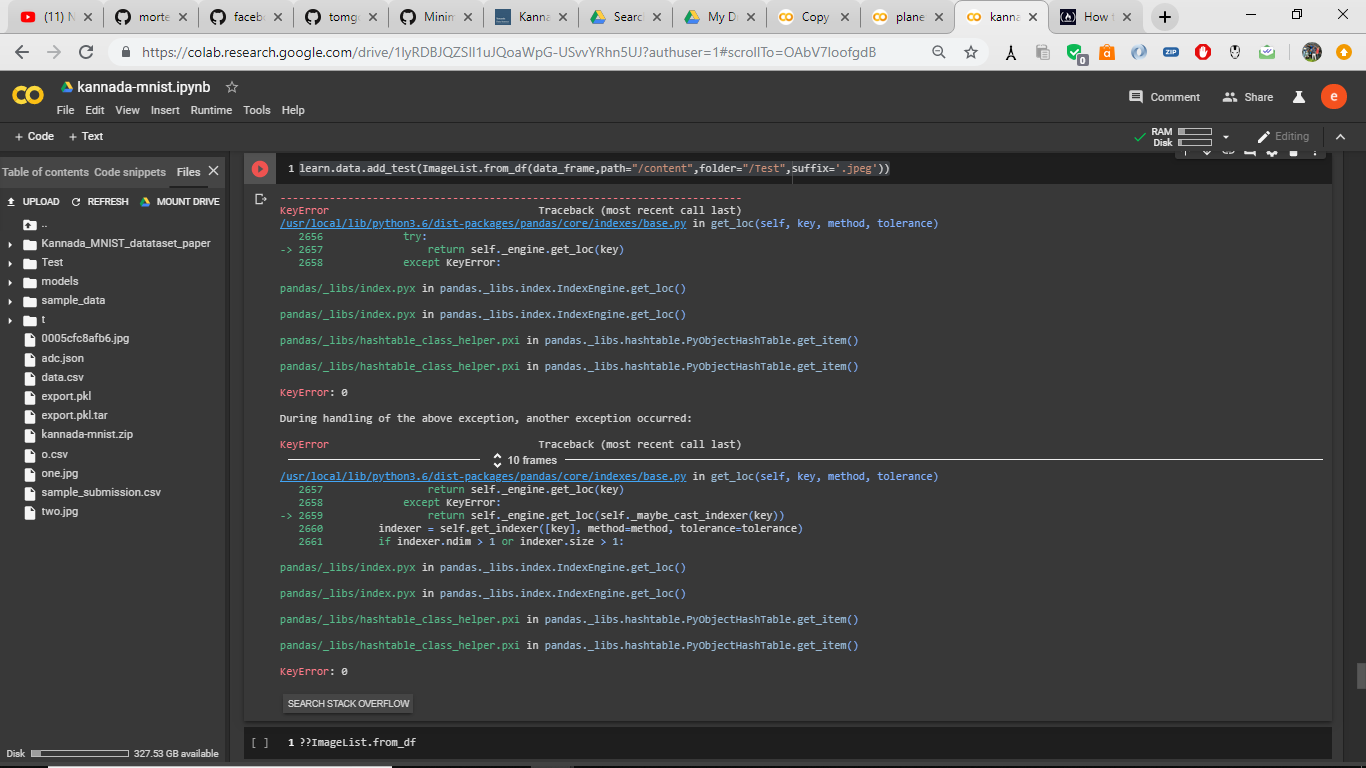
hello ,
I am trying to add test data from csv file . I have loaded the data frame through ImageList.from_df and then learn.data.add_test , but I am getting error as key error 0.
@Jeremy mentioned in one of his videos (probably lesson 2) that one of the TA’s was working on a document to provide guidance on how to organize/label ones data. I’m trying out the lessons with my own domain specific dataset .i.e benthic foraminifera
simultaneous learning how to code in python:weary:… i was wondering if anyone has some experience to share or python code that will help me out. I’ve been labeling individual image and still have over a thousand left. i need to just generate names from images in a folder and save to .csv (my folders are already in imagenet format)
Benthic foraminifera are single-celled organisms similar to amoeboid organisms in
cell structure. The foraminifera differ in having granular rhizopodia and elongate filopodia
that emerge from the cell body. Foraminifera are covered with an organic test that varies
from a simple single chamber with an aperture to a complex, multichambered, perforate,
calcitic wall, to an agglomeration of mineral grains embedded in the organic test. Benthic
foraminifera occupy a wide range of marine environments, from brackish estuaries to the
deep ocean basins and occur at all latitudes. Many species have well defined salinity and
temperature preferences making them particularly useful for reconstructing past trends in
ocean water salinity and temperature.
