And you’re using the camvid dataset?
Yes, for the moment I’m only trying to implement this 2 inputs DynamicUnet. And I’m testing it on CamVid.
Only after I’ll plug my real datasets.
It seems to be related to some sort of serialization:
(this comes from the previous error trace)
~/workspace/fastai2/fastai2/callback/schedule.py in after_fit(self)
168 tmp_f = self.path/self.model_dir/'_tmp.pth'
169 if tmp_f.exists():
--> 170 self.learn.load('_tmp')
171 os.remove(tmp_f)
172The problem is caused when the predictions, in a mutli-label problem, contain no categories that are predicted to be true. So in the attached image you can see that all of the predictions for the first image in the batch are set to False.
In the current implementation of the show_results function there is no check to see if at least one prediction exists, and so it causes a crash.
In my modified function it checks if “r.show” exists before using it and this therefore stops the crash & prints the target label in black.
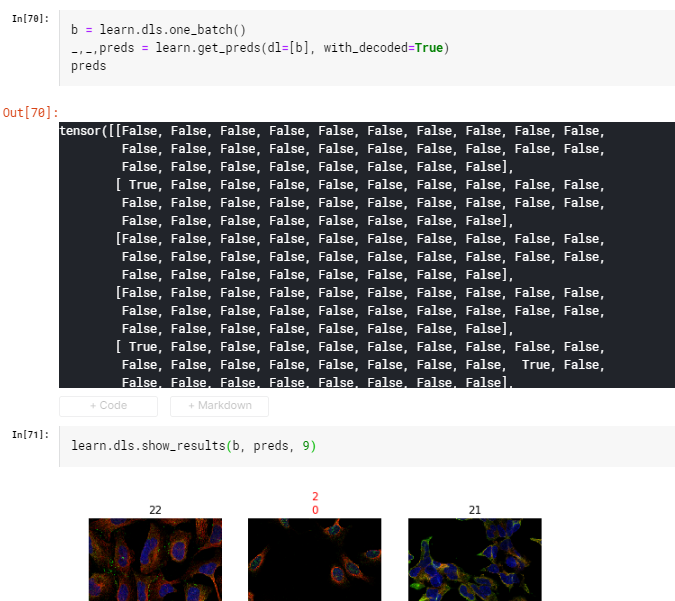
Just wanting to point out a bug, I’m unsure how exactly we could fix it without type dispatch, but considering it’s in the batch level we lost this ability. I’m attempting to do Mask RCNN and so I’m building a DataBunch that contains bounding boxes and segmentation masks. Everything works fine up until bb_pad, and this is due to it expecting in the batch, samples 1 and on to contain the bbox and labels and that is it.
My fix was:
if len(samples[0]) > 3:
samples = [(s[0], *clip_remove_empty(*s[1:3])) for s in samples]
else:
samples = [(s[0], *clip_remove_empty(*s[1:])) for s in samples]
However this isn’t perfect as we’re forced to make the user assume to pass in the bounding boxes first and then any other datatypes we want. Any ideas? (@sgugger)
bb_pad_collate doesn’t type-dispatch and is only working with object detection, you should write your own version for other problems.
1 Like
Got it, thanks  for anyone wanting to do something similar,
for anyone wanting to do something similar, s reads in your samples, so this (in my case) was set as the following:
input image, bbox coord, bbox lbl, segmentation mask.
So I cared about 1:3 for the bounding box paddings
I then just did myBBoxBlock = TransformBlock(type_tfms=TensorBBox.create, item_tfms=PointScaler, dls_kwargs = {'before_batch': mybb_pad})
2 Likes
I was trying to build my SemanticTensor pipeline but it throws error if use my class instead of normal tensor:
class TensorContinuous(TensorBase): pass
class NormalizeTfm(Transform):
def encodes(self, o): return (o - self.mean) / self.std
def decodes(self, o): return (o * self.std) + self.mean
def setups(self, dsets):
td = tensor(dsets).float()
self.mean, self.std = td.mean(), td.std()+1e-7
class RegSetup(Transform):
"Transform that floatifies targets"
def encodes(self, o): return tensor(o).float()
# def encodes(self, o): return TensorContinuous(o).float()
def decodes(self, o):return TitledStr(o.item())
def RegressionFBlock():
return TransformBlock(type_tfms=[RegSetup(), NormalizeTfm()])
dblock = DataBlock(blocks=(ImageBlock, RegressionFBlock, RegressionFBlock, CategoryBlock),
getters=getters,
splitter=ColSplitter('is_val'),
item_tfms=Resize(size),
batch_tfms = [*aug_transforms(max_zoom=0, flip_vert=True)])
RegSetup was originally RegressionSetup. I just cleared out some unnecessary code for me.
Above code works and I do get normalized column tensor. However, if I change the encodes method of RegSetupto commented one, it throws following error:
RuntimeError: detach is not implemented for Tensor
Also, let me know if I could move the NormalizeTfm to batch_tfms somehow.
Thanks!
