Yah that works … thanks.
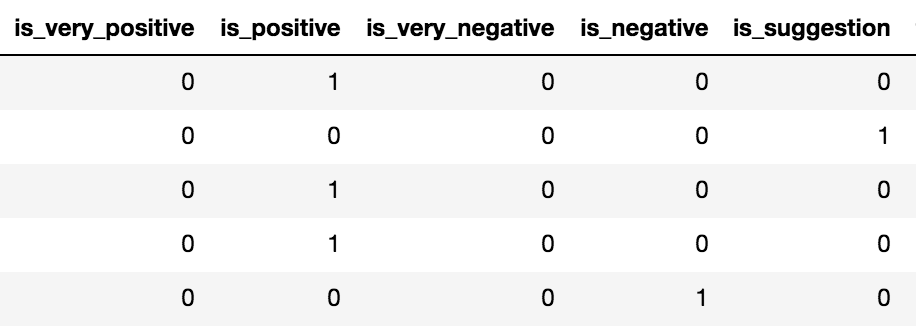
What if instead of all the labels space delimited in a single column … we have one column per label, each being 0 or 1? For example, a DataFrame that looks something like this w/r/t the labels:
Yah that works … thanks.
What if instead of all the labels space delimited in a single column … we have one column per label, each being 0 or 1? For example, a DataFrame that looks something like this w/r/t the labels:
Normally, if you pass a list of labels to ColReader, it assumes they are one-hot encoded.
I would expect the behavior would be the same whether we put all the labels in a single column or each label in a separate column, but they aren’t.
Apporach #1:
vocab for the targetsTensorMultiCategoryx_tfms = [
attrgetter('text'),
Tokenizer.from_df(text_cols=corpus_cols, rules=custom_tok_rules, mark_fields=include_fld_tok),
Numericalize(vocab=vocab)
]
y_tfms = [
ColReader('labels', label_delim=' '),
MultiCategorize(vocab=SENT_LABELS[1:], add_na=False)
]
dsets = Datasets(items=df,
tfms=[x_tfms, y_tfms],
splits=ColSplitter(col='is_valid')(df),
dl_type=SortedDL)
print(dsets.train[21])
#(TensorText([ 2, 8, 10, 146, 518, 19, 1392, 34, 21, 53,
# 221, 11, 111, 29, 15, 961, 68, 3102, 533, 200,
# 14, 23, 11, 10426, 22, 487, 48, 0, 243, 20,
# 393, 9, 1434, 159, 16, 12065, 3410, 9, 14, 437,
# 15, 563, 97, 30, 210, 4183, 161, 11518, 13, 231,
# 754, 1852, 9, 8, 35, 16, 67, 2698, 1354, 22,
# 9, 8, 12, 28, 460, 170, 1253, 11, 4013, 9,
# 14, 260, 205, 95, 16, 18, 4929, 13, 46, 36,
# 39, 355, 22, 1877, 59, 9, 8, 14, 189, 382,
# 1042, 205, 210, 9]), TensorMultiCategory([6, 2]))
dsets.show(dsets.train[21])
#xxbos xxmaj the pay stations for visitor parking are so difficult to use with a credit / debit card … i have #to insert that thing like xxunk before it works . enforcement ▁ is legitimately insane . i got a ticket #because my permit fell over sideways , still completely visible . xxmaj there is no rule against that . #xxmaj and they almost never listen to appeals . i understand your department is in debt , but do n't pass #that onto me . xxmaj i 'm already buying your permit .
#is_very_negative;is_negative
Apporach #2:
vocab for the targets(0, 0, 1, 1, 0, 0, 0, 0))x_tfms = [
attrgetter('text'),
Tokenizer.from_df(text_cols=corpus_cols, rules=custom_tok_rules, mark_fields=include_fld_tok),
Numericalize(vocab=vocab)
]
y_tfms = [
ColReader(SENT_LABELS[1:])
]
dsets = Datasets(items=df,
tfms=[x_tfms, y_tfms],
splits=ColSplitter(col='is_valid')(df),
dl_type=SortedDL)
print(dsets.train[21])
#(TensorText([ 2, 8, 10, 146, 518, 19, 1392, 34, 21, 53,
# 221, 11, 111, 29, 15, 961, 68, 3102, 533, 200,
# 14, 23, 11, 10426, 22, 487, 48, 0, 243, 20,
# 393, 9, 1434, 159, 16, 12065, 3410, 9, 14, 437,
# 15, 563, 97, 30, 210, 4183, 161, 11518, 13, 231,
# 754, 1852, 9, 8, 35, 16, 67, 2698, 1354, 22,
# 9, 8, 12, 28, 460, 170, 1253, 11, 4013, 9,
# 14, 260, 205, 95, 16, 18, 4929, 13, 46, 36,
# 39, 355, 22, 1877, 59, 9, 8, 14, 189, 382,
# 1042, 205, 210, 9]), (0, 0, 1, 1, 0, 0, 0, 0))
dsets.show(dsets.train[21])
# xxbos xxmaj the pay stations for visitor parking are so difficult to use with a credit / debit card … i have # to insert that thing like xxunk before it works . enforcement ▁ is legitimately insane . i got a ticket
# because my permit fell over sideways , still completely visible . xxmaj there is no rule against that .
# xxmaj and they almost never listen to appeals . i understand your department is in debt , but do n't pass
# that onto me . xxmaj i 'm already buying your permit .
Also when I call dls.show_batch using either approach, I get an exception (but that is for a different post).
