My method is to duplicate all of the master copies and always work on the copies, and Jupyter has an option for this. Just select all and click Duplicate at the top of the file list. Sometimes the master copy will change again - depending if I have modified my copy I either delete or end up with Copy and Copy 2 etc.
1 Like
Hello all, Is anyone taking part in Humpback Whale Challenge on Kaggle, I am facing certain problems regarding how to use the fastai library and looking for someone who can guide/help me or even better participate as team with me?
There’s a thread in this subforum. Jeremy reminded us that sharing outside the official Kaggle forums or on teams is forbidden, so we are not discussing the data itself, but fastai specific questions are still fine I believe.
I am mainly facing issues with fastai library. Can you help ?
Go check that thread. Some common issues already covered.
I was the one who has posted about the problem with metrics not working in create_cnn in that thread.
Hi @jeremy you mentioned in your fireside chat with @isamlambert that you can now have a sort of ‘plug n play’ access to fastai notebooks on GCP.
can you show me how-to in the forum pls? I spend quite tons of hours trying to access the notebook via gcp.
I was watching some of the earlier lessons again…based on the image attached(screenshot from lesson 3). Just a random idea…probably already done

In such a scenario, I can imagine that i could have easily added even more epochs in my first attempt. Does it make sense to temporarily save the model after each epoch… so this way, if i end up overfitting, I can just load the model at an earlier epoch cycle instead of training the whole thing again? Wont this save a lot of time? Is this already done? Is it possible?
1 Like
Please refer to the etiquette section in the FAQ.
I posted this in Part1 a few days ago because it fit a topic there:
but I still have no answer. Since Jeremy’s nb’s always have the input prompt numbers cleared, but the cell outputs still there, clearly there’s a way to do this! Somebody please let me in on the secret… ![]()
@fabsta Were you able to resolve this? I am getting PermissionDenied error. I am loading data froma different location than the one in which I have my fastai installed and it is trying to use that folder location to serach for model
It makes sense to me and is possible by adding a callback.
One thing to think about is because the learning rate for fit_one_cycle changes over the course of the training fitting 10 epochs and loading the result after 9 will give you a different result than fitting for 9 epochs. No idea which would work better if underfitting (and in fact maybe it’s just better to up the regularization slightly).
1 Like
Hey Edward,
I have been seeing this with my models and was not sure why this happens. Would you please elaborate on this? As in, if I train my model for 4 + 2 epochs, the training and validation error are quite different than just plainly training for 6 epochs (after seeding everything).
good point! makes intuitive sense then to run extra epochs first cycle(overfit) and using saved epochs(using callbacks) for quick testing etc. but for getting lowest error rates(production etc), guess it would always make sense to re-run at / around the epoch cycles where error rates started increasing while overfitting. Is my understanding correct?
After running a fit_one_cycle have a look at the learning rate:
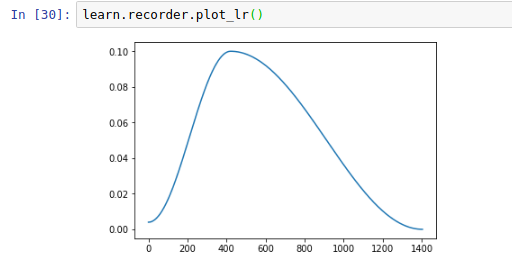
It starts off small and goes up to lr_max and then drops quite low.
If you did e.g. 4+2 there would be two cycles like, one taking up the first two thirds of the x-axis and the other taking up the second third.
Now it doesn’t seem likely that’s a good idea as you’ll keep bouncing around, but if you drop the max_lr (so you get smaller and smaller waves) and/or increase the number of epochs you may find a better way to train the model.
1 Like
Thanks for the explanation. Now it makes some sense to me.
Hi, Thanks fast.ai and Jeremy for Part 1 of this course. That was great information and inspiring, looking forward to understand it by going through the videos. One question, is there a timeline/tentative on when Part 2 is starting?
Are the powerpoint slides from each of the class lectures available for download anywhere?
I didn’t see them in the course-v3 repo.
On fitting / training my models I am addicted to watching the bar move and seeing my loss values drop. Wasting so much time doing it. Thinking of starting a support group for other addicted students if anyone is interested. lol. need help.
4 Likes