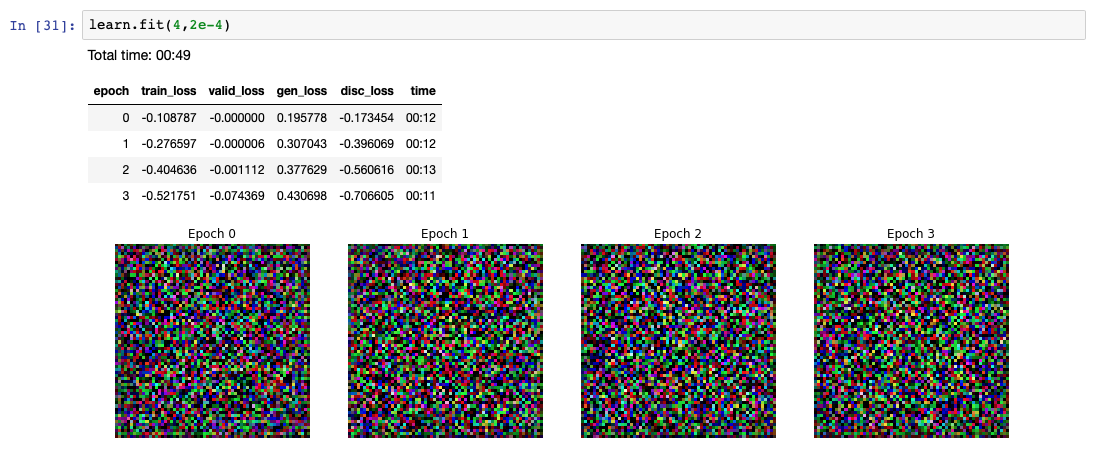
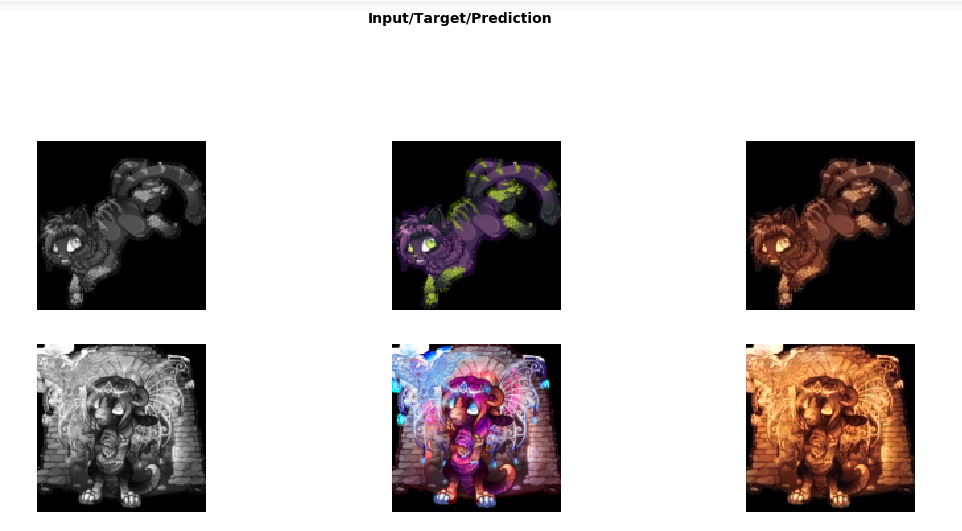
I am trying to get the GAN workbook from lesson 7 to work on a dataset I supplied. The challenge is that during training, the pictures generated are only of random noise, it does not improve at all. I am using about 244 pictures of desk chairs like this.
The only things I have changed in the workbook are the input directory, changed the split_by_none in to split_by_folder (i have a validation set of about 10 images)and the batch size to 20. This is the result if I train for a few epochs:
I have tried to train for longer, but all the losses only go up, while the pictures keep looking like random noise. Is there something I can do to get this to work? Or is my dataset simply too small?
As a sidenote, I have a bunch of pictures of assets around the office so if I get this to work I can post a cool GAN-generated coffeemachine.
In another post (sadly I don’t find it anymore) someone wrote that changing the learning rate might have an input on the epochs. For my code changing the learning rate actually helped only a little (the output were not completely random anymore) but it was still very bad especially the colors were really messed up, basically not changing much. Would be very nice to know, why this is happening… Has anyone else a clue?
Same happens to me in fastai v2 with a dataset of 1500 images. You can try changing loss function and the generator/critic switching policy (I assume you can also change that in v1)
Thank you - so I guess I have to study a little more - don’t know exactly how to do this, yet. But I also found out that dealing with a dataset that is too small doesn’t work either. At least I get better results with a dataset of > 1500 pictures.
In that case you can also try making your dataloader have all the images repeated until you get to > 1500. That should make sure its a data issue and not other stuff
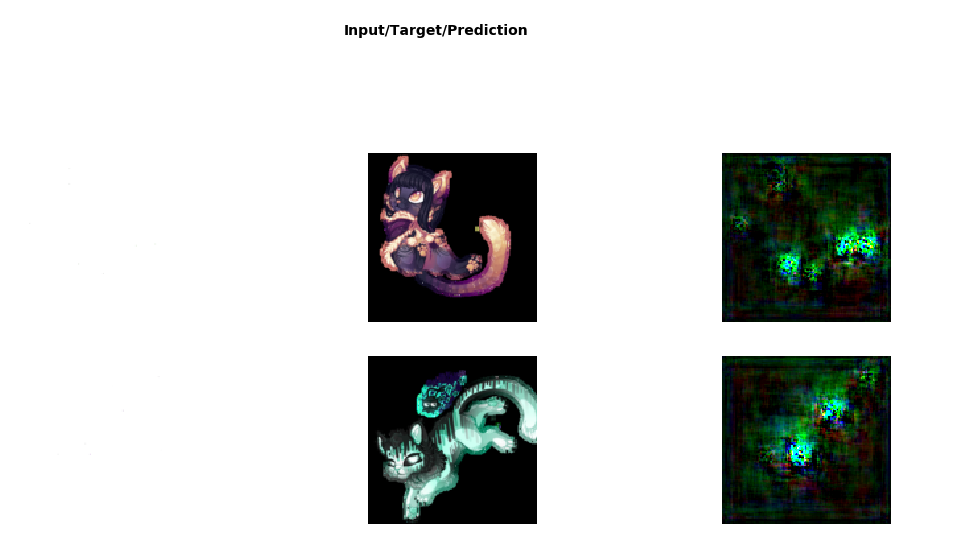
Hey Juvian, thanks so much for the suggestions so far. I’ve tried to implement what you suggested, but I still get the same results. This is very likely because I only have 312 pictures, but I was wondering if you could take a look and still have some suggestions? My notebook is here:
I had your issue before with only 200 images(is it small?). How much images in your data?
It was a super small dataset without using imagenet, so the model only knows about little things.
Dataset contains 200 images, the model to identify object was based on human skin.
It was solved after founding out some issue in the model, such as learning rate, layers that I should pick, and more.
For this one, it was caused by picking the wrong layer and focus too strong the later layer(layer that identity object that is closer to result, such as hand or head)
This will be a little tricky since these images come from my company. I cannot imagine they are sensitive since they are just pictures of chairs, but I will check to make sure. In the mean time, do you have a working example you can share? Again, thanks so much for the help so far