So I watched the first video and I wanted play around with something. I had already worked with Facial Expression Detection before, so I wanted to test it with resnet.
So I tried hard to train my model on the dataset directly. After multiple sessions of resnet34 and resnet50 (+/- unfreeze) the maximum accuracy I achieved was 50%.
When I plot top losses I find some images have problems like being blank etc. So I am trying to clean the data by running OpenCV DNN Face Detector on the dataset and removing those faces with confidence < 50%.
There are 28k images with 7 classes in here. Also the distribution of images in the classes is very bad. Do I need to take equal from each class to better train ? Or whole (cleaned) ?
I cleaned the dataset and about 3k images were removed. So I have 25k images left now.
The distribution is like this:
angry
disgust
fear
happy
sad
surprise
neutral
3577
401
3565
6645
3985
2946
4584
which has very less items of the class disgust. Any suggestion on what to do ? I trained the model now and it gives me a decrease of just 2% error rate, i.e earlier error was 50% ish and now its 48% ish.
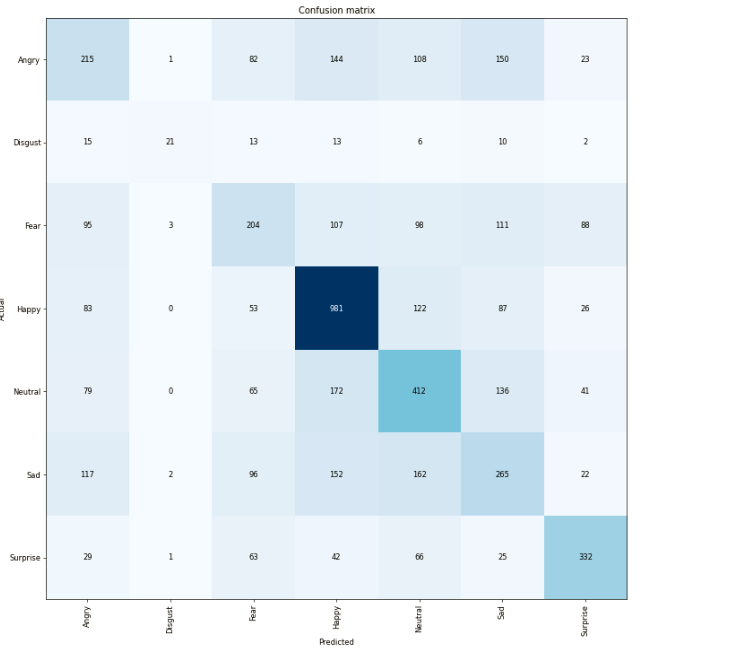
What does the confusion matrix look like?
Does your data after cleaning look decent?
Would you mind sharing your code, so we can see your model in more detail?
The data looks decent, at least no non face images(after the pre-processing). But there seems to be some problem with some of the labels. Like some labels look like they’ve been labelled wrongly I guess.
Top Losses:
I don’t understand what you mean by not being able to connect. Can you elaborate.
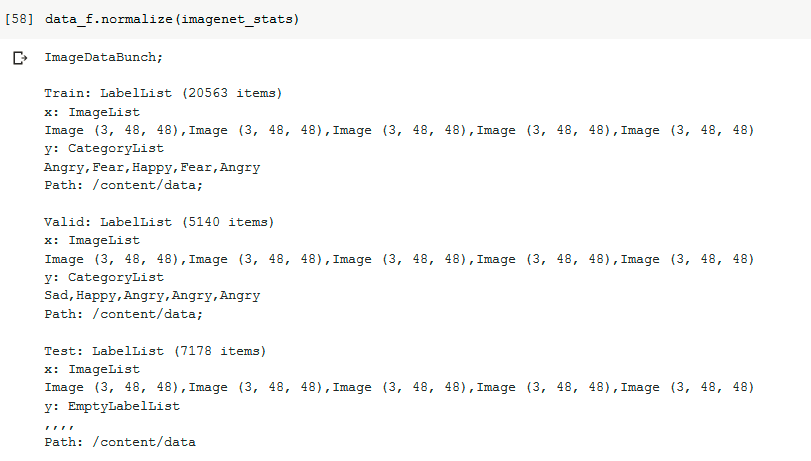
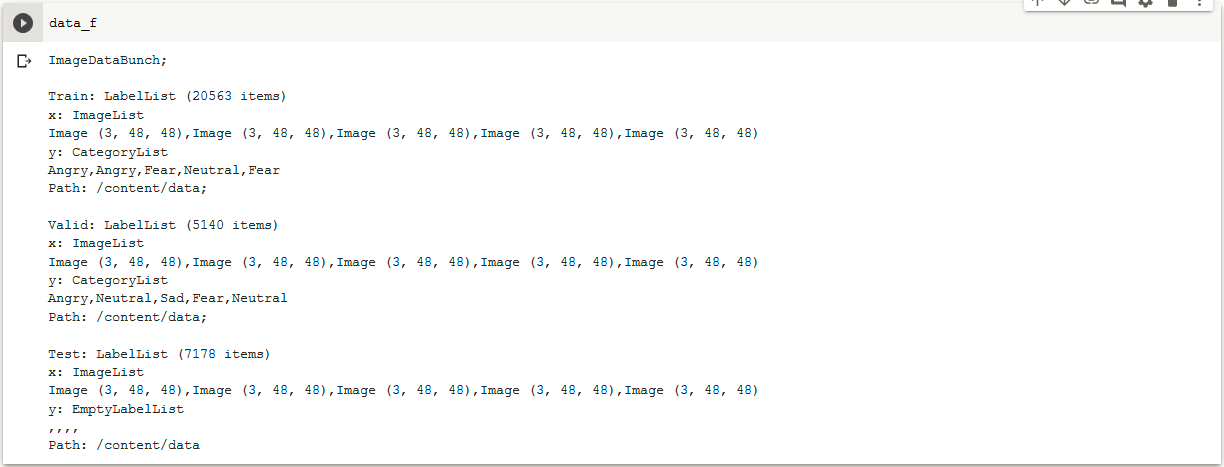
So when the data is split for training & validation, its split 70-30 or 80-20 but different classes are distributed equally right. That was my question. By labels, I meant classes.
But after some thought, I think that the Train in ImageDataBunch is just showing the labels for the first 5 images, not the classes which were given as input data.
In the ten cycles, the train_loss, val_loss and error_rate follow a pattern like - decrease very fast, slow down, stop, start increasing back. Thus, I thought that 10 epochs would be better or I could be facing overfitting.