Hello, I’m new to this course and trying to go through Part of this course. I was trying to check the help for this function - ImageDataBunch.from_name_re but I couldn’t find any help what this does.
Can anyone please help ?
Thanks,
Sagar
Hey guys, So I tried training a bit on the Humpback Whale Identification dataset from Kaggle and the accuracy kind of freaked me out a bit.
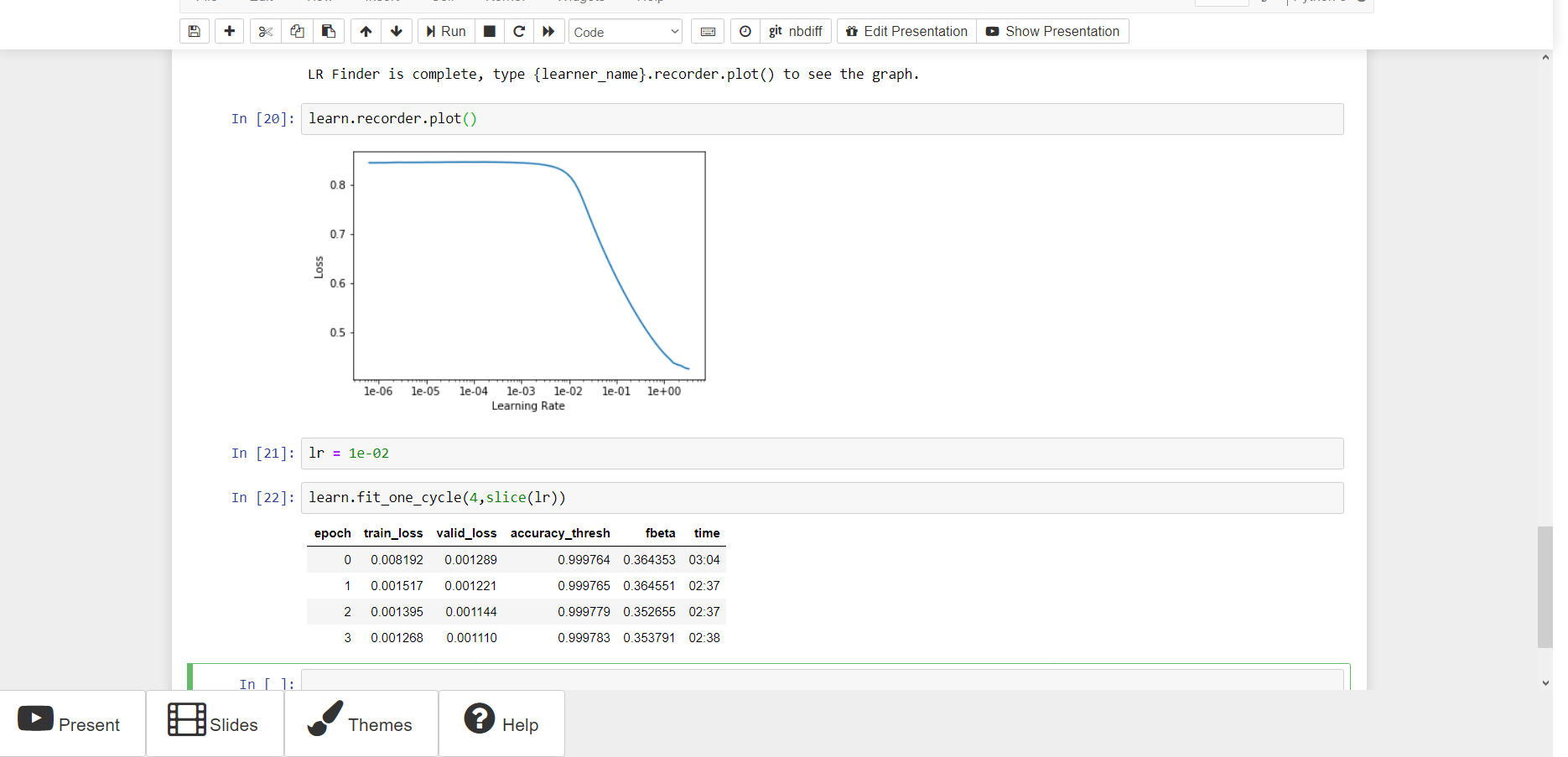
Is there something I should be concerned about since I didn’t use the test set and just split the training set.
