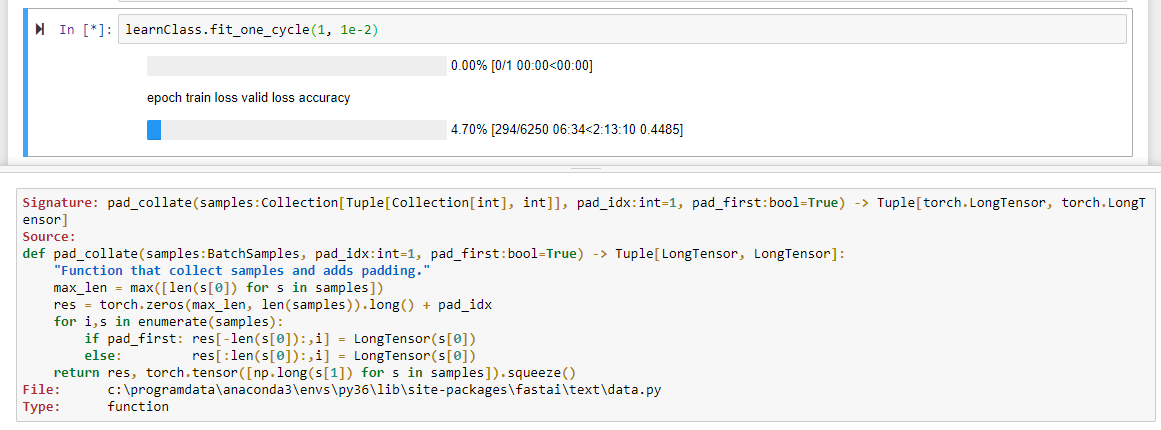
I really don’t know where this thread should be placed - hopefully in the right place. Basically, I’m trying to reproduce lesson 10 using fastai v1 code, and I got an error when running a fit_one_cycle on the classification model that reads:
RuntimeError Traceback (most recent call last)
<ipython-input-8-fd76aff41bb9> in <module>()
----> 1 learnClass.fit_one_cycle(1, 1e-2)
C:\ProgramData\Anaconda3\lib\site-packages\fastai\train.py in fit_one_cycle(learn, cyc_len, max_lr, moms, div_factor, pct_start, wd, **kwargs)
16 cbs = [OneCycleScheduler(learn, max_lr, moms=moms, div_factor=div_factor,
17 pct_start=pct_start, **kwargs)]
---> 18 learn.fit(cyc_len, max_lr, wd=wd, callbacks=cbs)
19
20 def lr_find(learn:Learner, start_lr:Floats=1e-5, end_lr:Floats=10, num_it:int=100, **kwargs:Any):
C:\ProgramData\Anaconda3\lib\site-packages\fastai\basic_train.py in fit(self, epochs, lr, wd, callbacks)
136 callbacks = [cb(self) for cb in self.callback_fns] + listify(callbacks)
137 fit(epochs, self.model, self.loss_fn, opt=self.opt, data=self.data, metrics=self.metrics,
--> 138 callbacks=self.callbacks+callbacks)
139
140 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
C:\ProgramData\Anaconda3\lib\site-packages\fastai\basic_train.py in fit(epochs, model, loss_fn, opt, data, callbacks, metrics)
89 except Exception as e:
90 exception = e
---> 91 raise e
92 finally: cb_handler.on_train_end(exception)
93
C:\ProgramData\Anaconda3\lib\site-packages\fastai\basic_train.py in fit(epochs, model, loss_fn, opt, data, callbacks, metrics)
77 cb_handler.on_epoch_begin()
78
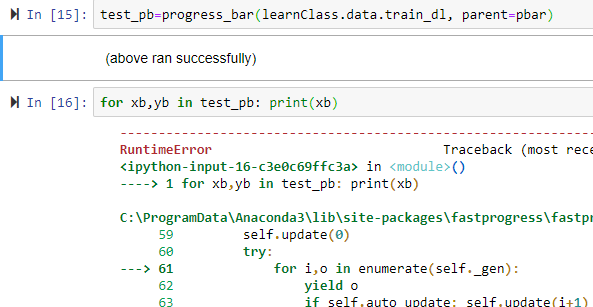
---> 79 for xb,yb in progress_bar(data.train_dl, parent=pbar):
80 xb, yb = cb_handler.on_batch_begin(xb, yb)
81 loss = loss_batch(model, xb, yb, loss_fn, opt, cb_handler)[0]
C:\ProgramData\Anaconda3\lib\site-packages\fastprogress\fastprogress.py in __iter__(self)
59 self.update(0)
60 try:
---> 61 for i,o in enumerate(self._gen):
62 yield o
63 if self.auto_update: self.update(i+1)
C:\ProgramData\Anaconda3\lib\site-packages\fastai\data.py in __iter__(self)
50 def __iter__(self):
51 "Process and returns items from `DataLoader`."
---> 52 for b in self.dl: yield self.proc_batch(b)
53
54 def one_batch(self)->Collection[Tensor]:
C:\ProgramData\Anaconda3\lib\site-packages\fastai\data.py in __iter__(self)
50 def __iter__(self):
51 "Process and returns items from `DataLoader`."
