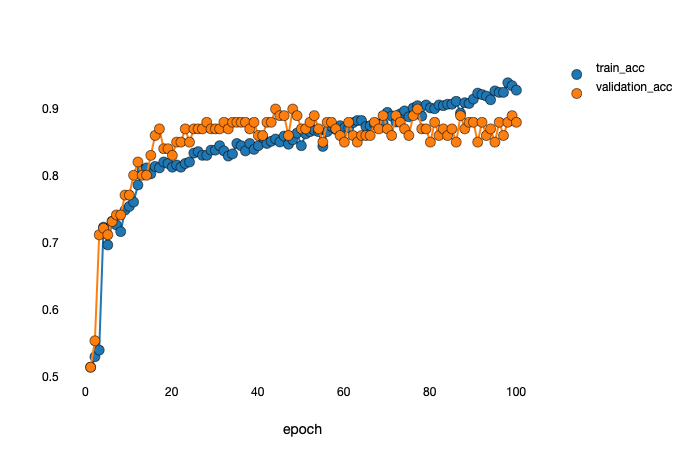
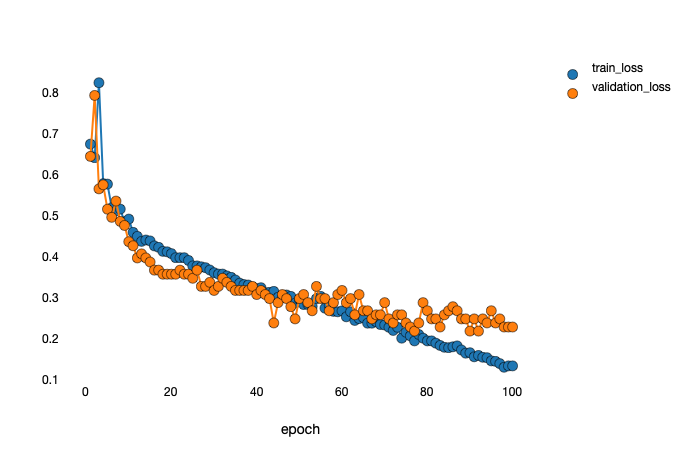
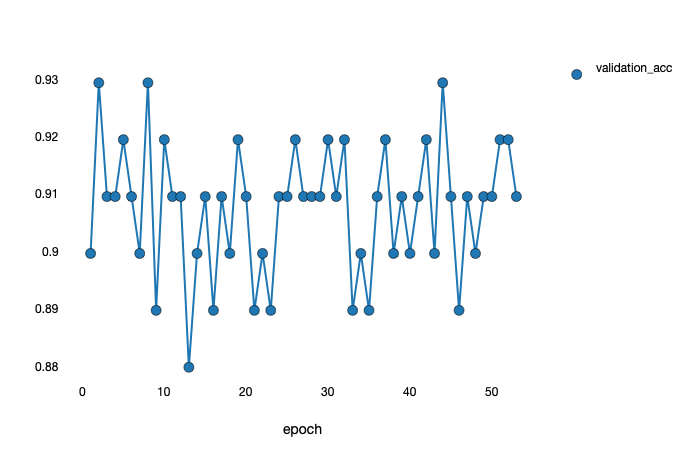
I thought the parameters of epoch 44, is the best one. Then I loaded the parameters of epoch 44.
After that, I tried to predict the same data set to observe the performance of the model.
Originally, I thought that the prediction result of the model would always be the value of epoch 44.
In my opinion, it’s just like getting the value of y = f(x) .
The f is just like the frozen parameter model; the x is just like the data set here.
But in fact, the performance of the model is fluctuating within a certain range like:
Yeah, that looks normal. Note the scale, it’s only fluctuating in a pretty small range (only the last couple of epochs are in that range, so it’s preserved the final accuracy).
