Interesting…It worked out of the box for my LM transfer learning work on AWS P3.2X where half precision flag is used. But I didn’t check the wall times to see if the speed up was actually due to the half precision cores.
Can you override the half flag and see if it still works?
since the fp16 argument isn’t in the constructor hence the 3rd approach is a workaround.
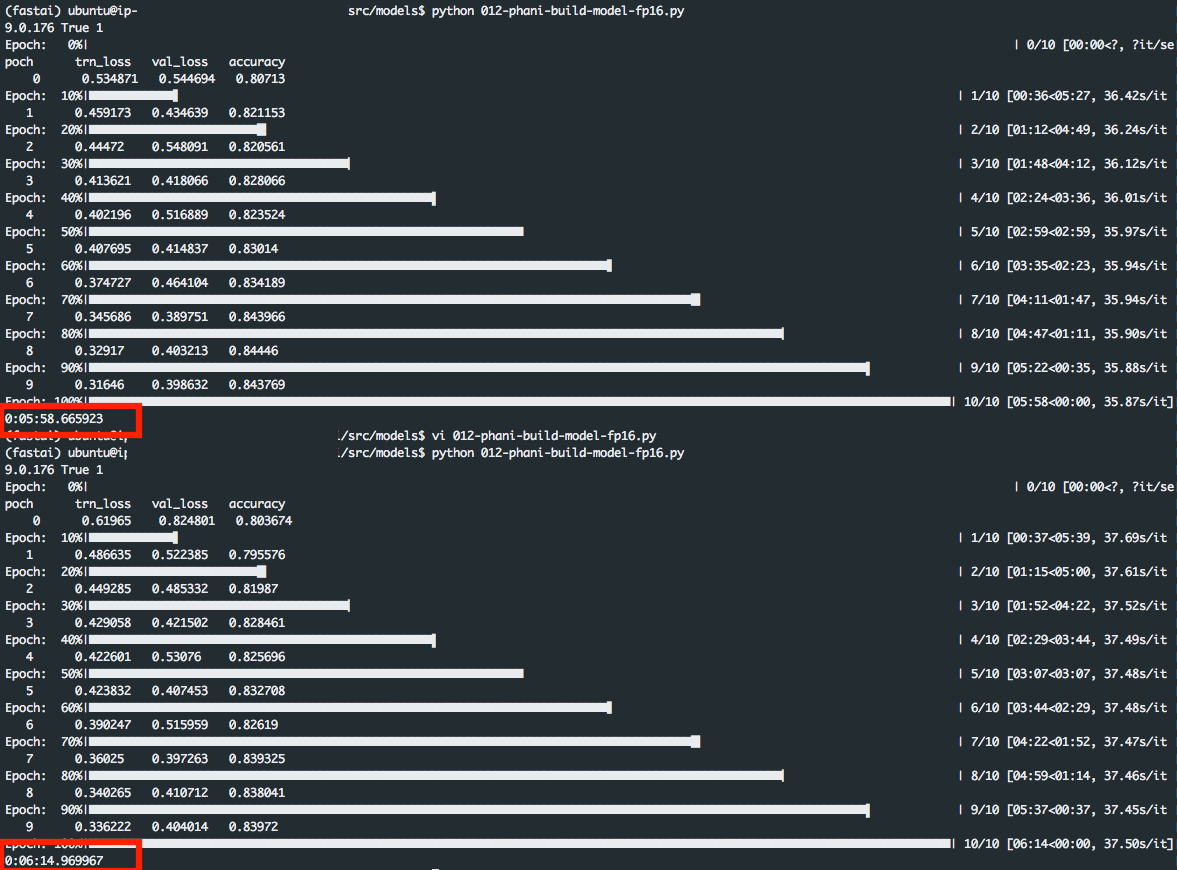
In all of the above approaches, the timing is almost the same: One training run of cycle_len=10 takes 6 min 58s, 6min 49s, 6min 55s - This difference is insignificant.
I’m experimenting on a dataset with 1cycle lr schedule with a cycle length of 10. I warmed up the GPU by doing one run and subsequently did the following test using a python script.
The first run is with fp16 and the second run is without. As we can see the runtime is 5:58 with fp16 and 6:14 without. The seconds / iteration is almost the same - 35 ~ 37 - the difference is insignificant, right?
On another note, for benefit of others who try this, when I mention a custom metric metrics=[auc] in ConvLearner.from_model_data by defining auc as
from sklearn.metrics import roc_auc_score
def auc(preds, targs):
return roc_auc_score(np.array(targs), preds.cpu().numpy()[:,1])
I encountered this error AttributeError: 'torch.HalfTensor' object has no attribute 'numpy'
and it so happens that it’s an open bug in PyTorch - https://github.com/pytorch/pytorch/pull/2123
Looks like I’ve gotta fix my fp16 training before I talk about metrics
I’m currently using 96x96 images to quickly test different models. Do you suspect that as each epoch of around 30k images finish in around 36 seconds, the transformations could be a bottleneck? Currently, the cpu utilization is hovering around 90-95%.
To establish if this is the problem, should I load in slightly larger images and see the difference? Would that be a reasonably good direction to debug?
You could try using torchvision transforms and the regular pytorch dataloader - we noticed in DAWNBench that the fastai transform pipeline is slower when using lots of cores (we’re working on fixing this). You should install pillow-simd with accelerated libjpeg using this:
Looks like learn.half() works perfectly in a notebook too! Using it with the torchvision dataloaders was giving a really good speedup almost 40%. Now that the model is in half-precision mode, I could use a larger batch size (almost double) and get some more speedup on my datasets.
I haven’t gotten benchmarks of with and without pillow-simd but that’s alright.