---> 52 for b in self.dl: yield self.proc_batch(b)
53
54 def one_batch(self)->Collection[Tensor]:
C:\ProgramData\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py in __next__(self)
334 self.reorder_dict[idx] = batch
335 continue
--> 336 return self._process_next_batch(batch)
337
338 next = __next__ # Python 2 compatibility
C:\ProgramData\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py in _process_next_batch(self, batch)
355 self._put_indices()
356 if isinstance(batch, ExceptionWrapper):
--> 357 raise batch.exc_type(batch.exc_msg)
358 return batch
359
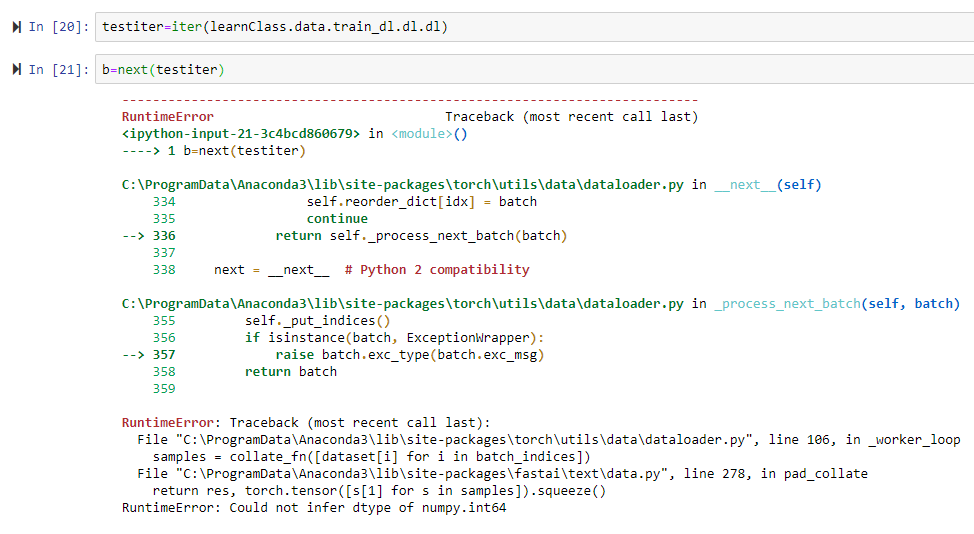
RuntimeError: Traceback (most recent call last):
File "C:\ProgramData\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 106, in _worker_loop
samples = collate_fn([dataset[i] for i in batch_indices])
File "C:\ProgramData\Anaconda3\lib\site-packages\fastai\text\data.py", line 278, in pad_collate
return res, torch.tensor([s[1] for s in samples]).squeeze()
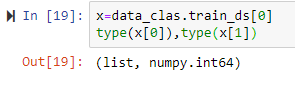
RuntimeError: Could not infer dtype of numpy.int64
Context:
I want to run a classification model on complaints text using fastai. I have watched all part 1 videos and a few from part 2, namely lesson 10. I am attempting to reproduce the IMDb classification model in lesson 10 using fastai v1, and tried to follow documentation as well as reading through python code (I’m a beginner in Python unfortunately). I’ve chosen to use slightly different variable and file names so I’m not successfully reproducing as a pure fluke. I have managed to successfully build my language model, create a data bunch for the classification model, and load my encoding from the language model (side note: I think the documentation can be much better, it was quite painful for me to ultimately get here). The next thing was to start training but I got stuck.
Code:
The point where I hit the error was here:
learnClass.fit_one_cycle(1, 1e-2)
The learner is created by
‘learnClass = RNNLearner.classifier(data_clas, drop_mult=0.5)
learnClass.load_encoder(‘lm_enc’)’
data_clas was created by the following code:
data_clas = TextClasDataBunch.from_df(path=ClassPath,train_df=TrainDF,valid_df=TestDF,vocab=data_lm.train_ds.vocab,bs=8,classes=Classes,n_labels=1)
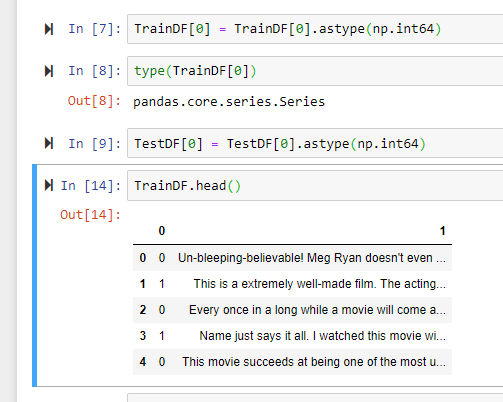
The source data was a dataframe where the first column had the labels and the second column had the review text. The labels are all 0 and 1 representing ‘neg’ and ‘pos’ respectively.
ClassPath = Path('C:/Jupyter/Class')
TrainDF = pd.read_csv(ClassPath/'train.csv', header=None)
TestDF = pd.read_csv(ClassPath/'test.csv', header=None)
Classes = ['neg','pos']
Please help me understand why this is happening and how to move forward.