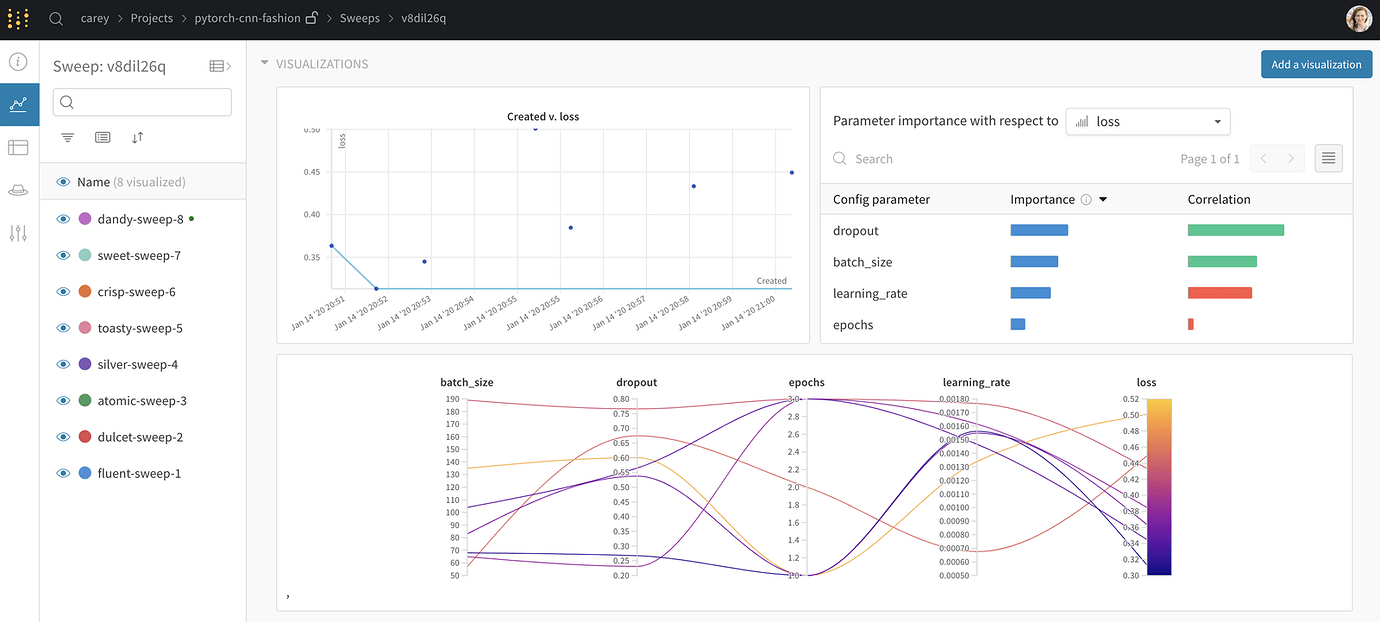
My friend @boris wrote this great callback to help measure how fastai v2 models are doing, and comparing all of them in one place to find the best one.
Would love any feedback on the tutorial or the callback! Here’s the accompanying colab.
My friend @boris wrote this great callback to help measure how fastai v2 models are doing, and comparing all of them in one place to find the best one.
Would love any feedback on the tutorial or the callback! Here’s the accompanying colab.
Just read it and can say I absolutely LOVE it  Super helpful for someone like me who wants to try out W&B after hearing about it for so long. Thank you so much @boris for a wonderful tutorial
Super helpful for someone like me who wants to try out W&B after hearing about it for so long. Thank you so much @boris for a wonderful tutorial
So glad you found it useful! If you have any trouble getting setup/have any questions, please don’t hesitate to ask.
Thank you for the callback! I am still learning to these features of WandB mostly due to not really having models that needed hyper parameter tuning. (single model run taking 1.5 weeks is a slow iteration time)
Being able to see gradients for fp16 training definitely helped with determining which layers were overflowing.
1.5 weeks, oh boy! What kind of models are you training?
Cycle GAN architecture on 2070 Supers(nvlink), with way too much gradient checkpointing,deallocation of memory, bs of 1, and passing of data between GPUs. This is the model: https://marii-moe.github.io/marii-blog/ugatit/fp16/gan/image%20generation/image%20to%20image/2020/06/11/UGATIT-a-GAN-in-fp16.html
I’ve been using this callback for all my v2 experiments (computer vision – images), and it is really good. It logs literally everything, and I almost never see the need to log anything separately to wandb.config like the v1 callback.
Great stuff @boris, thank you!
Hey! I just remembered one thing I ran into, and it might be something that would be worth thinking about. Even though the fp16 gradient were useful, it might also be a good idea to include the fp16 weights without loss scale. Since loss scale can change dramatically throughout training, the information about gradients without loss scale becomes incomprehensible. In my case it meant that their could be a ~2x difference between the scale of gradients every 100 iterations. (4000 vs 8000 dynamic loss scale)
I am pretty sure wandb grabs these during a backwards hook, while loss_scale is removed right before the optimizer step.