Trying to work my way with the SiamesePair example right now, and I’m confused with one question. So where do we apply this? I’m having issues connecting the dots together from our Pipeline into the DataSource/DataLoaders. Where would we load in the SiamesePair transform? (I’ve tried the obvious bits IE after_ and inside the tfms of our Datasets transforms. The last bit I may do is make a custom transform a little differently)
cc @sgugger?
No, the transform is applied in a TfmdLists that you then convert to a DataLoaders with the .dataloaders method.
Thanks, I think I understand now So I could do the following then?
tl = TfmdLists(items[:10], pipe)
dl = tl.dataloaders(bs=1)
If so I get a PosixPath object is not iterable error. (this is just passing in a list of items.) If I try passing in instead a list of x’s and y’s from a dset I get “TypeError: int() argument must be a string, a bytes-like object or a number, not ‘PILImage’”
(said code from tutorial and how I set it up):
class SiamesePair(Transform):
def __init__(self,items,labels):
self.items,self.labels,self.assoc = items,labels,self
sortlbl = sorted(enumerate(labels), key=itemgetter(1))
# dict of (each unique label) -- (list of indices with that label)
self.clsmap = {k:L(v).itemgot(0) for k,v in itertools.groupby(sortlbl, key=itemgetter(1))}
self.idxs = range_of(self.items)
def encodes(self,i):
"x: tuple of `i`th image and a random image from same or different class; y: True if same class"
othercls = self.clsmap[self.labels[i]] if random.random()>0.5 else self.idxs
otherit = random.choice(othercls)
return SiameseImage(self.items[i], self.items[otherit], self.labels[otherit]==self.labels[i])
class SiameseImage(Tuple):
def show(self, ctx=None, **kwargs):
img1,img2,same_breed = self
return show_image(torch.cat([img1,img2], dim=2), title=same_breed, ctx=ctx)
OpenAndResize = Transform(resized_image)
labeller = RegexLabeller(pat = r'/([^/]+)_\d+.jpg$')
sp = SiamesePair(items, items.map(labeller))
pipe = Pipeline([sp, OpenAndResize])
dset = pets.datasets(src)
tl = TfmdLists(dset[:10], pipe)
dl = tl.dataloaders(bs=1)
This is because i at this point is an image itself and a label
Sorry just the answer isn’t obvious to me on how to go from A->B here 
1 Like
Your transform to resize should be on as an after_item in your dataloaders, it will automatically be applied to every part of the tuple that needs it.
I’m still having the PosixPath issue. Which specifically happens here:
othercls = self.clsmap[self.labels[i]] if random.random()>0.5 else self.idxs
The issue itself is in the SiamesePair transform, I guess I’m confused with how it expects the data to be loaded in outside of a Pipeline. I think we still need to make an instance of it yes? (Or no because it should be flexible depending on the input.) If not, how do we pass in it’s items and labels we want.
(I guess it may have been meant to be as a show example and should be refactored if actually applying to a DataLoader?)
Please do not at-mention me when there are other people who can also look and help you.
In this case no one (including me) can because you only posted one line of the error message without the full stack trace. Also include the things you tried to debug this so that anyone reading can understand the issue a little bit better. This is the way to efficiently get help on the forum, not at-mentioning the administrators.
2 Likes
Really sorry for that. Will post all the debugging steps I performed and complete stack trace here.
So I made some progress with this issue. I’m trying to process multiple columns from Dataframe
class TensorContinuous(TensorBase): pass
class RegSetup(Transform):
"Transform that floatifies targets"
def encodes(self, o): return TensorContinuous(o).float()
def decodes(self, o:TensorContinuous):return TitledStr(o.item())
pipe = Pipeline([RegSetup])
temp = df[['age', 'parity']]
p = pipe(temp); p
output:
TensorContinuous([[43., 1.],
[43., 1.],
[43., 1.],
...,
[49., 9.],
[49., 9.],
[49., 9.]])
