I am facing the problem of strong discriminator in training a GAN. This leads to poor generated outputs (i.e. the generator loss is saturated). There are some ideas like this to tackle this problem. However, I am still thinking why training the generator network with more additional iterations than the discriminator one cannot help to fix that !
Did anybody have an idea why this is not possible ?
Perhaps, training the generator more doesn’t help because the generator gets its insight of the distribution from the discriminator.
What things did you try from the link? When I had a problem with a GAN I checked the gradients (as suggested in the link). I found that they were sometimes over 100 and that the discriminator’s loss wasn’t slowly decreasing.
Function for checking the gradients:
def check_grads(model, model_name):
grads = []
for p in model.parameters():
if not p.grad is None:
grads.append(float(p.grad.mean()))
grads = np.array(grads)
if grads.any() and grads.mean() > 100:
print(f"WARNING! gradients mean is over 100 ({model_name})")
if grads.any() and grads.max() > 100:
print(f"WARNING! gradients max is over 100 ({model_name})")
Use it before zero grad.
Example for generator:
check_grads(generator_model, "gen")
generator_model.zero_grad() # or generator_optimizer.zero_grad()
For the discriminator use it the same way (before zero grad) like check_grads(discriminator_model, "dis").
The reason for these high gradients was, in my case, that I used Adam as the optimizer for the discriminator. As the link suggests sometimes it is better to use SGD.
Actually I am using LSGAN and checking the performance according to the discriminator and generator losses. I have tried the idea of instance noise but it wasn’t that much effective.
As you have mentioned that increased gradient causes a strong discriminator (i.e. fast decrease of loss) , does gradient penalization help in this case ?
If I understand LSGAN correctly it is just like a basic GAN but:
the discriminator doesn’t have a sigmoid at the end
the criterion is BCELoss between discriminator output and 1 for real, 0 for fake samples
This means that it is still nowhere as easy to train as WGAN or WGAN-CT… I found this to be very helpful for implementing a working GAN: https://github.com/Randl/improved-improved-wgan-pytorch - if you still need help implementing I am happy to help!
If you want to keep using LSGAN, have you tried changing the optimizer for the discriminator to SGD?
Currently I have switched to WGAN using ADAM optimizer for both generator and discriminator. I still cannot touch far difference from LSGAN but will continue with the improved version and see.
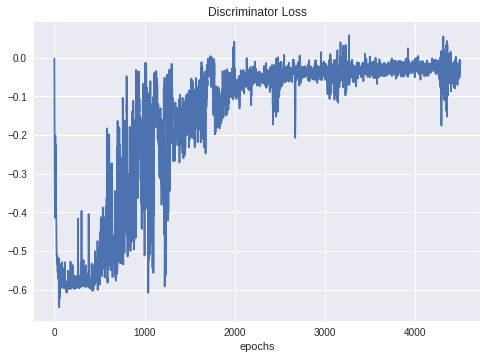
Here is the loss curve of discriminator of WGAN
I am plotting “errD” according to line 198 in this implementation (after averaging the errD tensor over the mini batch) … does this look reasonable in terms of mini-batch size= 32 ?
Regarding the usage of SGD optimizer, could it be better than adaptive optimizer (e.g. adam) in terms of loss minimization ? or that’s just to make the discriminator weaker ?
