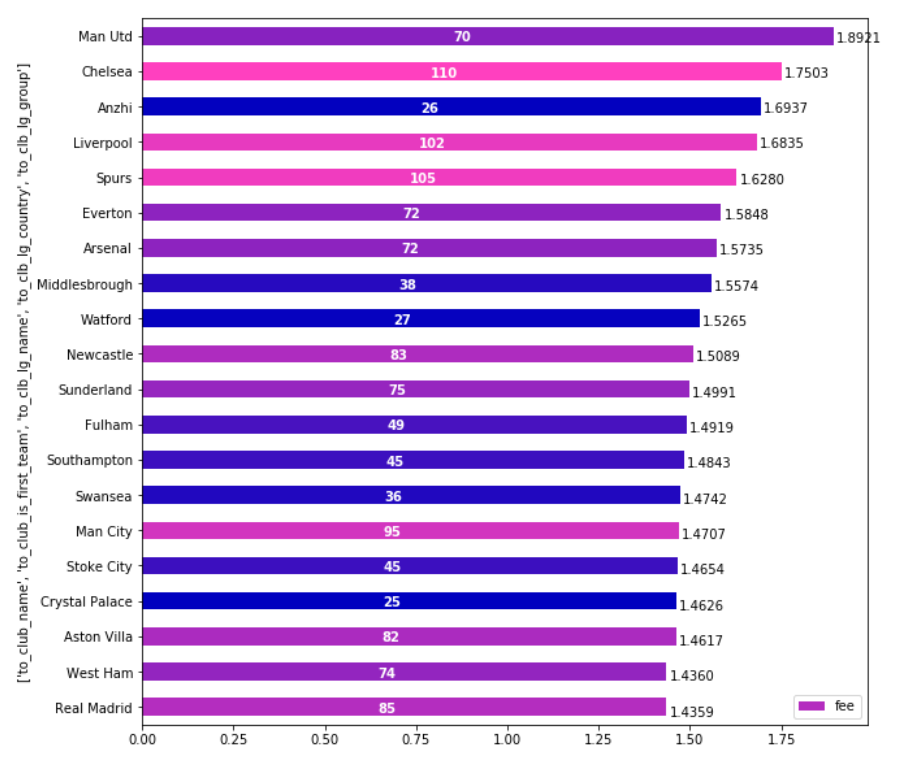
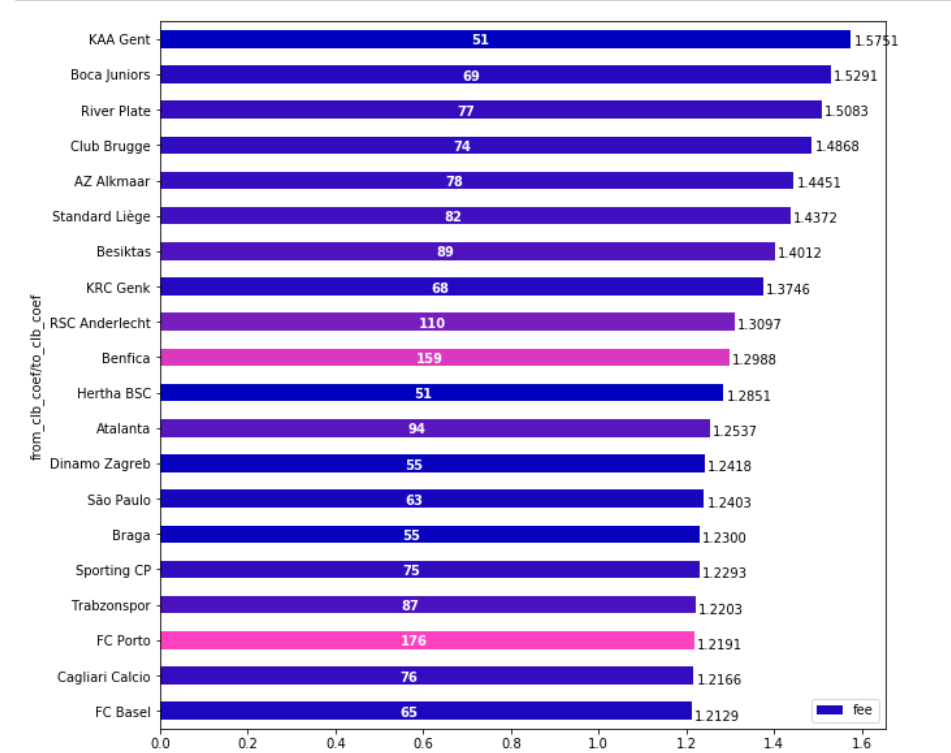
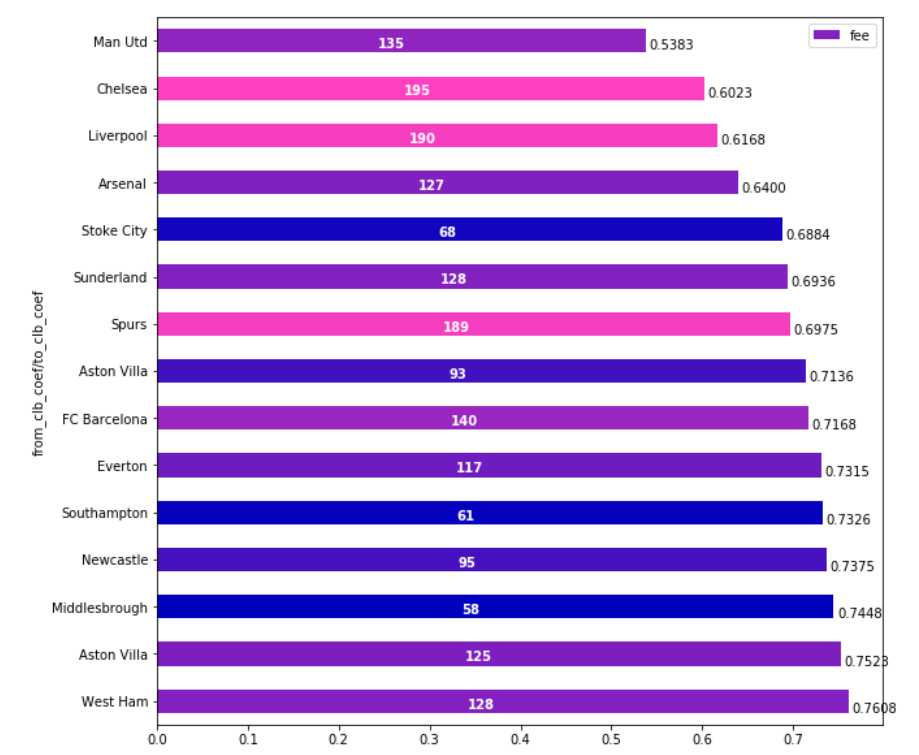
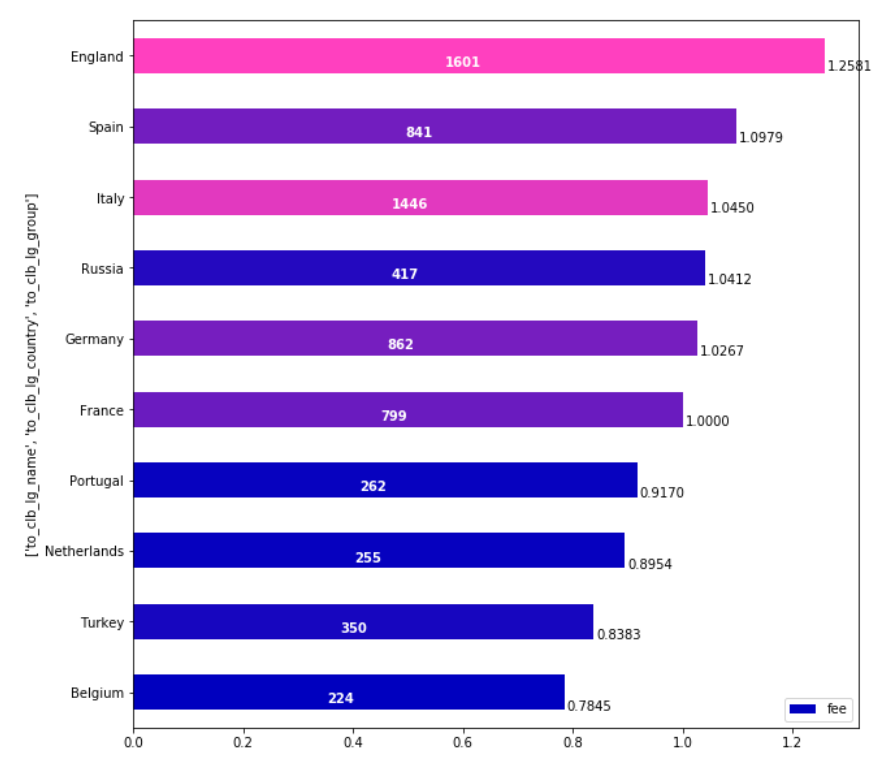
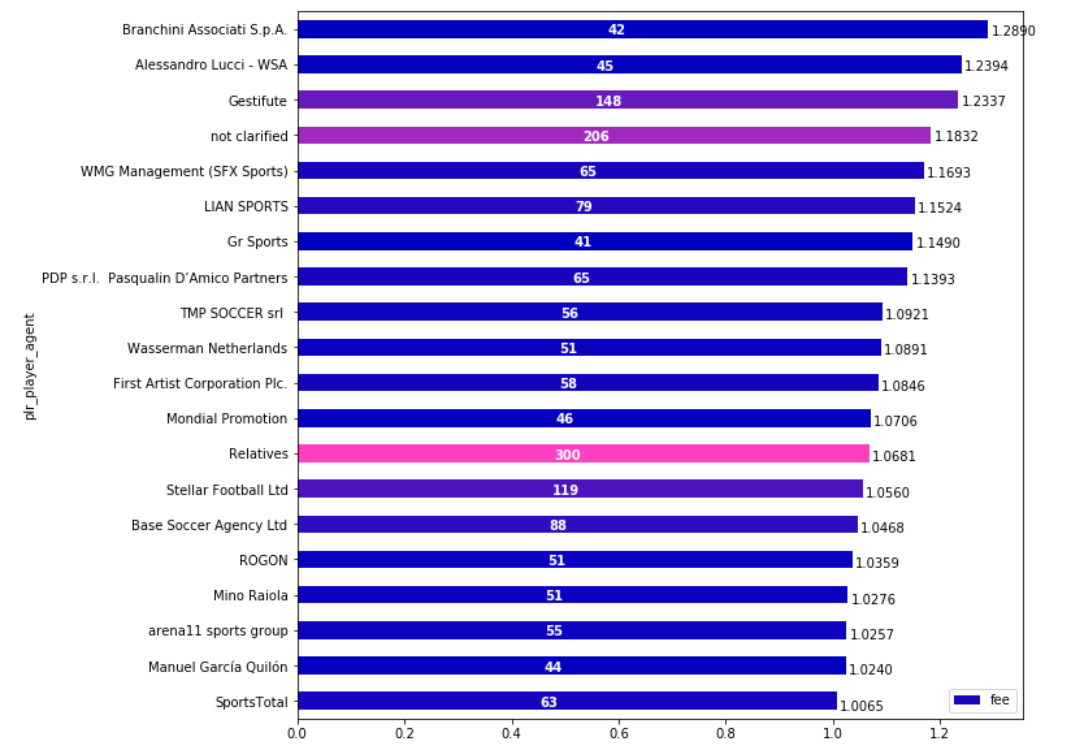
As I realized that I’m not able to make article in English out of my experiments (if anyone would like to be a coauthor to make one I will be grateful), I’ve decided to show it as a post at least.
Most of the techniques how to use Feature Importance (FI) and Partial Dependence (PD) in fastai I’ve described in this post. Here I’ve summarised and refactored all the specific code.
