No, it has not been ported yet.
@sgugger Running some models (ULMFIT language models) that were working in previous fastai2 versions, now fail at the end of the last epoch, with the message:
RuntimeError: param_from.type() == param_to.type() INTERNAL ASSERT FAILED at /opt/conda/conda-bld/pytorch_1579022060824/work/aten/src/ATen/native/cudnn/RNN.cpp:541, please report a bug to PyTorch. parameter types mismatch
I have this one too when going torch 1.4.0. It works well when I’m using torch 1.3.0.
Unfortunately when using 1.3.0 I have issues with the vision imports.
I am on PyTorch 1.4.0, training in mixed precision a language model, and I can’t see that error.
Using the code below to transform a LTR dataloaders to RTL (backwards) …
lm_dls = torch.load(LM_PATH/f'data_lm{data_suf}.pkl')
if (backwards): lm_dls.tfms.add(Transform(lambda nums: nums.flip(0)))
How can I change the pad_input_chunk so that pad_first = False for the backwards run?
I am not sure SentencePiece is not the problem here.
When I create an instance of SP, and inspect the object, this is what I get:
Code:
sp=SentencePieceTokenizer(sp_model=spm15kpt.model')`
print(sp.tok)
Result:
<sentencepiece.SentencePieceProcessor; proxy of <Swig Object of type 'sentencepiece::SentencePieceProcessor *' at 0x7fdc6d5e1c30> >
Also, others seem to have problems pickling SP, but it seems there are some workarounds:
The link in the post is broken. The workaround example is shown here with __getstate__ and __setstate__
If you use a dataloaders object like this:
lm_dls = torch.load(LM_PATH/f'data_lm{data_suf}.pkl')
if (backwards): lm_dls.tfms.add(Transform(lambda nums: nums.flip(0)))
That lambda will cause an issue when you export the learner:
learn.export(fname=f'{m_pre}export_lm{data_suf}.pkl')
# throws this exception: Can't pickle <function <lambda> at 0x7fe495fb2cb0>: attribute lookup <lambda> on __main__ failed
Hi @sgugger
I see there are changes in fastai2/fastai2/text/ core.py (get_lengths) and I only wanted to say that this fixed the problems I was having when using a folder for texts and a csv file for labels 
2 Likes
Attempting to configure a multi-label problem using the low-level API, but getting an KeyError: '' error when attempting to create a Dataloaders object from my Datasets object …
%%time
x_tfms = [
attrgetter('text'),
Tokenizer.from_df(text_cols=corpus_cols, rules=custom_tok_rules, mark_fields=include_fld_tok),
Numericalize(vocab=vocab)
]
y_tfms = [
attrgetter("labels"),
lambda val: val.split(' '),
MultiCategorize(vocab=SENT_LABELS[1:])
]
dsets = Datasets(items=df,
tfms=[x_tfms, y_tfms],
splits=ColSplitter(col='is_valid')(df),
dl_type=SortedDL)
len(dsets.train), len(dsets.valid)
# (12219, 1356)
len(vocab), len(dsets.vocab), len(dsets.vocab[0]), len(dsets.vocab[1])
# (32408, 2, 32408, 8)
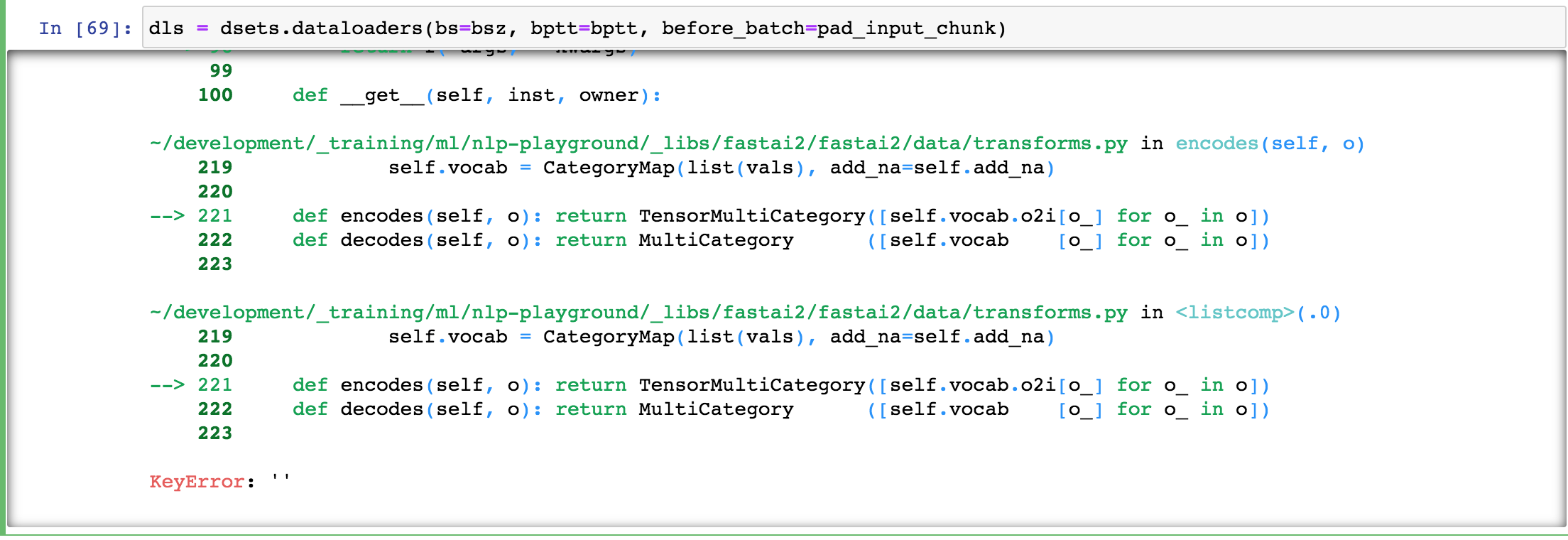
dls = dsets.dataloaders(bs=bsz, bptt=bptt, before_batch=pad_input_chunk)
Last line throws a KeyError: '' exception:
You don’t have the benefit of being a new user, you know you should post the whole stack trace and not a screen shot of the end :-p
2 Likes
Ok … you asked for it:
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-69-33017cdf2a1f> in <module>
----> 1 dls = dsets.dataloaders(bs=bsz, bptt=bptt, before_batch=pad_input_chunk)
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/core.py in dataloaders(self, bs, val_bs, shuffle_train, n, path, dl_type, dl_kwargs, device, **kwargs)
179 if dl_type is None: dl_type = self._dl_type
180 dl = dl_type(self.subset(0), bs=bs, shuffle=shuffle_train, drop_last=shuffle_train, n=n, device=device,
--> 181 **merge(kwargs, dl_kwargs[0]))
182 dls = [dl] + [dl.new(self.subset(i), bs=(bs if val_bs is None else val_bs), shuffle=False, drop_last=False,
183 n=None, **dl_kwargs[i]) for i in range(1, self.n_subsets)]
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/text/data.py in __init__(self, dataset, sort_func, res, **kwargs)
150 self.sort_func = _default_sort if sort_func is None else sort_func
