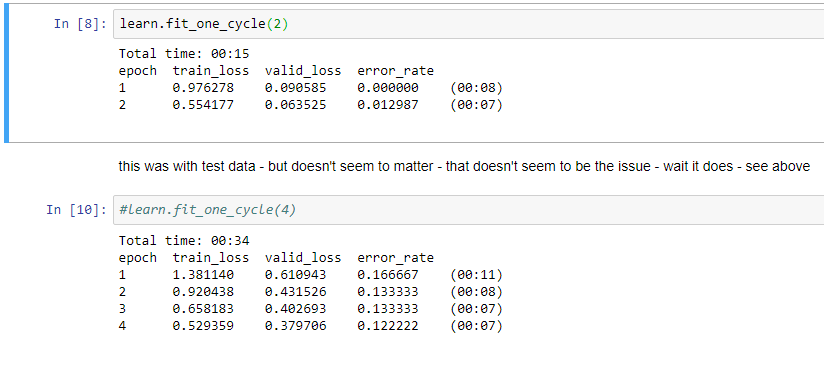
I find it very helpful to be able to compare several different runs. But sometimes I accidentally hit shift-enter in a commented cell and it erases the output.
I’m guessing somebody in the fastai community has figured out some clever way to preserve cell output until you no longer need it!
I have seen some approaches to saving nb state, large file outputs, etc., but this would be a way to just save cell output one at a time.
2 Likes
8 minutes later - duh…
Ok it’s pretty easy to just copy the cell output, change the cell to markdown, then paste the output in after the code:
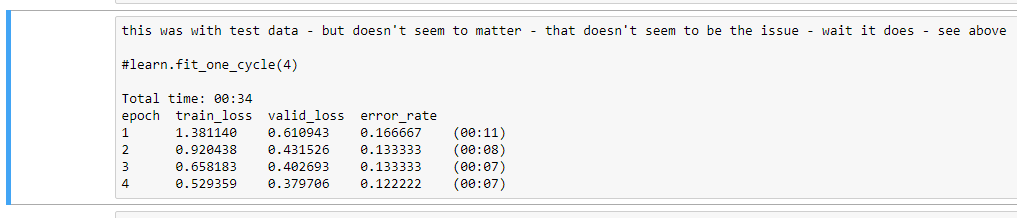
But if anyone has a smoother way I’d love to hear it!
3 Likes
Could you please tell about using custom models from either torchvision or custom with create_cnn ? create_body by default passes pretrained bool value (resnet in fastai for instance take (pretrained,**kwargs) but other models expect (input,**kwargs) input tensor to be passed. I also discussed this earlier ,here
1 Like
If you want to use your custom model, you can’t use create_cnn, you have to create your learner with learn = Learner(data, model).
5 Likes
When I run git pull, I get the following error:
error: cannot open .git/FETCH_HEAD: Read-only file system
I tried to modify the FETCH_HEAD file permissions by
sudo chmod a+rw .git/FETCH_HEAD
It says it changed permissions (changing permissions of ‘.git/FETCH_HEAD’: Read-only file system) but it still is read only. What am I missing. My UNIX is rusty to say the least…
Running on my own linux laptop with GPU is case that is helpful.
Sorry if this is a repeat somewhere but I really could not find a good solution to this
Pete
How can I train resnet34 model on svg images. Do I need to convert those to jpeg or not?
1 Like