I’d like to experiment with using FocalLoss on an imbalanced multiclass problem. Here the activation function would be softmax rather than sigmoid. As a first step I have implemented the following as a test to simply replace the standard cross entropy loss. I expected it to produce the same or similar results to the default but the behavior is different…
def one_hot_embedding(labels, num_classes):
return torch.eye(num_classes)[labels.data.cpu()]
class myCCELoss(nn.Module):
def __init__(self):
super(myCCELoss, self).__init__()
def forward(self, input, target):
y = one_hot_embedding(target, input.size(-1))
logit = F.softmax(input)
loss = -1 * V(y) * torch.log(logit) # cross entropy loss
return loss.sum()
learn.crit = myCCELoss
Applying this to a multiclass problem by setting learn.crit = myCCELoss I expected to get the same or similar behavior… I indeed get similar results during training but there are two major differences
1a) the calculated loss is much higher than normal
1b) the learning rate has to be much lower
I get very similar results to using the default loss function but…
2) when unfreezing the net to train all layers the math appears to blow up and fail.
1: Here is the output using the default loss function
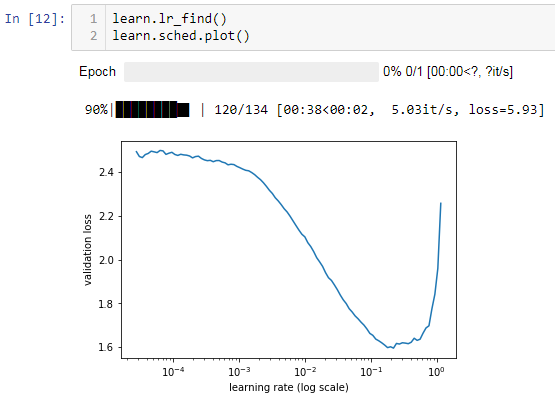
and here when restarting but using myCCELoss instead:
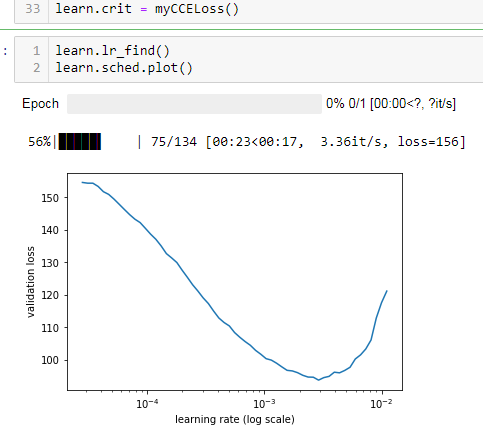
Note how much higher the reported loss is and how much lower I have to set the learning rate… (i used 0.002 vs 0.01)
In both cases I train on the same single fold of my data and end up with very similar accuracy and confusion results but the losses during training are always much higher.
here is trainig using the default loss function:
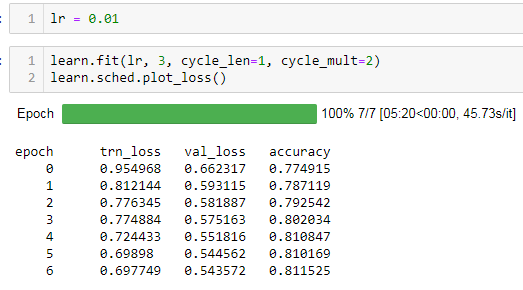
and here using myCCELoss:
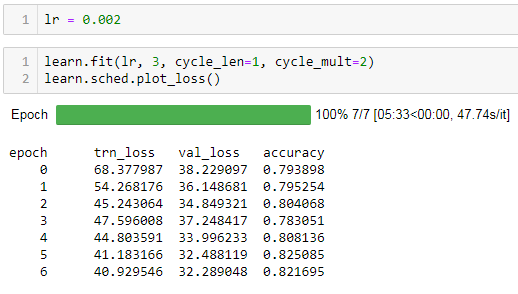
Given that the accuracies and confusion matricies are very similar the loss function appears to be working. however when i unfreeze the model (exact same code in both cases) the regular code version works as expected but the one using myCCELoss fails with nans.
Here is the output from default loss function:
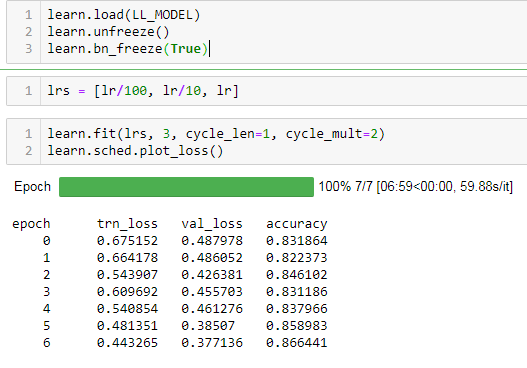
and again using myCCELoss:
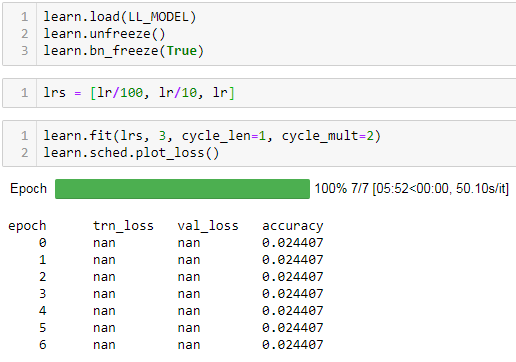
What is wrong with myCCELoss? What am I missing?
Thanks for any help!
note for FocalLoss I should just need to scale the loss by:
loss = loss * (1 - logit) ** gamma