Thanks in advance.
@jeremy thank you for the wonderful lectures and I have been recommending them to my friends who want to break into ML and Data Science. I am wondering which software you are using to record the lectures? We want to do something in our community where we want to teach ML/Data Science to school children from disadvantaged background to further democratize AI!
1 Like
I use this: https://obsproject.com/
Good luck with your project!
4 Likes
@jeremy is there any way I can do image regression such as predicting height from a photograph?
Hello everyone,
I want to fine tune the wiki language model with some PDFs for a classification task. Is there an optimal input size, (i.e. input as paragraph, page or whole PDF document) to feed the data into the model?
In the docs for TextLMDataBunch I found this line: “All the texts in the datasets are concatenated and the labels are ignored. Instead, the target is the next word in the sentence.” (https://docs.fast.ai/text.data.html)
Does that mean that input size doesnt affect the language model as all observations in the dataset are merged as one long text document?
Some clarifications on this topic would be super helpful and much appreciated!
Cheers!
Hi, Sorry if this is the wrong place to ask this question!
So I am currently trying to get through the very first lesson. Things are working fine except I have difficulty downloading the MNIST_SAMPLE data set.
For the below command
path = untar_data(URLs.MNIST_SAMPLE); path
I am getting a timeout error.
However I can see the file in the browser and download them manually using wget.
Please correct me if I am doing something wrong !
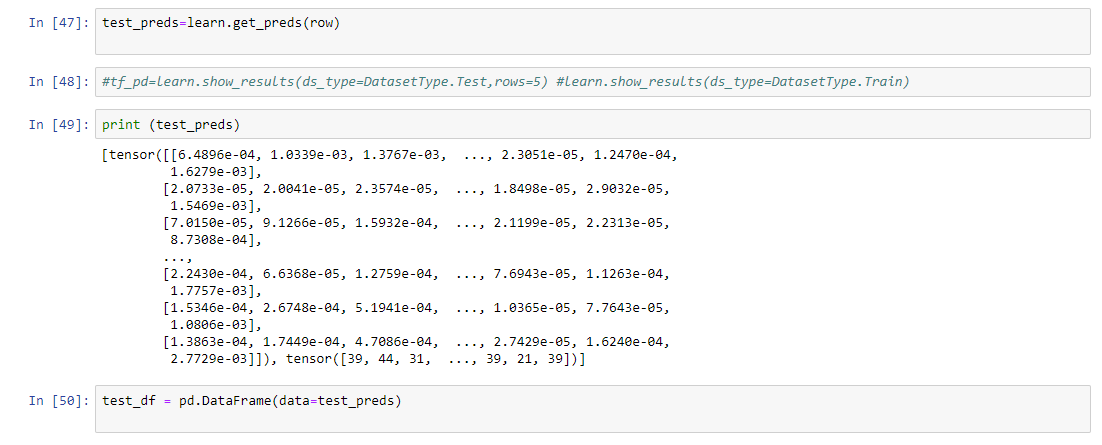
Hi all. This is my first post - apologies I couldn’t work out how to create my own thread.
I have used the collab_learner to to find embeddings for a collaborative filtering task. I want to try out the use_nn option and have trained a learner as such:
learn = collab_learner(data, use_nn=True, emb_szs={'user': 50, 'item':50}, layers=[256, 128], y_range=(-1, 1))
I cannot work out to extract the embeddings. The method for the dot product version of this learner fails:
learn.weight(allitems)
Where allitems is an array of the unique item ids going into the learner.
AttributeError: ‘EmbeddingNN’ object has no attribute ‘i_weight’
Looking at the source code it seems the weight method is only set up for the use_NN=False situation. But the collab_learner does not have the embeds attribute that the underlying TabularModel possesses.
Any ideas?!?
P.S. the document string for the weight method of the collab_learner is incorrect, it’s a copy paste of the bias method.
Hi
Thanks for the course. Its awesome.
I have a problem that I can understand almost many things. But I am getting stuck when I want to do projects on my own.
How should I proceed further?
Thanks
can you share your jupyter notebook ?
What pretrained model should we use for numerical data?
i’d say:
pd.DataFrame( YourTensor.data.numpy() )
without .numpy() it returns a dataframe filled with FloatTensors.
