Planning on playing around with this if folks are still competing? qq (and I think I know the answer already), but can we use the validation set as part of an unsupervised learning run? e.g. using the val images but not the val labels?
1 Like
I’d actually argue you can so long as it’s not labeled I believe, however if people disagree or feel that’s cheating then we won’t ![]() (Also don’t forget gang to update that 2nd post
(Also don’t forget gang to update that 2nd post ![]() )
)
1 Like
(still sticking to the 12k samples per epoch of couse)
1 Like
All right, this is going to be my first Kaggle style contest. Let’s do this.
1 Like
Oh, this could be fun  I’d love to see what some unsupervised pretraining could do.
I’d love to see what some unsupervised pretraining could do.
1 Like
My best so far (without looking at what you folks have done) has been ~62-64 %. Time to learn some new tricks now, looking at your notebooks.
1 Like
I tried a bunch of different architectures and techniques on this. I found that you can learn a lot on the various things people try, but it is hard to differentiate the usefulness of each method in the end. This is because we’re looking for the best architecture for 5 epochs of training in 12k samples, and not necessarily the best architecture for the data set. As a result, design choices good for 5 epochs may not be good choices for what one would use in practice, where the number of epoch training and samples are not limited.
I probably won’t spend much more time as I’m not sure the “best practices” for this challenge, for 5 epochs and 12k samples, transfers well to practical use. Happy to hear what other people think.
Otherwise, if anyone wants to team up for kaggle challenges. I’m happy to join, but I’m pretty new to it. :-]
2 Likes
Had a day playing around with the basics yesterday, best so far was 71.24% (2nd currently) with progressive resizing. Looking forward to getting a little more exotic in the coming days.
Interestingly using xresnet50 with cnn_learner to get the fastai head (first 5 experiments) didn’t improve accuracy at all, the default xresnet50 head worked fine, lr_find after 2e @ 128 and data switched to 224:
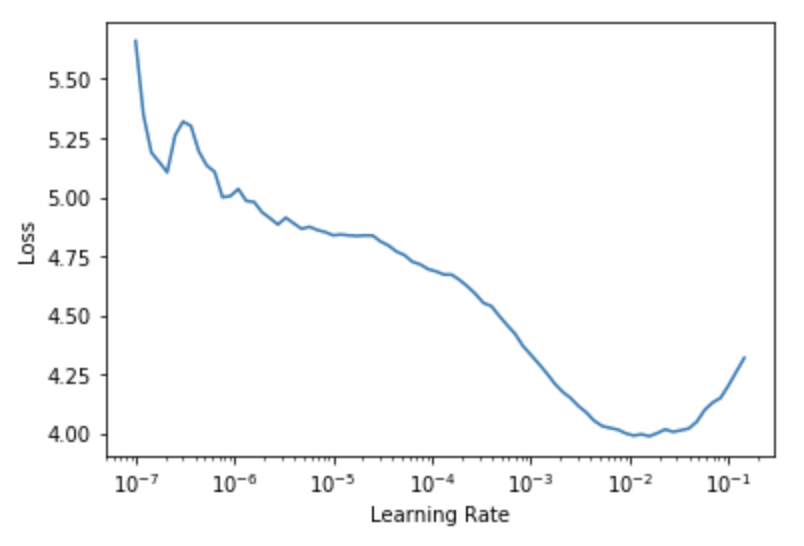
Also, when using progressive resizing I tried to tune the lrs for each stage, but when using a lr for the second stage (224) based on lr_find (2e-3), performance dropped markedly. The network preferred the original lr (1e-2) which would appear to be “too high” given the lr_find plot.

1 Like
Hey Morgan,
Just out of curiosity, do you have a script that runs through a bunch of different models, and then outputs that csv file? Or is it currently manually done?
Thanks - Daniel
Manual 
Current best result using a modified XSE-ResNeXt 50 based on the Imagenette XSE-ResNeXt with a custom (24,32,64) stem and GeM Pooling. Stem inspired by Ross Wrightman and GeM pooling by DrHB.
76.55% ± 0.25%: Notebook, second submission.
I also included just the (24,32,64) stem as Submission 1 which had an accuracy of 75.29% ± 1.09%. GeM required lowering the batch size from 64 to 56 with a P100.
Also tested a (24,48,64) stem, less augmentation, more augmentation, and bs=56 with AvgPool, all which scored worse.
6 Likes
Boom! Thats great! Maybe you could post your 2nd best solution on the leaderboard also? I’m thinking that it might help to see other high-performing methods, maybe we could allow/limit up to 2 entries per person on the leaderboard, what do you think @muellerzr?
