I find it extremely helpful - especially when learning something new - when I can quickly see what happens when I try this or that.
I am now going over the lesson 1 notebook again but to speed things up I am running everything on a small subset of the data (200 cat images and 200 dog images - still probably way more than I need).
Not sure really if anyone would be interested in this but if that would be the case here are the instructions (BTW this uses a slightly modified version of an awesome command shared by @jeremy on Twitter a couple of weeks ago):
From the directory of your notebook (from where you have the data folder available) run the following:
In your notebook, change the PATH to PATH = "data/dogscats_sample/"
The awesome command @jeremy shared on Twitter was this (please note the mv that you want to normally use when creating the train / valid / test splits):
shuf -n 5000 -e all/*.* | xargs -i mv {} all_val/
BTW not sure if anyone would find this useful, but I really like toy examples for getting a grasp on things. I was thinking of maybe training the original LeNet on CIFAR10 or MNIST using fastai. Would anyone be interested in a notebook walking through the techniques we learn applied to such toy examples?
I was banging my head against the wall last night, having spent 4+ hours running two notebooks on two different instances (Crestle - planets; AWS-dog breeds). I never got as far as a submission in either because of small problems that then resulted in restarts, after 45 min+ training runs, then more restarts . . . And suddenly it’s after midnight and I am no further than when I started
So this will be my new strategy tonight, getting things to work on a sample set before committing to the entire dataset!
And yes, I think a notebook walk-through would be helpful, particularly for the Part1-V1-beginner forum.
Thanks for all your great posts – I appreciate your contributions to the community!
Maureen
Thank you very much for your kind words @memetzgz and glad this might be of help
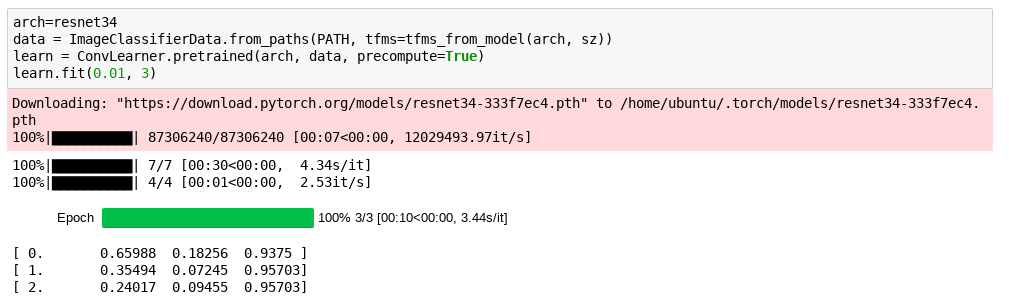
BTW in case anyone feels that ‘oh this is deep learning with this little data I will not do anything interesting’ these are the results from training the first model
Also, on a related note, I know of this one silly dude on the Internet who applied the techniques from first lesson of part 1 v1 and trained just on 3 images of cats and 3 images of dogs And it worked!
Any ideas on how to create a sample dataset when we are using the from_csv method rather than storing the images in separate directories?
Looking at the dataset.py file, I don’t see a way to select a subset of images rather than the whole lot of them in the from_csv method. Also, I would imagine one would want a random selection of images, so we’d need to shuffle, but the get_ds function doesn’t have a shuffle parameter like get_dl does.
If I were a better coder, I’d code up a function to do this, but I’m still a rookie – I’m still getting lost just looking at the code
I think your observations with regards to from_csv are spot on. I do not know how images are stored in csv files, but I would imagine each image is stored as a new line - this could be verified by doing a line count in the csv file, I think something like cat file.csv | wc -l should do the trick but not sure
If that would be the case that indeed 1 file == 1 line in the csv file, then there must be some way to select a subset of lines from terminal or one could write a dumb script in Python going through the file and randomly selecting a line for example if np.random.rand() > 0.8 (or whatever method exists for generating floats from uniform distribution [0, 1) - this would be equivalent to randomly grabbing 20% of lines)
We could then save whatever lines we decide to keep back to csv and read it using the fastai api without any problems
EDIT: Instructions on how to do something like this from terminal
So would it be as simple as reading the csv file into a DataFrame, using the pandas sample method to select a random sample for train, validation, and test, saving those back to CSVs, and then feeding those filenames as parameters in the .from_csv call within the get_batches function? Am I on the right track at least?
It might be a useful feature to add for from_csv to be able to take in a pandas DF that was created in the notebook rather than currently only accepting a path to a CSV file. That way you could more easily manipulate the training set using pandas functions without needing to save to CSV each time.
I am not very good with bash scripting and I suspect that iterating over a list of strings might be troublesome though definitely doable. Maybe combining the best of both worlds (jupyter notebook and linux programs) would be worth exploring? I am thinking about something along the lines:
categories = ['category_1', 'category_2']
!!mkdir -p path/to/data/dataset_name/{category_1, category_2} # would be nice to automate this
# as well but I don't know how, need some string interpolation at some point somewhere
# maybe something like this:
!mkdir {f'-p path/{categories.join(',')}'} # or however going from list to string is done in Python
for category in categories:
!shuf ... # and string interpolation again I guess
Either way - I don’t have an answer and sorry for me babbling but maybe some of this can be of help!