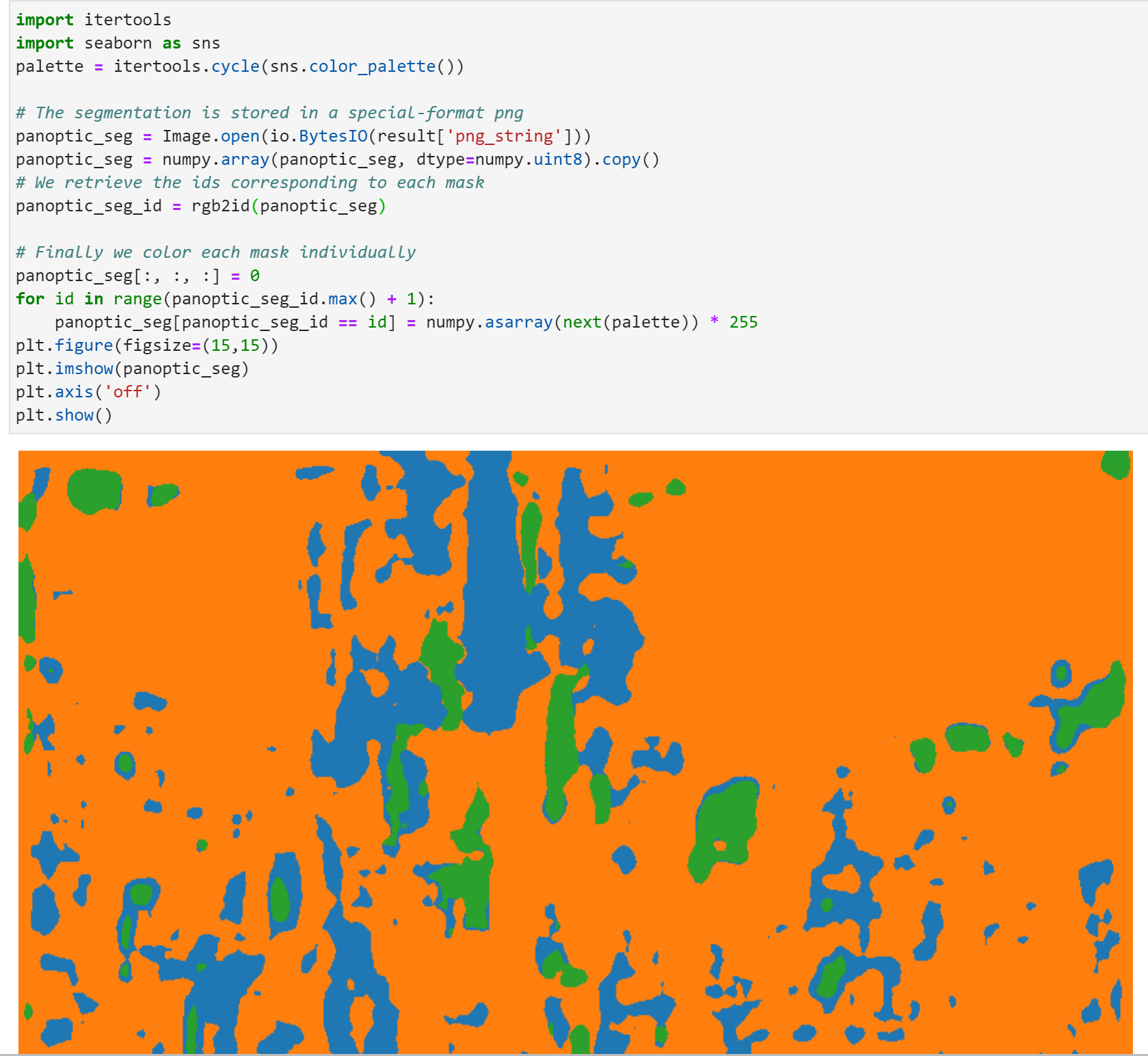
I have recently been looking into DETR https://arxiv.org/abs/2005.12872v3, which uses a Transformer architecture to vastly simplify object detection, and am starting to experiment with finetuning it on a custom dataset.
After browsing the forum, I found a promising starting point in the shape of a colab notebook from @LessW2020 at https://github.com/lessw2020/training-detr, but this appears to still be a WIP, so I was wondering if anyone else has been experimenting with this and if they have had much success with it?
Also, the approach in the colab notebook appears to download and use the trained weights directly as opposed to using the pretrained model from torchhub (torch.hub.load(‘facebookresearch/detr’, ‘detr_resnet50’, pretrained=True)). Am I correct in thinking that an equivalent alternative would be to replace the class_embed and box_embed layers in the pretrained model?
Hi @Chris-hughes - I don’t think it would matter if you download the weights vs the pytorch hub model, they are the same thing in the end.
To your question, you can just remove/replace the class_embed layer and reset to your desired num_classes.
In the github thread on the topic, alcinos never mentioned touching the box_embed layers and I and others have had success via only modding the num_classes, so seems no need to reset the box_embed.
(but you could certainly test and compare with/without as a good experiment).
I’ll continue to finish the colab but need to find a good public dataset to run with and currently pretty loaded up with work items (fortunately using DETR everyday for work now).
Hi @Chris-hughes - I’m trying the same thing - had stumbled across the Issue#9 thread but then got stuck. I just found this which might be useful - I’m going to try it out.
That’s pretty much what I thought, good point about the box embed though, I suppose it is just the number of classes and the number of queries that should be modified. I am also interested to try out replacing the num_classes fc layer with a small network - just to give it a few more parameters when finetuning.
Also, really cool that you are using Detr at work! How have you found it to train generally, the batch size seems to be very low in most examoles? Do you just fine tune in the usual way, freezing the backbone and the criterion first? Additionally, have you had a chance to guage the performance on small objects, as I’ve read in a few places it suffers there slightly compared to efficientdet?
how did you get on? I got it training on my dataset but have not been able to extend that notebook from the one class (wheat) to the two classes (flakingPaint and wallCracks) that I have in my dataset. I made the change to the labels from all zeros as it was to a 0 for my first class and a 1 for my 2nd:
Hi Mark, I haven’t tried for more than one class yet unfortunately, but I think that is the error that pytorch throws when there is a dimension mismatch somewhere. Have you checked that the dimensions of the new labels are the same? I honestly can’t think of a reason why changing the vector wouldn’t work!