You’re missing the fact that f(x) may not be a deterministic function. There are various options to remove (or at least reduce) the non-determinism of PyTorch operations. However I’d consider why you really want to do this. A lot of people seem to want to eliminate all non-determinism, but I’d tend to say if your results are going to vary a lot based on the non-determinism then this is something you should know, not hide. This may indicate issues with your model. Here performance looks stable so no issues.
In terms of the sources, of non-determinism I’m not quite sure exactly how you generated those graphs (are you just running validate repeatedly?) to know exactly what will be in play. One thing is that even when frozen fastai will update batchnorm layers. Not sure if this will be disabled given it’s looks like you’re running against the validation set.I suspect they will not update as the model should be in eval mode but could be wrong. They shouldn’t update at inference time (I’d imagine as you may feed weird batches you don’t want to update based). But validation is a bit different. Most other major sources of randomness should have been eliminated. Augmentation should be off (unless you added specific validation set augmentations) and the validation set shouldn’t be shuffled.
But there’s still some inherently random parts of PyTorch operations. Generally minimal but enough to lead to slight fluctuations. One thing that no setting in PyTorch will eliminate is differences due to floating point evaluation order. Strictly speaking floating point operations are not commutative (i.e. a+b does not always equal b+a). Only at a very low level, tiny differences not big ones, but an NN can easily amplify such small differences (so still fairly small but big enough to create those sorts of fluctuations fluctuations). Without severely impacting performance (and complicating code) these can’t be eliminated for various operations.
So not quite sure where the variation is coming from but looks normal and I wouldn’t try and eliminate it (though some do and a search on PyTorch non-determinism will show you things to minimise it if you really want).
What I want to do is that, train a CNN model and use it as a feature-extract-tool.I mean, for a specific image, there must be a deterministic feature values.
In my opinion, in PyTorch, model.eval() is needed when verifying the performance of a model. It make the Dropout layer and Batch Normalization does not work. So I used it, and my model is like:
class Model(nn.Module):
def forward(self, input_image):
out = self.conv_1(input_image) # 20 * 44 * 44
out = self.pooling_1(out) # 20 * 22 * 22
out = self.conv_2(out) # 50 * 16 * 16
out = self.pooling_2(out) # 50 * 8 * 8
out = self.conv_3(out) # 500 * 2 * 2
out = self.pooling_3(out) # 500 * 1 * 1
out_relu = F.relu(out)
out = F.dropout(out_relu)
out = self.conv_4(out) # 2 * 1 * 1
return out
I say, the modle will be as determinismf(x) after model.eval().
I set model shuffle=False, so I guess there is no connection with this. data_loader_validation = DataLoader(data_validation, batch_size=args.size_batch, shuffle=False)
Not it’s not the order of batches, it’s the order of instructions within even a single CUDA kernel. According to the PyTorch docs on this the non-determinism in forwards looks to be mostly in things you don’t seem to be using. But not sure this is an exhaustive up-to-date list. They do note non-determinism in the backwards of pooling and padding which you are using. Backward operations shouldn’t affect eval, but perhaps this has changed in more recent versions. Pooling seems like the sort of thing that may well use atomic operations in forward and more recent GPUs have significantly improved performance here so the use may have been expanded in more recent versions.
I’m not sure that relying on exact matching on network output is a very good method to use. I’d say you are pretty likely to run into other problems even if you resolve the particular issue here. While you may get determinism by changing some options, I’m pretty sure you’ll find differences in outputs between devices, so you won’t be able to mix CPU and GPU results or even mix GPU models which will limit scalability if you intend to use this in production. There’s also no guarantees of determinism between versions so you won’t be able to update anything without invalidating all stored features. And the list here likely goes on.
I’d look at how other feature-based matching/search systems work. You probably want some sort of K Nearest Neighbours or similar (KNN is more for search where you just want the closest, if matching you likely want some sort of threshold). I could be wrong but I can’t see exact matching ever being reliable.