I should’ve led with this, but: thank you for setting this up! It’s a fun way for fastai veterans to get acquainted with the new library, with a little less pressure than a full Kaggle competition
***UPDATE:
Tried to figure this out. It seems like I get intermittent byte errors, and the wget freezes. To get the wget to restart itself after intermittent byte errors, I used the following line
!wget -T 15 -c “YOUR_URL” -O “flowers.zip”
-T = checks for timeout after 15 seconds (default 900 secs)
-c = continue wget download in case it was partially downloaded already
***END
I ended up just downloading from the site instead of through jupyter notebook.
But here is what I was trying.
Get link from kaggle. Note: the coped link is much longer than the picture.
I’m not 100% sure what the errors could be, I’d try the recommendations from others in the thread too. It could be dataset dependent and/or environment dependent too (from Kaggle’s side on a firewall standpoint,etc). Sorry about the issues
I figured out a solution for my problem (updated in my post). I just added a “-T 15” flag into my !wget command. During my kaggle download, I’d get a byte error that stopped the download.
From what I understand, the MaxBlurPool is designed to help convnets (re-)learn translational invariance. Translational (or shift) invariance can be sort of learned via image augmentation, but aliasing problems can cause issues. R. Zhang showed in his ICLR paper that a BlurPool (=downsampling) layer after MaxPool operation can help anti-alias the network and recover translational invariance. See also the official Github repo for neat examples.
As is demonstrated in the imagenette leaderboards (see post by @muellerzr) MaxBlurPool can be used as a drop-in replacement for all instances of MaxPool in the xresnet architecture.
EDIT: Based off my very limited number of tests, MaxBlurPool hasn’t helped me top the FastGarden leaderboard… Wait, actually I’m starting to get good results using MaxBlurPool and a lower learning rate. Unfortunately Paperspace gave me a Quadro M4000 for this session, which means that it takes 7 minutes to train an epoch…
Optimizer: Adam, ranger (ranger seems faster for 5 epochs)
Fit function: fit_one_cycle, fit_flat_cos (both similar with ranger, adam is less accurate)
Self-attention seemed to help maybe ~4-5% (only tried on the xreset)
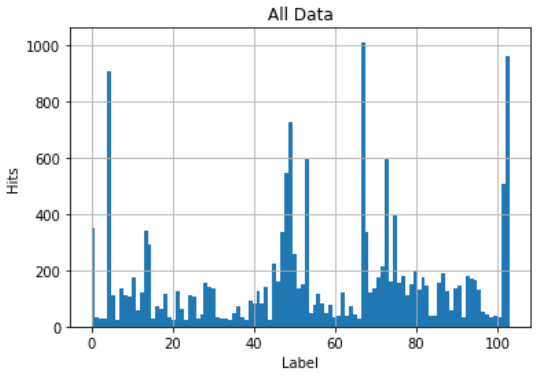
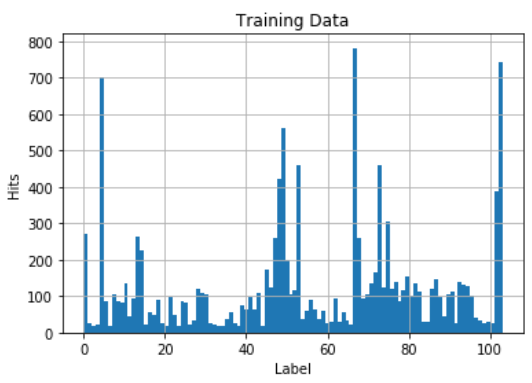
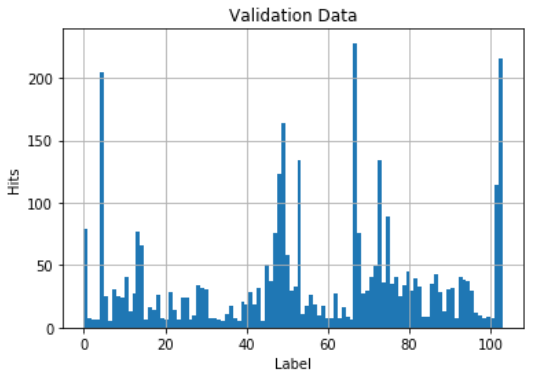
Stratified training/validation data: downsampled to stratify, and then augmented to get back to ~12000 (similar results as using the original training set with the splitter). Just as a data point, from all the data (~16000 pts), labels 6,34,44 have only 23 examples (lowest). Label 67 has the most at 1010 examples
Here’s what the data looks like if you use the “splitter = IndexSplitter(range(12753, len(data)))” from the Zachary’s baseline notebook.