I’m training a custom model (CNN) for multi-label classification and keep running into the exploding gradient problem. At a high-level, it’s convolutional blocks, followed by batch-normed residual blocks, and then fully-connected layers. Here’s what I’ve found so far to help people who might experience this in the future:
Redesign the Network: MLMastery says that reducing batch size and and removing layers may help. Removing 18 of the 19 ResBlocks and dropping batch size to 64 had no effect for me.
Batch Norm: helps smooth the gradients. Already in place in the different blocks.
Mixed Precision Training: Per the fastai documentation, when training with fp_16:
Your activations or loss can overflow. The opposite problem from the gradients: it’s easier to hit nan (or infinity) in FP16 precision, and your training might more easily diverge.
Code sample (below):
fp16 = MixedPrecision()
learn.fit(..., cbs=[GradientClip,fp16])
While the page says “we don’t fully train in FP16 precision”, is this just for MixedPrecision callback or when using fp_16 too?
Gradient Clipping: To implement this, I added GradientClip(.3) as a callback to the model. In different blog posts on this issue, people talk about gradient norm scaling and gradient value clipping all under the header of gradient clipping.
While there is a fastai GradientClip, I couldn’t find a gradient norm scaling - did I miss it somewhere?
Weight Regularization: Add a L1 or L2 penalty to the loss function to penalize exploding gradients. Fastai’s Adam uses weight decay by default. Calling Fastai has its own implementation of Adam , where decouple_wd=True (default) gives you weight decay, while setting it to False gives you L2 regularization. Try: learner(... opt_func = partial(Adam, decouple_wd=False) for L2 regularization.
Initializations: People have written on Kaiming initializations to ensure that the initial tensors don’t explode or vanish, but the math scared me away from trying to implement it. Is there a pre-done code sample for how to use with fastai?
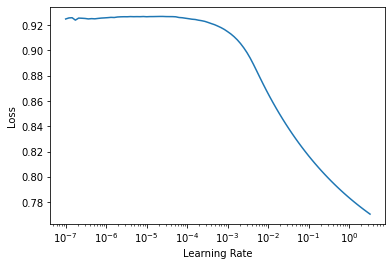
For context, here are some graphs about the gradient explosion for the model. Any recommendations to try out or obvious things jump out? I truly appreciate all suggestions and help!
LR Finder: It looks off visually. Does the fact that it doesn’t increase close to 10e0 mean anything?
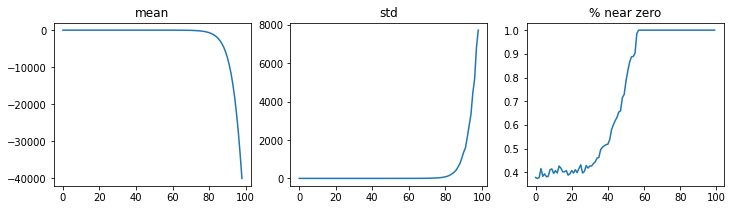
Activation Stats: It dies right as the gradient of the layer before explodes just 80 steps in. For reference, it predicts only predicts outputs as one class (the training sizes are balanced), scoring Precision: 0.88, Recall: 1.00 in that arbitrary class, and Precision: 0.00, Recall: 0.00 in all others.
Looking at the activation stats with learn.activation_stats.color_dim(-1), we see:
Final Layer:

Penultimate Layer:
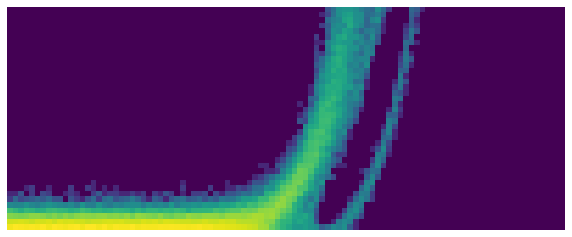
The layers before similarly ‘explode’ too. Any ideas jump out?