Also there might be a smarter way to do it…
1 Like
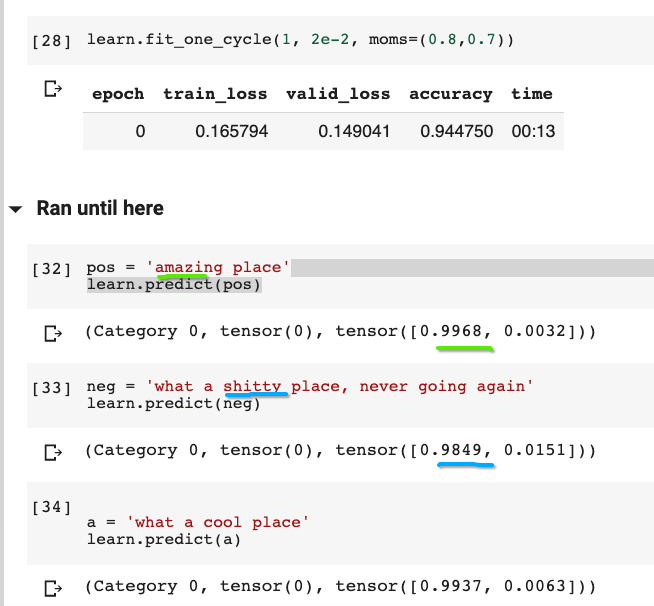
Hi ! I’m doing classification on a quora Kaggle competition dataset. I’m getting a very good accuracy rate, but when ever I test it, it gets nothing right (tensor 0 is negative). Can anyone imagine why ?
Hi i have problem, i got path :
‘color/Apple___healthy/1aa82164-61f2-4baf-b99d-41f18f6e98cc___RS_HL 8087.JPG’
and i ty load classes : Apple___healthy
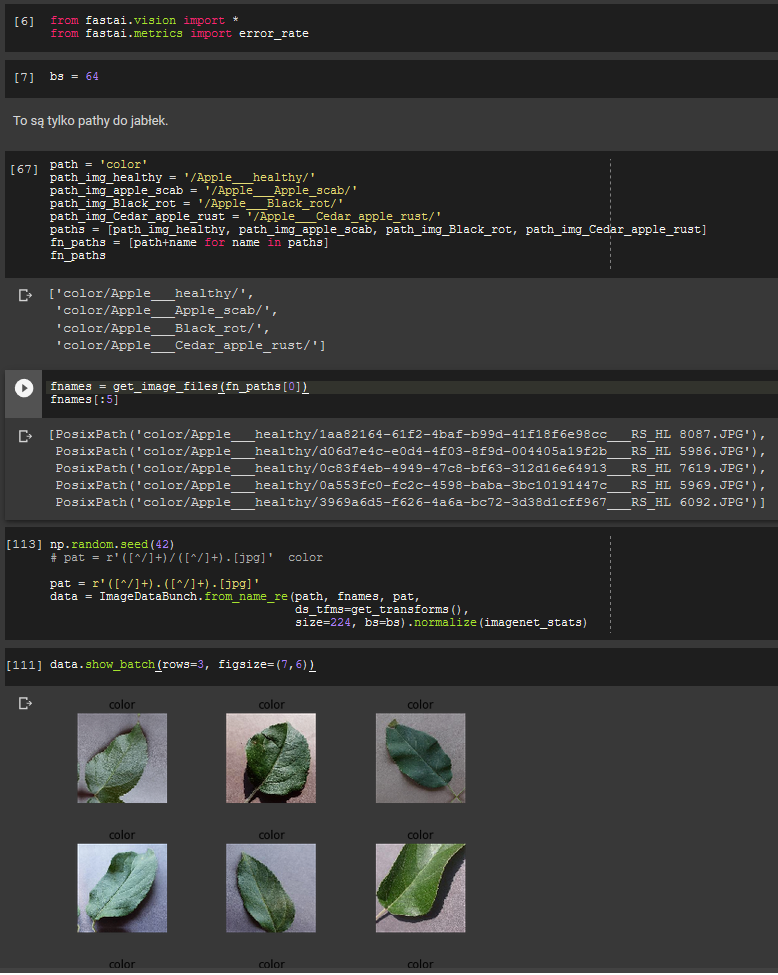
my folders to classes :
[‘color/Apple___healthy/’,
‘color/Apple___Apple_scab/’,
‘color/Apple___Black_rot/’,
‘color/Apple___Cedar_apple_rust/’]
Hi
I am having issues accessing Jupyter notebook behind a corporate firewall. Is anything can be done so that I can see notebooks? I am using Salamander.Thanks
Is it advisable to skip (vs quickly skim over) Part 1 v3 and go straight to Part 2 if I have recently completed Deeplearning.ai/Coursera’s mostly Tensorflow based specializations and Udacity’s track on Deeplearning with PyTorch?