151 if res is None and self.sort_func == _default_sort: res = _get_lengths(dataset)
--> 152 self.res = [self.sort_func(self.do_item(i)) for i in range_of(self.dataset)] if res is None else res
153 if len(self.res) > 0: self.idx_max = np.argmax(self.res)
154
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/text/data.py in <listcomp>(.0)
150 self.sort_func = _default_sort if sort_func is None else sort_func
151 if res is None and self.sort_func == _default_sort: res = _get_lengths(dataset)
--> 152 self.res = [self.sort_func(self.do_item(i)) for i in range_of(self.dataset)] if res is None else res
153 if len(self.res) > 0: self.idx_max = np.argmax(self.res)
154
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/load.py in do_item(self, s)
117 def prebatched(self): return self.bs is None
118 def do_item(self, s):
--> 119 try: return self.after_item(self.create_item(s))
120 except SkipItemException: return None
121 def chunkify(self, b): return b if self.prebatched else chunked(b, self.bs, self.drop_last)
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/load.py in create_item(self, s)
123 def randomize(self): self.rng = random.Random(self.rng.randint(0,2**32-1))
124 def retain(self, res, b): return retain_types(res, b[0] if is_listy(b) else b)
--> 125 def create_item(self, s): return next(self.it) if s is None else self.dataset[s]
126 def create_batch(self, b): return (fa_collate,fa_convert)[self.prebatched](b)
127 def do_batch(self, b): return self.retain(self.create_batch(self.before_batch(b)), b)
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/core.py in __getitem__(self, it)
263
264 def __getitem__(self, it):
--> 265 res = tuple([tl[it] for tl in self.tls])
266 return res if is_indexer(it) else list(zip(*res))
267
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/core.py in <listcomp>(.0)
263
264 def __getitem__(self, it):
--> 265 res = tuple([tl[it] for tl in self.tls])
266 return res if is_indexer(it) else list(zip(*res))
267
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/core.py in __getitem__(self, idx)
240 res = super().__getitem__(idx)
241 if self._after_item is None: return res
--> 242 return self._after_item(res) if is_indexer(idx) else res.map(self._after_item)
243
244 # Cell
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/core.py in _after_item(self, o)
204 def _new(self, items, **kwargs): return super()._new(items, tfms=self.tfms, do_setup=False, types=self.types, **kwargs)
205 def subset(self, i): return self._new(self._get(self.splits[i]), split_idx=i)
--> 206 def _after_item(self, o): return self.tfms(o)
207 def __repr__(self): return f"{self.__class__.__name__}: {self.items}\ntfms - {self.tfms.fs}"
208 def __iter__(self): return (self[i] for i in range(len(self)))
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/transform.py in __call__(self, o)
183 self.fs.append(t)
184
--> 185 def __call__(self, o): return compose_tfms(o, tfms=self.fs, split_idx=self.split_idx)
186 def __repr__(self): return f"Pipeline: {' -> '.join([f.name for f in self.fs if f.name != 'noop'])}"
187 def __getitem__(self,i): return self.fs[i]
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/transform.py in compose_tfms(x, tfms, is_enc, reverse, **kwargs)
136 for f in tfms:
137 if not is_enc: f = f.decode
--> 138 x = f(x, **kwargs)
139 return x
140
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/transform.py in __call__(self, x, **kwargs)
70 @property
71 def name(self): return getattr(self, '_name', _get_name(self))
---> 72 def __call__(self, x, **kwargs): return self._call('encodes', x, **kwargs)
73 def decode (self, x, **kwargs): return self._call('decodes', x, **kwargs)
74 def __repr__(self): return f'{self.name}: {self.encodes} {self.decodes}'
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/transform.py in _call(self, fn, x, split_idx, **kwargs)
81 if split_idx!=self.split_idx and self.split_idx is not None: return x
82 f = getattr(self, fn)
---> 83 if not _is_tuple(x): return self._do_call(f, x, **kwargs)
