Because GCP can access the internet, I was thinking that you could possibly e-mail the notebooks to yourself, but I found a better resource for you:
https://cloud.google.com/compute/docs/instances/transfer-files
Because GCP can access the internet, I was thinking that you could possibly e-mail the notebooks to yourself, but I found a better resource for you:
https://cloud.google.com/compute/docs/instances/transfer-files
The embedding size for a category is the dimension (number of weights) that you specify for its embedding vector. The algorithm Jeremy uses is something like
embedding_size = max( ceil(N)/2 + 1, 50)
There is actually a great method in fast.ai that do it for you in case you are using df.
Hello everyone,
I have an Nvidia geforce gtx 1070, trying to run the code in Spyder or Jupyter notebook. (I have installed Anaconda, python3.6, CUDA and Pytorch for windows 10). But it seems my GPU is not being used because the training part of Lesson#1, which takes a few minutes in Colab, takes hours on my PC!
Do you have any idea?
Hi all
Have started working through fast.ai and I love it.@jeremy, is the best teacher I’ve found thus far as far as AI/machine learning goes. I’m up to course 5 but now wondering…
How, if at all, can one do text similarity with fast.ai to answer questions like: did this person write this text? (Answer = "XX% confident they did/did not)
In other words, be a text similarity / plagiarism / author detection application. Reason I ask is because I’m curious to see whether fast.ai can provide a fresh look at answering “Who is Satoshi Nakamoto?” question and I plan on building a tutorial jupyter notebook so that others can debate it, improve it, etc.
Thus far I’ve found:
News headlines claiming someone isn’t satoshi but failing to release the papers/work (can’t post 3 links as I’m new but if you google “ibtimes satoshi text analysis” it’s the 1st result)
Chon’s work which used support vector machines, random forests etc but didn’t include all parties, such as the very controversial Australian computer scientist Craig Wright – see https://towardsdatascience.com/stylometric-analysis-satoshi-nakamoto-294926cdf995
By searching this forum, a trump post – Medium: Great NLP application article (who authored Trump tweets?) – which also used random forests, gradient boosting, etc
Could fast.ai have a better tool for the job?
If you have any advice, tips or links to any methods or tutorials, please share because I’d love to work on this on my nights and weekends. I’ll also share my results with the community.
Thanks 
So I’ve been tinkering around with FastAI vision and was wondering in what use cases would someone use FastAI’s software versus Amazon Rekognition API. What advantages do we have using this library over already pre-built image classifiers?
Have you tried torch.cuda.is_available() to verify if CUDA is available?
Yes @MicPie, its result is True. I do not know what’s the problem :\
I tried these lines too:
import torch
print(torch.cuda.is_available())
cuda0 = torch.device(‘cuda:0’)
print(‘Using device:’, device)
if device.type == ‘cuda’:
print(torch.cuda.get_device_name(0))
print(‘Memory Usage:’)
print(‘Allocated:’, round(torch.cuda.memory_allocated(0)/10243,1), ‘GB’)
print('Cached: ', round(torch.cuda.memory_cached(0)/10243,1), ‘GB’)
and got these:
True
Using device: cuda:0
GeForce GTX 1070
Memory Usage:
Allocated: 0.0 GB
Cached: 0.0 GB
Hi! How did you fix this?
Hi @akshayb7, would you have simple instructions detailing how to fix this problem?
Hello…Can anyone please guide me how to do regression problem (like price detection) through tabular data framework? Lesson 4 contains a classification one…I am finding hard to understand how to implement this for regression one…
Hi , Could someone please share resource on how to implement kfolds validation for image classification using fastai. Thanks in advance!
If I scroll, making it through the lazy-post loading nightmare of Discourse, all the way to the bottom, I get a link suggesting I can make a new post.
When I use it, I get this error when I am about to submit my post.
