Can we use BBoxBlock independently without BBoxLblBlock?
I tried doing so but it throws some error with bb_pad. I tried removing that method from pipeline but then it started complaining about invalid shapes despite of all being same.
Collating items in a batch
Error! It's not possible to collate your items in a batch
Could not collate the 0-th members of your tuples because got the following shapes
torch.Size([3, 224, 224]),torch.Size([3, 224, 224]),torch.Size([3, 224, 224]),torch.Size([3, 224, 224])
I can post whole stacktrace if you need.
EDIT: Passing in list of dummy labels of required length passes the pipeline, is that how it should be done?
I did try to adapt bb_pad by passing in empty string as a label. I’ve also modified the L1Loss to work with multiple outputs. Now I’m getting bool value of Tensor with more than one value is ambiguous error. I’ve posted more about it under similar topic here
Just a general question, would you guys (devs) or others in general be interested in a PR that includes a utility function for transferring weights from similar architectures? IE transfering a model’s weights trained on ImageWoof to a model being used on the PETs dataset?
Ah that actually makes sense, probably load_encoder? (I’ll look in a little bit) If so, would it be okay moving it to a level higher? (Learner) or would you rather keep it’s functionality there
Hey guys, just wanted to point out this very cool behavior with get_preds and multiple models!
Let me build a scenario for you, I have two separate models that receive the same image, and I want to do inference with both models. One model does say regression and the other model does classification. Now our presumption would first be I need to make two new dataloaders for each and then I need to run any decoding separately, but that’s unnecessary! Even though I have a dataloader built from the classification model, if I do decode_preds on the regression model, it will work!
Very surprised by this (but a welcome one!) I presume it has to do with decodes looks at the type of output and then does the decode_batch, which is a very cool behavior
I had similar requirement in one of my project, I was wanted to export the weights of encoder of Unet and use that for classification problem. One additional requirement was that I had few additional bottleneck layers after the encoder, which should also be exported in the same .pth file. I feel the way I did it is somewhat hairy and would be great if you could suggest a better of doing the same
I’m using SaveModelCallback to save best model while training. After done with the training, I tried deleting and re-instantiating the learner with random weights and then ran learn.validate() (results went down as expected)
Then I performed learn.load(exp_name) and ran learn.validate(), still the results are as worse as the random weights.
EDIT: Saving it explicitly using learn.save and then loading it back reproduces the results
I have a short question: does the Resize parameter in item-tfms apply to just the images, or does it also resize the bounding boxes? Thanks for your advice
The vision transforms use type dispatching to handle the various types (bounding boxes, keypoints, segmentation, etc) so yes however you should use a padding method IIRC to not lose any data
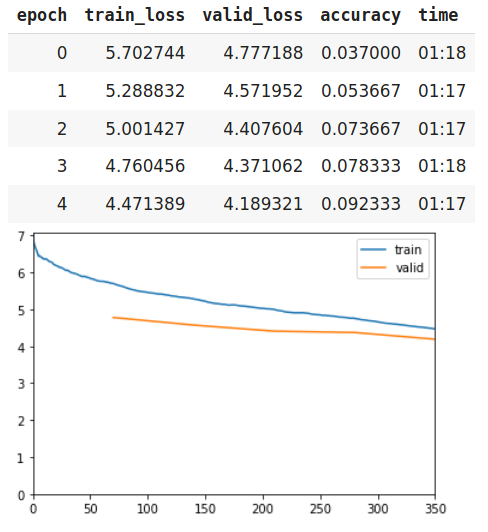
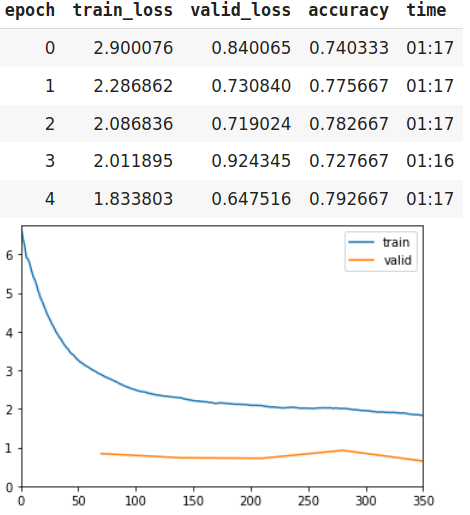
So atleast xresnet50 should work with pretrained weights or that might fail as well? I my previous experiments, I tried training xresnet34 from scratch, it went from 3% to 26% and loss went ‘nan’ after 20 epochs. (I was using ranger optimizer with lr=1e-4)
In general, is it safe to start with xresnet models while working on new dataset/augmentation/loss function?
What are the recommended optimizers and lr_schedulers while training for large no. of epochs (50+)
Looking at the log it seems it tried to download xresnet50 instead…
You can clearly add in your learner pretrained=False and it may work (though training will be much longer and it won’t benefit from pretrained networks).