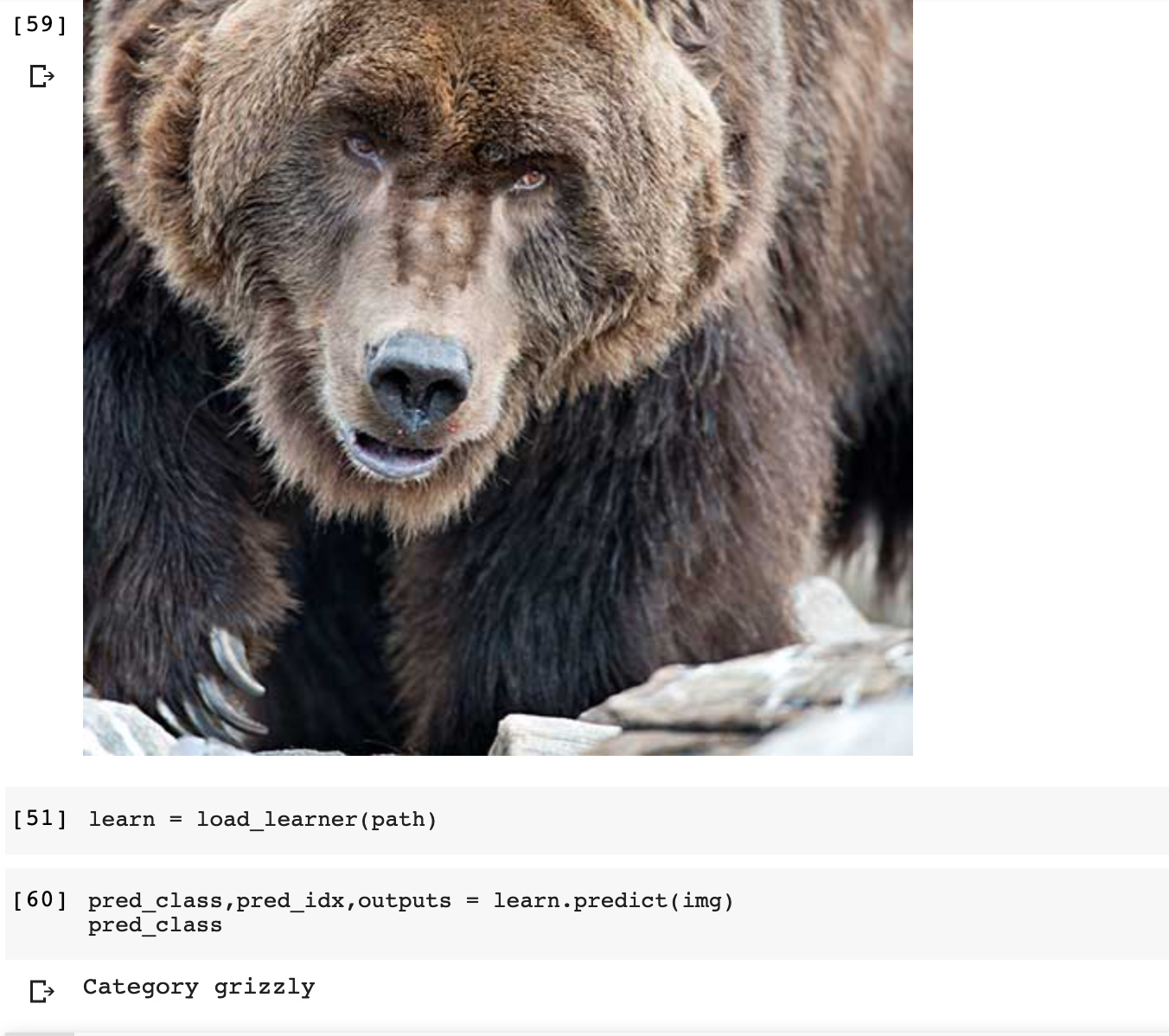
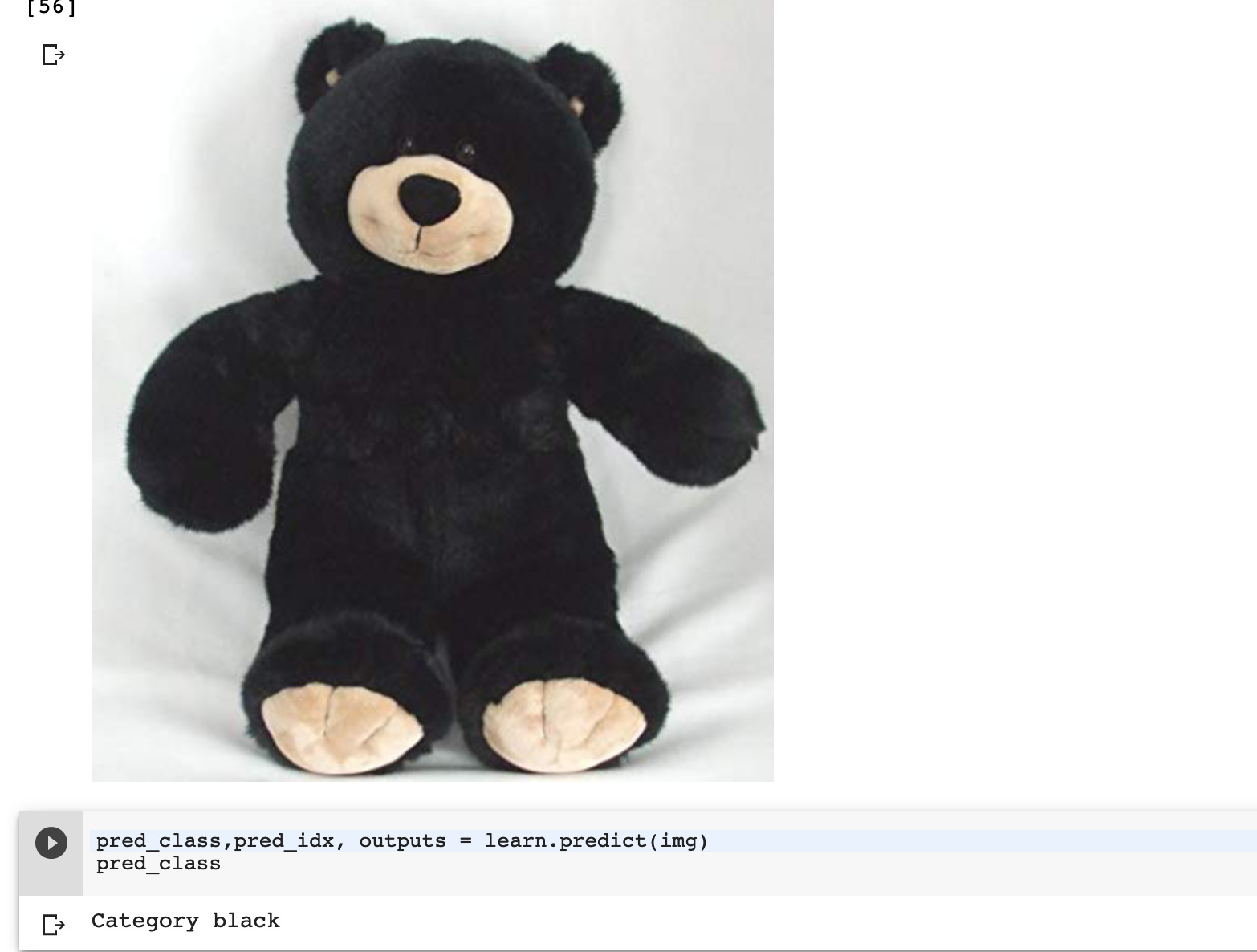
The model only learns what it needs to learn in order to minimize the loss function you give it.
It will learn to predict what’s in your training set. The more different something is from the examples your model is trained on, the less likely it is to give useful results.
It might determine color is important. Or it might find another way to transform pixels into classes.
There’s no way to know what it will learn ahead of time. But if you want to find out what it has learned, have a look into “feature extraction”.
I think this is actually a good find. What you discovered is that the model puts a big weight on pixel-color to differentiate the classes which kind of makes sense as black bears are black and the other classes are usually not. If you want a more robust model that can differentiate black teddybears better from black bears we’d have to include a lot more black teddy bears in the dataset. This would “force” the model to put more weight on other things (like shape).
A good experiment would be to put only black teddy bears in the teddy portion of the dataset and see what happens
Another good test if you suspect the pixel-blackness is used to much is to try it on some completely unrelated (non-bear) but black items and see if it predicts it to be a black bear.