Intentions
Number of mounths ago I’ve made some functions to implement Feature Importance and Partial Dependence for fastai tabular models (as Jeremy suggested in his Machine Learning for Coders course). To be really sure that my approach does work I had to find the area of my own expertise that is open (so no data from my job) and can appeal to wide audience as, to my mind, best way to ‘sell’ a technique is to show it in a good example.
The search took some time, but as soon as I have found this amazing set of football transfers data, I knew this was it. This data contains wide variety info on (European) football transfers of 2008-2018. So I’ve made my choice.
Unfortunately I’ve no insights how to make a link directly to a cell in a notebook on github. So, in addition to the link, I will provide cell execution order number. I realize that it’s much less than ideal, but it’s the only way I could think of.
Model
The first step in making FI and PD is creating a model (tabular NN-model in our case). In fact, as Jeremy said, it is not have to be ideal to do the job. But nevertheless I’d like to have some anchor point to compare with.
In terms of football transfers there is only one acknowledged source its transfermarkt.com Fortunately it not only have what they call ‘market value’ of each major player, but it also tracks this value so anyone can compare it with the real transfer money this player was payed at that particular time. I am aware that transfermarkt doesn’t claim ‘market value’ to be the real transfer value in a particular situation with the particular clubs, but everybody use it that way and to be honest there are no other reasonable options.
So I’ve made a model in a pretty straightforward fastai-way. Not much to say here except:
- my depended variable (‘fee’) has been logorythmed down as usual
- the fact that I’ve tried many variants of hyperparameters in other notebooks and stick to the ones that fit well
- I’ve used some exotic exp median absolute percentage error as my accuracy meter. Why is that? It’s just the mathematical formula of my intentions what good transfer accuracy should say. For me it’s the answer for a question: what percent most probably (median) will my mistake of fee be if I would try to predict it with a model
- I’ve used Median Absolute Error as my loss function as it is closer to my accuracy function. Also I don’t really want to use MSE here as it prefer to fix the extreme cases more (because of the square). And it the case of very limited number of features (transfer value is hugely depended on the things that are outside of the data) we would have a lot of outlines and this is fine
So that is the result?
The model predicts the outcome with (my weird type of) error of 35%.
(Remember its exp_mmape we are talking about and it was calculated along the samples all over the 2008-2018 period not for lastX records as we would test it in case our goal will be to predict, not to analyze).
Ok, how good is that?
I’ve made a separate notebook to calculate that. And the final score is the following
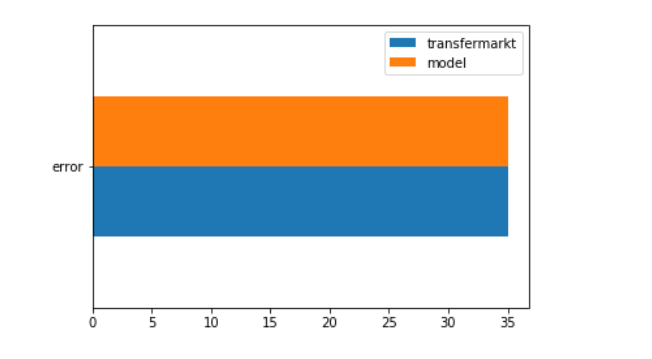
transfermarkt error is 35%
my model error is 35%.
To be honest it’s very weird that error is the same. I still have a feeling that I miss something (even though I’ve checked it a number of times).
But the ultimate check that I did not mess it up and calculated the same thing 2 times is the fact that these predictions are independent.
I’ve averaged prediction from model and transfermarkt and got an error of 32%
Nice so far.
I just want to stop for a second and think about that fastai is capable of.
I’ve found some data of football transfers, put it directly to tutorial-like approach and got the same results as multimillion-site, that is powered by crowd effect as well as by best experts in the field. I also want to mention that these experts work on much more wide data that is not available for the model (which knows nothing about football, transfers and etc.). And yet result is the same. (And if we take into account that model can also predict the loans, it performs even better).
That concludes my fist post as it is already pretty big. I will continue with Feature Importance, Partial Dependence, feature closeness and etc. in a couple of next posts (I will add some blank post for it).