84 res = tuple(self._do_call(f, x_, **kwargs) for x_ in x)
85 return retain_type(res, x)
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/transform.py in _do_call(self, f, x, **kwargs)
86
87 def _do_call(self, f, x, **kwargs):
---> 88 return x if f is None else retain_type(f(x, **kwargs), x, f.returns_none(x))
89
90 add_docs(Transform, decode="Delegate to `decodes` to undo transform", setup="Delegate to `setups` to set up transform")
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/dispatch.py in __call__(self, *args, **kwargs)
96 if not f: return args[0]
97 if self.inst is not None: f = MethodType(f, self.inst)
---> 98 return f(*args, **kwargs)
99
100 def __get__(self, inst, owner):
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/transforms.py in encodes(self, o)
219 self.vocab = CategoryMap(list(vals), add_na=self.add_na)
220
--> 221 def encodes(self, o): return TensorMultiCategory([self.vocab.o2i[o_] for o_ in o])
222 def decodes(self, o): return MultiCategory ([self.vocab [o_] for o_ in o])
223
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/transforms.py in <listcomp>(.0)
219 self.vocab = CategoryMap(list(vals), add_na=self.add_na)
220
--> 221 def encodes(self, o): return TensorMultiCategory([self.vocab.o2i[o_] for o_ in o])
222 def decodes(self, o): return MultiCategory ([self.vocab [o_] for o_ in o])
223
KeyError: ''
I did indeed 
It takes the same space as your screenshot and in some cases can help far more quickly. In this case, you should try to access some elements of your dsets since the problem lies there. Maybe some of your labels are separated by two spaces so you get some of those ''?
Just checked and there are examples where there are no labels … and so labels = ‘’ (just an empty string). There are no additional spaces anywhere in the list of labels where at least one label exists for the example.
Shouldn’t the MultiCategorize transform treat all labels as 0 in this case?
If there are no labels, MultiCategorize should receive [], and splitting an empty string on space does return [].
So how should my y_tfms be changed?
y_tfms = [
attrgetter("labels"),
lambda val: val.split(' '),
MultiCategorize(vocab=SENT_LABELS[1:])
]
There are 8 labels I’m attempting to classify (SENT_LABELS[1:]) … but not all examples have any label.
The labels will look something like this:
is_positive has_profanity has_suggestion
is_fraud has_suggestion
is_negative
… where each of those space separated labels are included in SENT_LABELS[1:]. However, there are rows were no label is included and therefore the value is simply empty. In that case, this line in MultiCategorize:
def encodes(self, o): return TensorMultiCategory([self.vocab.o2i[o_] for o_ in o])
will throw that exception for o_ in o will return the following in such cases:
[['']]
and that is not in the vocab.
Call me crazy but couldn’t you add a simple function like so? (I did something similar for single category -> multicategory)
def chng_blnk(o):
if o == '': return []
return oI haven’t tried that but it would be more intuitive for this to be baked into the framework (else anyone doing multi-label will have to add the additional transform. I think this is easier:
return TensorMultiCategory([self.vocab.o2i[o_] for o_ in o if o != ['']])
Oh I see, python is being playful and ''.split(' ') does not return [].
Is it the responsibility of MultiCategorize? No. It clearly says in the documentation that this transform expects a list of labels. This is a failure of your labelling function, not MultiCategorize. Note that there is a ColLabeller transform that will not fail on empty labels:
df = pd.DataFrame({'a': ['a b', '', 'c']})
tfm = ColReader('a', label_delim=' ')
[tfm(df.iloc[i]) for i in range(3)]
returns [['a', 'b'], [], ['c']]. I think you should use it
2 Likes
That seems a bit harsh to me - no reason we can’t/shouldn’t make this work, is there? Is there a time where an empty string is wanted?
1 Like
It could be a label in some cases, since it’s a string. I think that behavior is unwanted magic.