The errD plot indicates that the generator is getting too strong. 0 means the generator is always fooling the discriminator and -1 is when the discriminator can always tell which one is which.
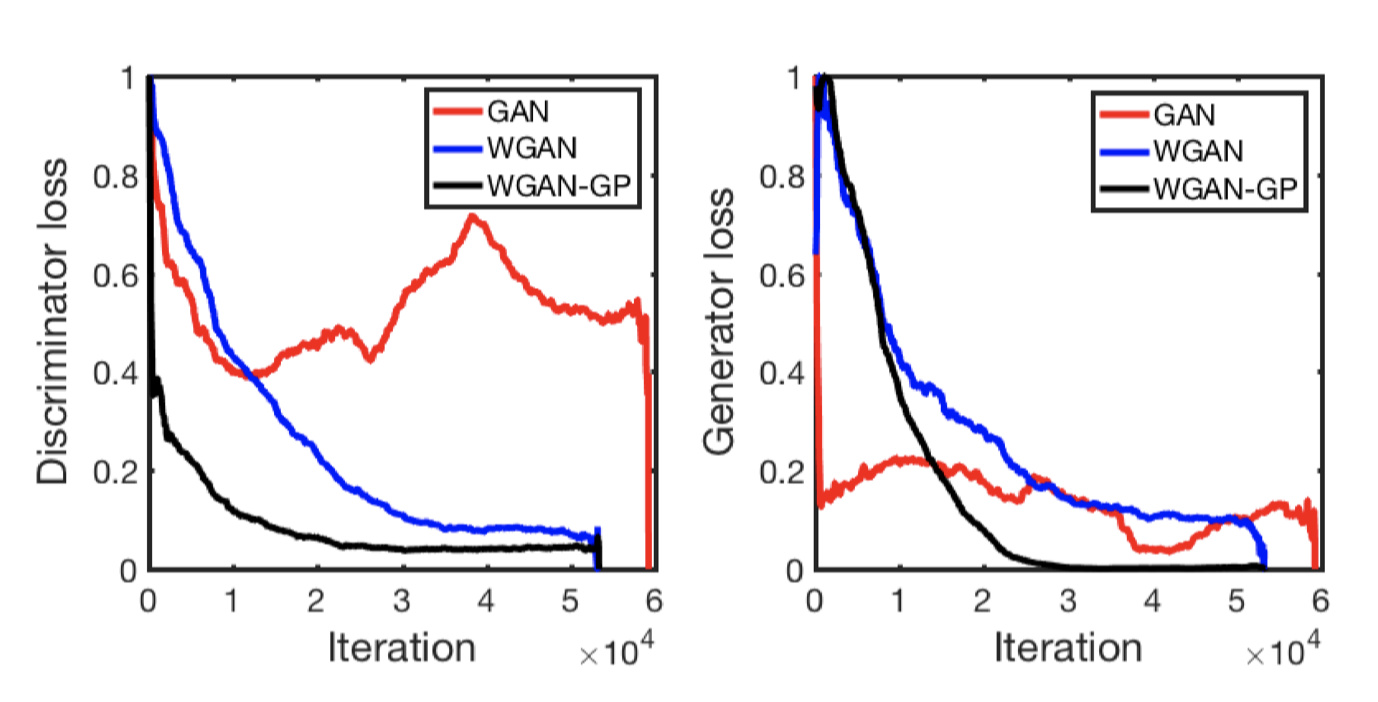
They are; the original form of GAN with Adam, WGAN with weight clipping and RMSprop, WGAN with gradient penalty and Adam. I believe LSGAN would have the same inconsistent loss plot as the normal GAN.
(Just add 1 to your errD before plotting and it should be in the same range as the graphs I sent.)
The problem with yours is that the discriminator loss isn’t decreasing like in those graphs. Maybe it is in the first 100 epochs… But even that doesn’t look as smooth to me. You might be possibly overtraining it (I think that is certainly possible with gans). Try training for maybe only 100 epochs or less and see what is happening to the losses.
I think the SGD might be better in some cases (for example the gan I implemented). I will also try RMSprop and see if that is also as bad as Adam in my case. The reason for this I don’t know. Probably something to do with overshooting. I would definitely give it a try and see what the graph looks like.
I did try RMSprop too and it too caused my discriminator loss to not nicely descend but fluctuate.
The discriminator curve approaches zero at epochs > 2000 , I am training for 4500 epochs … does this still mean that the generator is too strong ?
The loss curve seems to be fluctuating as I don’t average (smooth) over iterations within each epoch. I have two nested loops, one for epochs and the other one for the data-loader iterator during each epoch. What I am plotting is only the latest iteration loss value per epoch and I think that’s why the curve has remarkable variance.
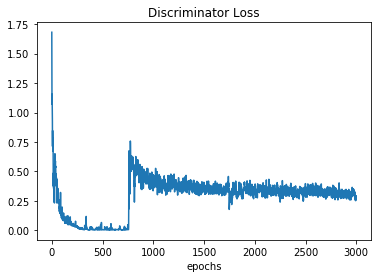
Here is how it looks in case of LSGAN
I don’t know the reason for that clear kink. But it is good to know that discriminator in WGAN should be strong as possible.
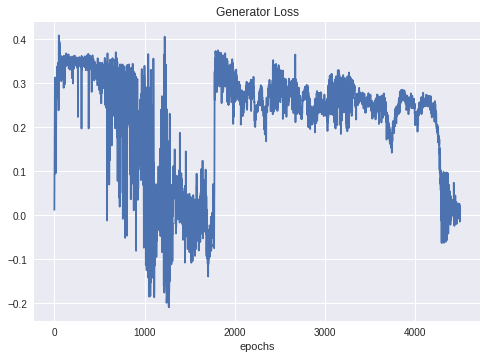
The generator loss in WGAN still not descriptive, but at least it tries to approach the zero at large epoch values. (again, cannot justify these clear jumps)
Bear in mind that I am NOT an expert in GANs! I have trained a few successfully and have therefore some experience. Plus I am very interested in them and therefore learned a lot about them. I hope I can help!
I believe that means that your WGAN discriminator isn’t strong enough. Try even more discriminator updates than generator updates.
If you compare your LSGAN loss to the GAN loss I think the discriminator is too strong. In case of GAN, it is important to have a balance between how strong the generator and discriminator is. They should be able to “fight” like in the GAN loss graph and in yours, it looks like the LSGAN discriminator is just overpowering the generator. I would try with a stronger generator architecture or at least a different one.
The reason for the jump in loss I think is too high learning rate. Try to lower it after you get to 0.1 discriminator loss.
Your generator loss (WGAN) also looks like a similar problem. Either try lowering the learning rate or try changing the betas for Adam.