To put things in perspective, the model which took around 11+ hours to run now runs in ~4 hours. The tricks are: torchvision loaders + fp16 + bs*2 + pillow-simd + data prefetching.
This week when I get a chance, I’ll try it on MultiGPU and report the results.
All thanks to the imagenet-fast repo, it contains a lot of tiny aspects that make training way faster. These aren’t documented at a single place on the web except the dawn repo. Maybe I should write a post about this.
For those who encounter this error, a simple way to get around this is preds.double() instead of torch.*Tensor(preds). This works without losing precision.
learn.half() works well indeed in jupyter notebook: on cifar10 gives some 10-15% speedup on my machine. Seems though that accuracy suffers just a tiny bit.
however you may want to get rid of the row 87 in dataloader.py:
for c in chunk_iter(iter(self.batch_sampler), self.num_workers*10):
without this row I get some 5% speedup on cifar10 wideresnet experiments.
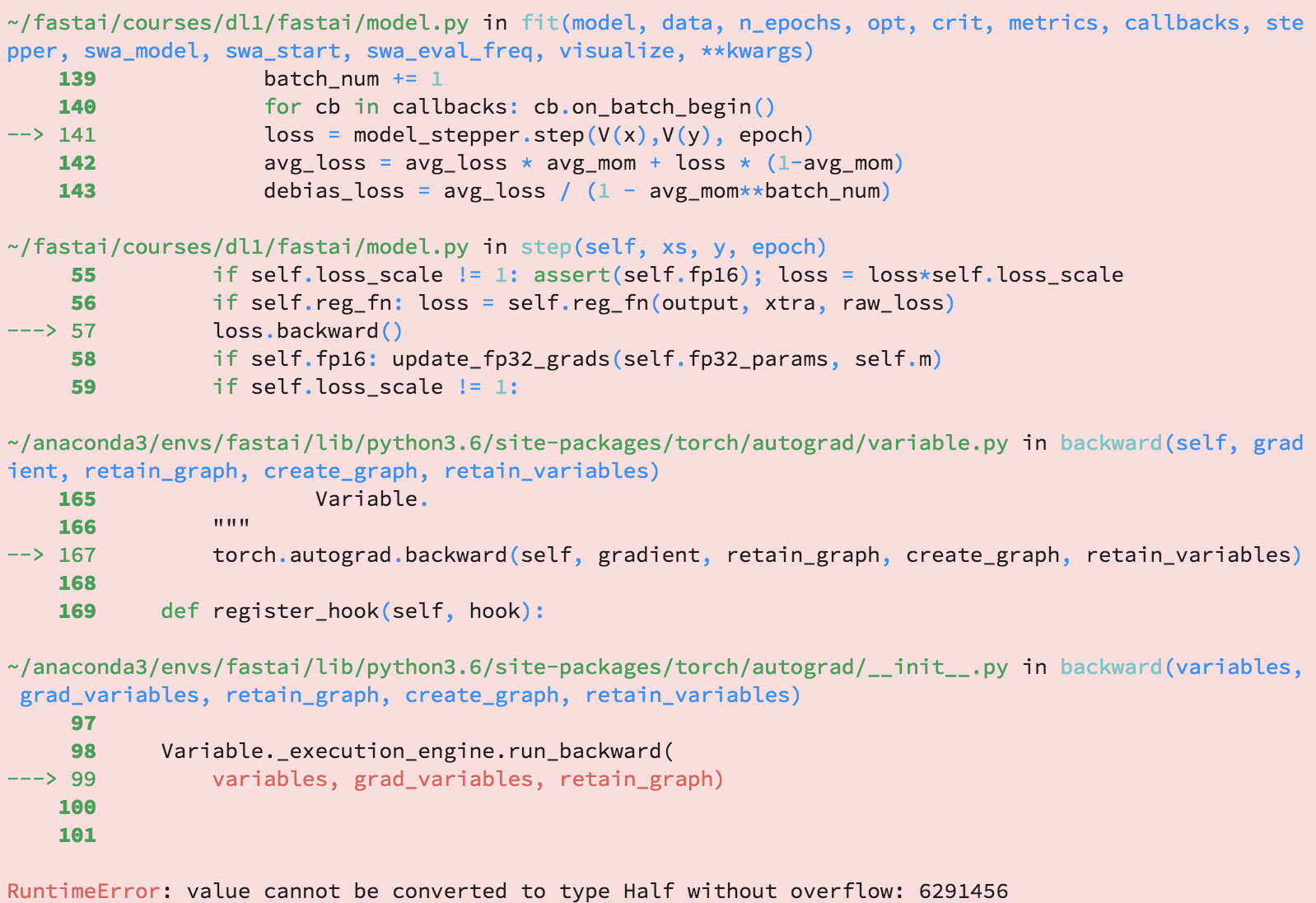
I’m having some issues getting FP16 training working on a V100. It looks like my gradients are too large?
Here’s the weird part. Every time I try to run the notebook the number in the error is the same - 6291456. Loss scaling doesn’t help the issue. I’ve tried scaling the loss by a factor of 10 up to a factor of 1,000,000. The problem persists, and the 6291456 value remains the same. Any ideas on debugging this?
Also I’m not sure if this is relevant, but I’m using conv_learner to add a custom head. When I call learn.half() I get an error 'Model' object has no attribute 'fc_model' during if not isinstance(self.models.fc_model, FP16): self.models.fc_model = FP16(self.models.fc_model).
fp16 isn’t really being maintained much on 0.7. If you’re interested in fp16, you might want to switch to v1. Development happening in #fastai-dev. Will be released in a week.

 Maybe I should write a post about this.
Maybe I should write a post about this.