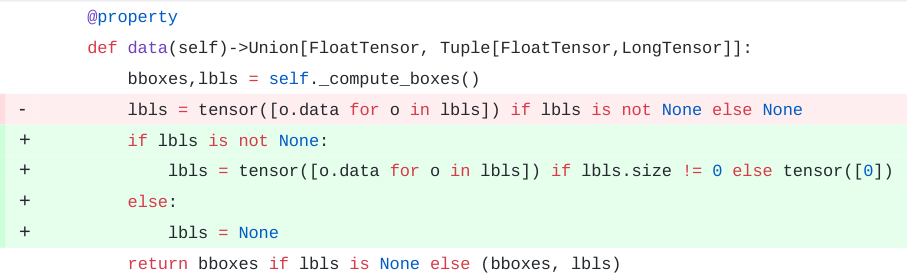
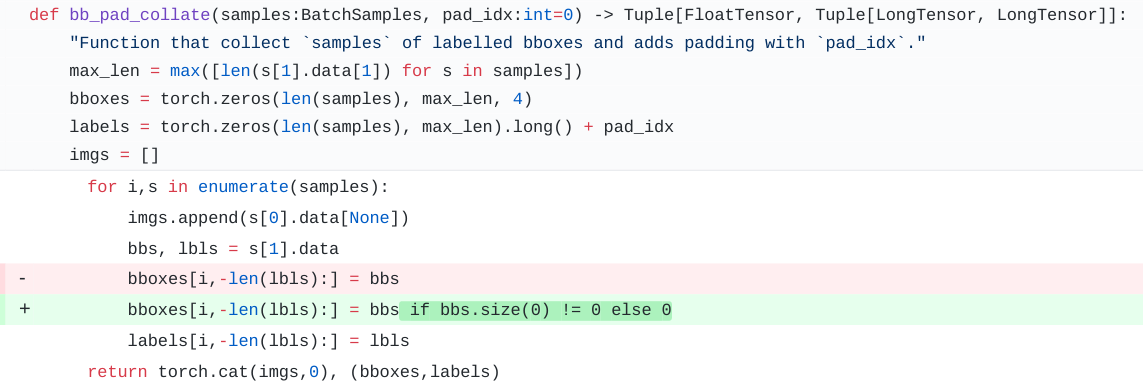
@dhpollack @pietro.latorre
Sorry it took me so long to get back to this thread. I finally got back to it and got single bounding box detection working. Here’s some code:
from fastai.vision import *
from fastai.vision.learner import cnn_config, num_features_model
This is just changing create_cnn to only output 5 values. (bbox and whether the object is detected in the image)
def create_single_bbox(data:DataBunch, arch:Callable, cut:Union[int,Callable]=None, pretrained:bool=True,
lin_ftrs:Optional[Collection[int]]=None, ps:Floats=0.5,
custom_head:Optional[nn.Module]=None, split_on:Optional[SplitFuncOrIdxList]=None,
bn_final:bool=False, **learn_kwargs:Any)->Learner:
"Build convnet style learners."
meta = cnn_config(arch)
body = create_body(arch, pretrained, cut)
nf = num_features_model(body) * 2
# The only line that changed is blow here
head = custom_head or create_head(nf, 5, lin_ftrs, ps=ps, bn_final=bn_final)
model = nn.Sequential(body, head)
learn = Learner(data, model, **learn_kwargs)
learn.split(ifnone(split_on,meta['split']))
if pretrained: learn.freeze()
apply_init(model[1], nn.init.kaiming_normal_)
return learn
This is a hack to make reconstruct work from the above defined network.
class MyObjectCategoryList(ObjectCategoryList):
def reconstruct(self, t, x):
if not isinstance(t, list):
t = [t[0:4].view(-1, 4), (t[-1].view(-1, 1) > 0).long()]
(bboxes, labels) = t
if len((labels - self.pad_idx).nonzero()) == 0: return
i = (labels - self.pad_idx).nonzero().min()
bboxes,labels = bboxes[i:],labels[i:]
return ImageBBox.create(*x.size, bboxes, labels=labels, classes=self.classes, scale=False)
My problem was from a medical dataset. The csv was just two columns with filenames and a string of four values for the bounding box. If the box is ‘0 0 0 0’ in image, I give it a background class. More on that in a second. I use a weird loss function to deal with that.
df = pd.read_csv(PATH / 'bb.csv')
d = {Path(k).name: [float(i) for i in v.split(' ')] for k, v in zip(df['scan id'], df['bb'])}
def get_heart_y(o):
y = d[o.name]
if all([i == 0 for i in y]):
return [[y], ['background']]
else:
return [[y], ['left atrium']]
Following how the docs do object detection from coco, I do almost the same thing except use a different label_cls. (While also using correct path and splitting functions.)
db = ObjectItemList.from_folder(PATH / 'scan-slice-128')
db = db.split_by_valid_func(lambda x: int(x.stem) < 1907)
db = db.label_from_func(get_heart_y, label_cls=MyObjectCategoryList)
db = db.transform(get_transforms(), tfm_y=True)
db = db.databunch(bs=16, collate_fn=bb_pad_collate)
The last challenge was the loss function. The logic here is essentially, if there is a bounding box of ‘0,0,0,0’, don’t include the regression error in the loss. And also add a binary cross entropy loss for the class of interest. (Use a cheap hack where I use target values of 0s and 1s to mask away bbox losses if I don’t want them.)
def single_bbox_loss(preds, bboxes, targs):
pred_bboxes = preds[:, :4]
pred_targs = preds[:, -1]
bbox_loss = F.smooth_l1_loss(pred_bboxes, bboxes[:, 0, ...], reduction='none').mean(dim=-1)
bbox_loss = (bbox_loss * targs[:, 0].float()).sum() / targs.sum().float()
binary_loss = F.binary_cross_entropy_with_logits(pred_targs, targs.flatten().float())
return bbox_loss + binary_loss
And that’s it. plug into a learn object and let it go. Hooking things up to more classes in a real Yolo type network should be pretty easy. I did a lot of silly things just to make the problem go faster, but it was a quick way for me to get it to work. Most of the code is just hijacking current fastai functions.
learn = create_single_bbox(db, models.resnet34, loss_func=single_bbox_loss)