1 Like
Just finished up a batch of experiments with xresnet50 and FixRess, the current top-performing ImageNet technique, no leaderboard progress however 
The idea is that training CNNs at a lower resolution than your test resolution can give better results. When training with the same resolution as the test set, the apparent size of objects in the train set will appear larger than in the test set, at least if you are using a transform like RandomResizedCrop. They address this by:
- Training at a lower resolution, e.g. train at 160, test at 224
- Fine-tune the classifier layer at the test image resolution
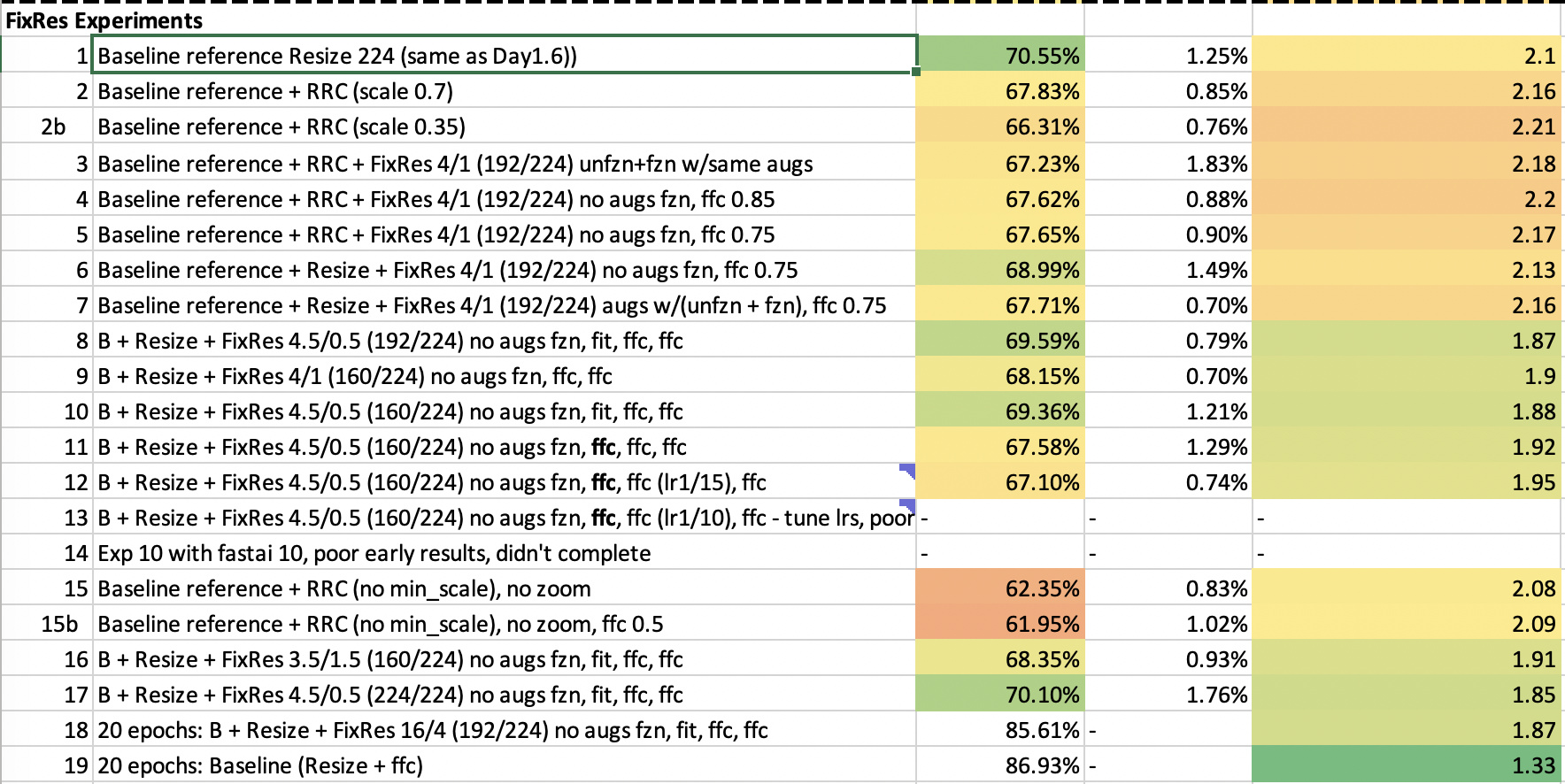
Probably it is a technique to squeeze out the last few % of performance and there are too few epochs in fastgarden to see its benefit. I did do 2 20 epoch runs out of curiosity with FixRes trained with 16epochs at 192 and fine-tuned (classifier layer only) for 4 epochs at 224, still it performed worse than a baseline run of 20 epochs at 224.
5 Likes
Sure, if you have another technique that could be interesting I’m thinking tag it to your highest-placed entry as perhaps interesting idea or something
1 Like
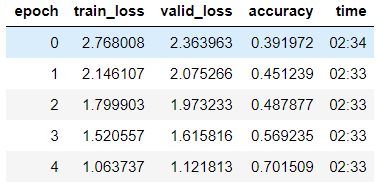
There’s a range of training times in the notebooks in this thread and I was curious to know what setup’s everyone was using. My training are definitely on the higher(slower) end compared to others.
