I have spent some time working on building a model for the full MNIST problem, my full code is here.
While trying not to use fastai/pytorch built-in stuff, I built my own loss function, in which I tried to generalize what was done during the lesson:
def myloss(predictions, targets):
if targets.ndim == 1:
targets = targets.unsqueeze(1)
targets_encoded = torch.zeros(len(targets), 10)
targets_encoded.scatter_(1, targets, 1)
return torch.where( targets_encoded==1, 1-predictions, predictions ).mean()
Here I one-hot encode the targets, e.g. 3 becomes tensor([0,0,0,1,0,0,0,0,0,0]) and then apply the same logic as in the lesson. Further down in the code I also test it on a few examples and it indeed behaves as expected.
Nevertheless I see that when training the model, the accuracy increases at first but then drops. Here is a plot showing this behaviour, compared to an identical model using built-in cross entropy as loss:
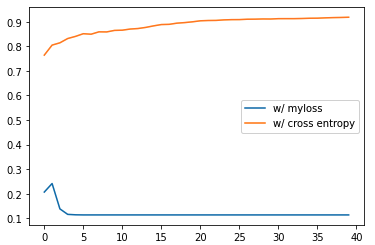
Digging a bit deeper into what happens, it turns out that myloss is actually pushing all the predictions to be 0, instead of having the prediction corresponding to the target to tend towards one. See the following:
Predictions on a few 0-images from the model trained with myloss:
tensor([[3.9737e-06, 2.3754e-05, 3.7458e-06, 2.1279e-06, 3.1777e-06, 4.1798e-06, 3.5480e-06, 4.4862e-06, 2.9011e-06, 3.1170e-06],
[3.2510e-05, 1.5322e-04, 2.9165e-05, 2.1045e-05, 2.8467e-05, 3.2954e-05, 3.0909e-05, 3.4809e-05, 2.4691e-05, 2.8036e-05],
[1.4162e-10, 4.1921e-09, 8.6994e-11, 4.9182e-11, 9.4531e-11, 1.4529e-10, 1.0986e-10, 2.0410e-10, 9.2959e-11, 7.7468e-11],
[4.8831e-05, 1.5990e-04, 5.0114e-05, 2.7525e-05, 3.4216e-05, 3.3996e-05, 5.0872e-05, 4.6151e-05, 2.8764e-05, 2.9847e-05],
[1.3763e-05, 6.3028e-05, 1.2435e-05, 8.1820e-06, 1.0536e-05, 1.3688e-05, 1.3276e-05, 1.5969e-05, 8.7765e-06, 1.0267e-05]], grad_fn=<SigmoidBackward>)
predictions on the same 0-images from the model trained with the built-in cross entropy:
tensor([[9.9997e-01, 1.9660e-10, 2.8802e-05, 7.1700e-05, 3.9799e-11, 2.1466e-04, 1.3326e-05, 1.7063e-04, 6.1224e-06, 5.6696e-06],
[9.9806e-01, 7.7187e-10, 3.2351e-04, 1.9475e-05, 2.1741e-06, 1.4926e-01, 2.7456e-04, 2.0312e-05, 7.7267e-03, 9.0754e-05],
[7.1219e-01, 4.2656e-10, 2.6540e-09, 6.5700e-04, 9.7222e-09, 4.9841e-04, 3.9048e-07, 5.9277e-09, 6.7378e-04, 6.5973e-07],
[9.9956e-01, 7.8313e-11, 1.4271e-01, 1.7383e-03, 2.3370e-09, 2.2956e-05, 2.3185e-03, 1.6754e-06, 4.0645e-05, 7.0746e-09],
[9.9985e-01, 4.5725e-10, 6.3417e-03, 1.8504e-04, 3.7823e-11, 1.4808e-04, 5.6004e-05, 4.3960e-06, 6.0555e-03, 2.3748e-04]], grad_fn=<SigmoidBackward>)
As you can see, in the first bunch of predictions all the numbers are basically 0, while in the second the first column (corresponding to the 0-images in one-hot encoding) are basically 1.
Now it is clear that myloss is not behaving as expected, but I can’t really understand why. Can someone give some help? I have spent so much time looking at it and testing it that I kinda run out of ideas …