Hi
@jeremy
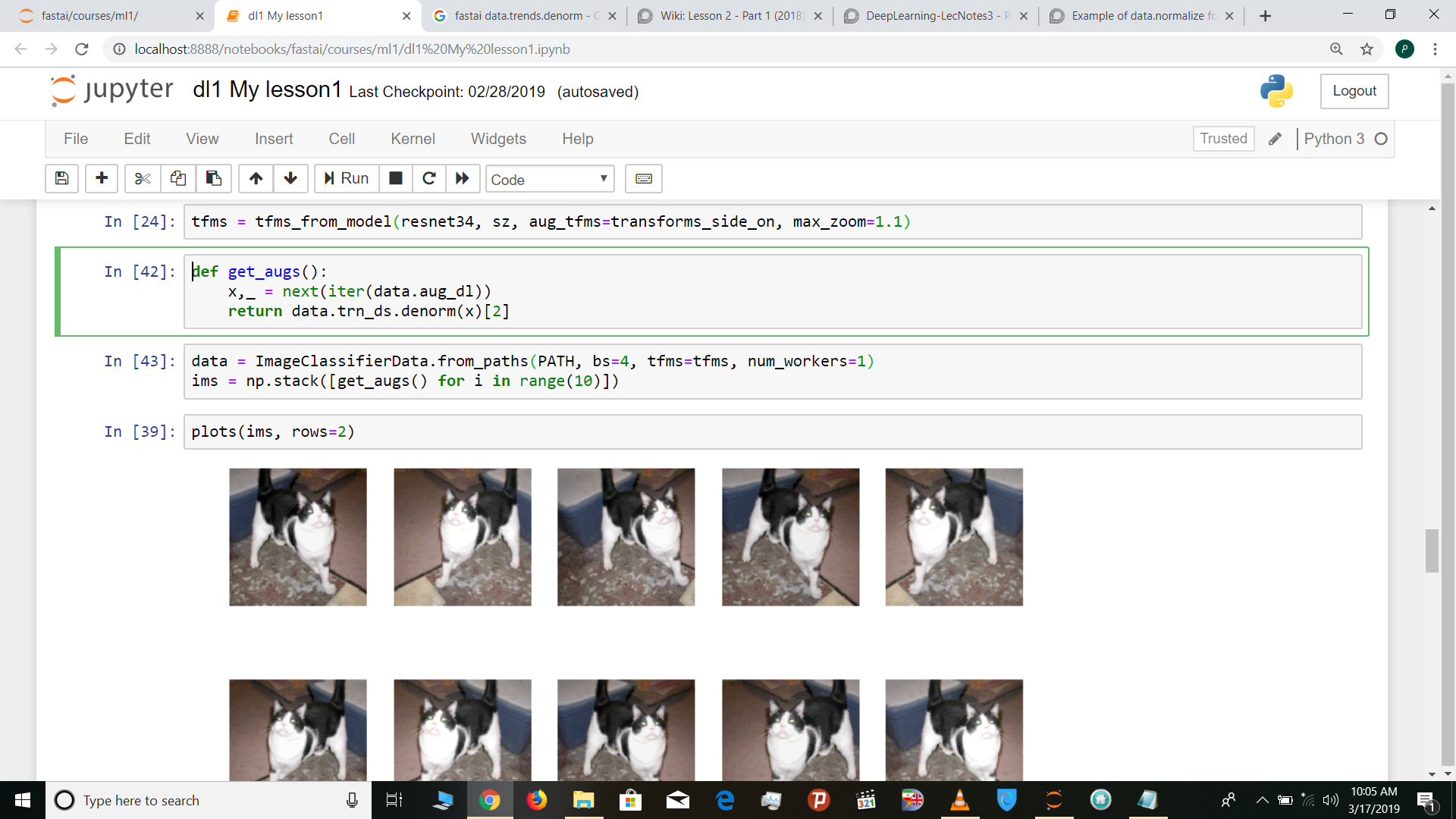
what does this line of code do ?
return data.trn_ds.denorm(x)[2]
that is related to DL1 2018 lesson 2
but i think here will be answered faster !
Please read the etiquette section of the FAQ.
accept my apologize !
Hi,
How can I find the file url based on the following line?
losses,idxs = interp.top_losses()
Many Thanks,
Michal
Mahdi, if you just highlight the line of code in your question, right click and select “search google” you’ll see Hiromi’s course notes that talk about that. It’s the 3rd or 4th search results as of right now.
I agree, but can’t find anything on the Livestream. Did you find out anything about Part 2, starting tonight?