Laptop (Windows, GTX 1060) > 6mins/epoch
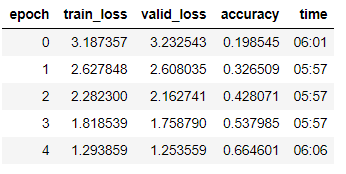
AWS (Tesla K80) ?> 7.40/epoch
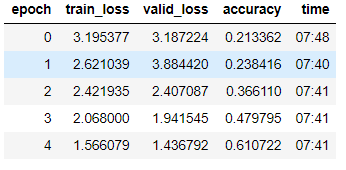
The above 2 notebooks are identical.
@morgan > 4.30/epoch
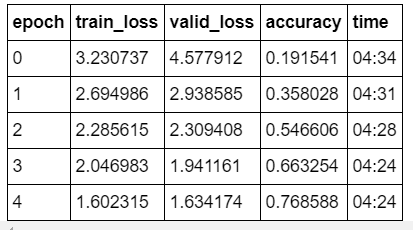
@radek > 1.40/epoch 
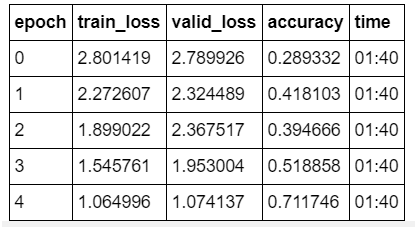
@muellerzr > 1.40/epoch (assuming colab)
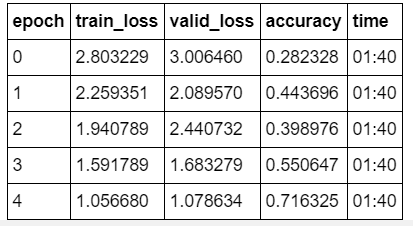
@rahulrav > 6mins/epoch
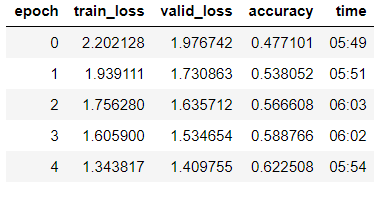
@jwuphysics >2min30/epoch
1 Like
Yes mine come from a T4 ![]()
1 Like
Using a 2080 RTX Max-Q on a Laptop (more like a 2070 RTX super for realz).
Some timings here are crazy fast. Maybe it’s time to use that Colab Pro subscription.
1 Like
Yes for sure time to look at a Colab subscription
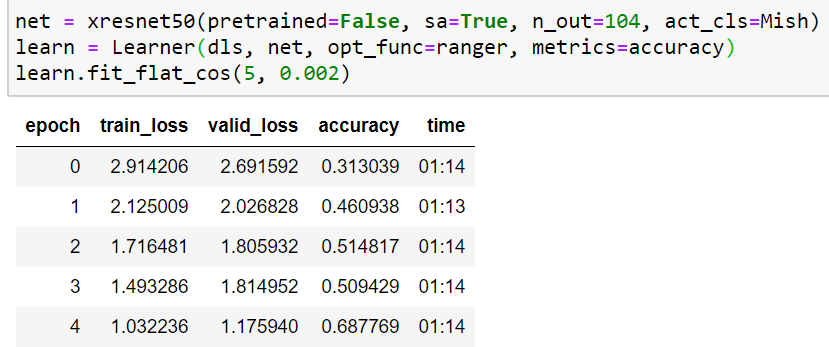
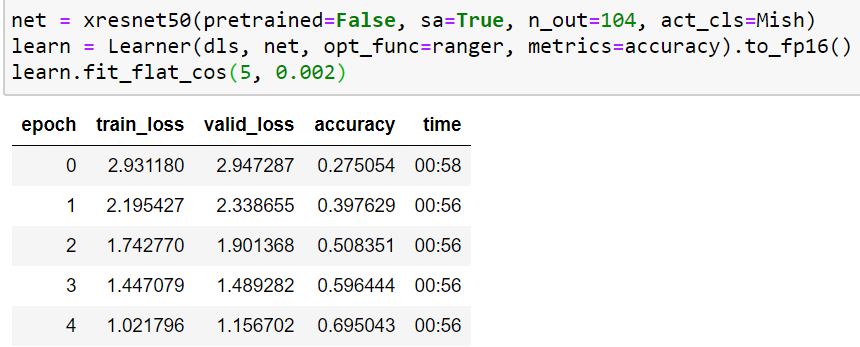
Here’s another data point for 2080 TI with/without fp16 (all settings similar to muellerzr except I change output classes to 104).
fp32
fp16
3 Likes
Wow! now that is fast!. Thanks for sharing. I was using a smaller bs in the original post due to memory issues which have now been resolved so higher bs brought my training times down but still no where near to this.