Now, the next thing I want to do is normalize these columns with their respective stats
class Norm(Transform):
"Normalize/denorm batch of `TensorImage`"
order=99
def __init__(self, mean=None, std=None, axes=(0,2,3)): self.mean,self.std,self.axes = mean,std,axes
@classmethod
def from_stats(cls, mean, std, dim=1, ndim=4, cuda=True): return cls(*broadcast_vec(dim, ndim, mean, std, cuda=cuda))
def setups(self, dl:DataLoader):
if self.mean is None or self.std is None:
x = dl.one_batch()
self.mean,self.std = x.mean(self.axes, keepdim=True),x.std(self.axes, keepdim=True)+1e-7
print(self.mean, self.std)
def encodes(self, x:TensorContinuous): return (x-self.mean) / self.std
def decodes(self, x):
f = to_cpu if x.device.type=='cpu' else noop
return (x*f(self.std) + f(self.mean))
tl = TfmdLists(temp, pipe)
dl = tl.dataloaders(bs=8, after_batch=[Norm(axes=0)])
Output
TensorContinuous([[41.7500, 2.2500]], device='cuda:0') TensorContinuous([[12.7811, 1.2817]], device='cuda:0')
dl.one_batch()
Output
ensorContinuous([[-0.1369, -0.1950],
[-0.8411, 0.5851],
[-1.5452, -0.9752],
[-0.2152, -0.1950],
[ 0.8020, -0.9752],
[-0.6064, -0.1950],
[-0.6064, 1.3653],
[ 1.0367, 1.3653]], device='cuda:0')
Now, this worked fine because I was dealing with ony these dataframe columns. But in my actual pipeline, I’ve ImageBlock and these RegressionBlocks
For that, I’m using getters and due to my SemanticTensors, that too works fine for me (for only single block of data  )
)
def get_x(x): return f'{path}/{x.image_path}'
def get_age(x): return x.age
def get_parity(x): return x.parity
def get_y(x): return x.category
getters = [get_x, get_age, get_y]
Currently, I’m only working with age (I’ll explain the reason) and the pipeline seems to work fine
def RegressionFBlock():
return TransformBlock(type_tfms=[RegSetup()], batch_tfms=[NormalizeTfm(axes=0)])
dblock = DataBlock(blocks=(ImageBlock, RegressionFBlock, CategoryBlock),
getters=getters,
splitter=ColSplitter('is_val'),
item_tfms=Resize(size),
batch_tfms = [*aug_transforms(max_zoom=0, flip_vert=True)])
The normalize transform I’m using needs to take care of the element I’m working on (Which is huge disadvantage for me)
class NormalizeTfm(Transform):
"Normalize/denorm batch of `TensorImage`"
order=99
def __init__(self, mean=None, std=None, axes=(0,2,3)): self.mean,self.std,self.axes = mean,std,axes
@classmethod
def from_stats(cls, mean, std, dim=1, ndim=4, cuda=True): return cls(*broadcast_vec(dim, ndim, mean, std, cuda=cuda))
def setups(self, dl:DataLoader):
if self.mean is None or self.std is None:
_,x,_ = dl.one_batch()
self.mean,self.std = x.mean(self.axes, keepdim=True),x.std(self.axes, keepdim=True)+1e-7
def encodes(self, x:TensorContinuous): return (x-self.mean) / self.std
def decodes(self, x:TensorContinuous):
f = to_cpu if x.device.type=='cpu' else noop
return (x*f(self.std) + f(self.mean))
check the setups method of NormalizeTfm. Neverthless, it’s working and the end result of dblock.summary(df) is as follows:
Applying batch_tfms to the batch built
Pipeline: IntToFloatTensor -> AffineCoordTfm -> LightingTfm -> NormalizeTfm
starting from
(TensorImage of size 4x3x224x224, TensorContinuous([43., 43., 43., 43.], device='cuda:0'), TensorCategory([2, 2, 2, 2], device='cuda:0'))
applying IntToFloatTensor gives
(TensorImage of size 4x3x224x224, TensorContinuous([43., 43., 43., 43.], device='cuda:0'), TensorCategory([2, 2, 2, 2], device='cuda:0'))
applying AffineCoordTfm gives
(TensorImage of size 4x3x224x224, TensorContinuous([43., 43., 43., 43.], device='cuda:0'), TensorCategory([2, 2, 2, 2], device='cuda:0'))
applying LightingTfm gives
(TensorImage of size 4x3x224x224, TensorContinuous([43., 43., 43., 43.], device='cuda:0'), TensorCategory([2, 2, 2, 2], device='cuda:0'))
applying NormalizeTfm gives
(TensorImage of size 4x3x224x224, TensorContinuous([0.0307, 0.0307, 0.0307, 0.0307], device='cuda:0'), TensorCategory([2, 2, 2, 2], device='cuda:0'))
Now the real problem is, how can I deal with multiple columns in the same pipeline as I was able to do using Pipeline and TfmdLists above.
I tried modifying getters to accept tuple/array as:
getters = [get_x, lambda x: (x.age, x.parity), get_y]
But this results in two objects of TensorContinuous and sets up dedicated pipeline for each (Which is not expected in my scenario)
TL;DR
- How can I improvise
NormalizeTfmto work with my data? - How to pass multiple items from
gettersto singleTransformBlock? - Even if I need to create separate block for each column, how can I normalize that with the respective stats? Otherwise, the only option I’ve is to write yet another
NormalizeTfmwith modifedsetupsmethod for respective column.
@kshitijpatil09 just a thought, why not keep a dictionary of their values and what they mean? (IE age : 0) this way you can easily look up their stats via said dictionary, which we store in the class somewhere (or an array, some look up system based on position)
1 Like
One side note first: I see you have copied the Normalize transform and just added a new encodes/decodes for a new type. You can do this without writing a new class by using a decorator:
@Normalize
def encodes(self, x:TensorContinuous): return (x-self.mean) / self.std
@Normalize
def decodes(self, x:TensorContinuous):
f = to_cpu if x.device.type=='cpu' else noop
return (x*f(self.std) + f(self.mean))
Now back to your question. To pass multiple items to a single TransformBlock you need to use a list/L/dictionary but not a tuple. Tuples are special for transforms, and they will try to apply on each part of the tuple instead of taking the tuple as a whole. If you really need tuples, use ItemTransforms in the pipeline that receives them.
With that, you can them write a custom Transform that normalizes each input with the different stats, and define a block that has it as default if you want to use the data block API.
6 Likes