Note that OneHotEncode is a separate transform from MultiCategorize (which you will need to add in approach 1 or your loss function won’t be happy). In the second approach, if you add it with the proper vocab, show will work.
At the higher level, the data block API does all of that for you (as long as you pass the right block).
How do you add it with the proper vocab? OneHotEncode doesn’t take a vocab (just a c).
Ah yes, sorry you need EncodedMultiCategorize for encoded labels, and the OneHot transform in both. Look at the data.transforms notebook for examples.
Also note that the low level API is meant to be used when you have to write your own transforms for specific tasks. In your case, everything is handled by the data block API at the upper level.
Understood. I just find that it helps me understand what is going on once I’m able to implement things with the low level APIs
Btw, this still doesn’t seem to work (assuming I’ve added the transforms together properly):
y_tfms = [
ColReader(SENT_LABELS[1:]),
EncodedMultiCategorize(vocab=SENT_LABELS[1:]),
OneHotEncode()
]
Exception:
IndexError Traceback (most recent call last)
<timed exec> in <module>
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/core.py in __init__(self, items, tfms, tls, n_inp, dl_type, **kwargs)
259 def __init__(self, items=None, tfms=None, tls=None, n_inp=None, dl_type=None, **kwargs):
260 super().__init__(dl_type=dl_type)
--> 261 self.tls = L(tls if tls else [TfmdLists(items, t, **kwargs) for t in L(ifnone(tfms,[None]))])
262 self.n_inp = (1 if len(self.tls)==1 else len(self.tls)-1) if n_inp is None else n_inp
263
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/core.py in <listcomp>(.0)
259 def __init__(self, items=None, tfms=None, tls=None, n_inp=None, dl_type=None, **kwargs):
260 super().__init__(dl_type=dl_type)
--> 261 self.tls = L(tls if tls else [TfmdLists(items, t, **kwargs) for t in L(ifnone(tfms,[None]))])
262 self.n_inp = (1 if len(self.tls)==1 else len(self.tls)-1) if n_inp is None else n_inp
263
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/foundation.py in __call__(cls, x, *args, **kwargs)
39 return x
40
---> 41 res = super().__call__(*((x,) + args), **kwargs)
42 res._newchk = 0
43 return res
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/core.py in __init__(self, items, tfms, use_list, do_setup, split_idx, train_setup, splits, types, verbose)
200 if do_setup:
201 pv(f"Setting up {self.tfms}", verbose)
--> 202 self.setup(train_setup=train_setup)
203
204 def _new(self, items, **kwargs): return super()._new(items, tfms=self.tfms, do_setup=False, types=self.types, **kwargs)
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/core.py in setup(self, train_setup)
219 for f in self.tfms.fs:
220 self.types.append(getattr(f, 'input_types', type(x)))
--> 221 x = f(x)
222 self.types.append(type(x))
223 types = L(t if is_listy(t) else [t] for t in self.types).concat().unique()
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/transform.py in __call__(self, x, **kwargs)
70 @property
71 def name(self): return getattr(self, '_name', _get_name(self))
---> 72 def __call__(self, x, **kwargs): return self._call('encodes', x, **kwargs)
73 def decode (self, x, **kwargs): return self._call('decodes', x, **kwargs)
74 def __repr__(self): return f'{self.name}: {self.encodes} {self.decodes}'
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/transform.py in _call(self, fn, x, split_idx, **kwargs)
82 f = getattr(self, fn)
83 if not _is_tuple(x): return self._do_call(f, x, **kwargs)
---> 84 res = tuple(self._do_call(f, x_, **kwargs) for x_ in x)
85 return retain_type(res, x)
86
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/transform.py in <genexpr>(.0)
82 f = getattr(self, fn)
83 if not _is_tuple(x): return self._do_call(f, x, **kwargs)
---> 84 res = tuple(self._do_call(f, x_, **kwargs) for x_ in x)
85 return retain_type(res, x)
86
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/transform.py in _do_call(self, f, x, **kwargs)
86
87 def _do_call(self, f, x, **kwargs):
---> 88 return x if f is None else retain_type(f(x, **kwargs), x, f.returns_none(x))
89
90 add_docs(Transform, decode="Delegate to `decodes` to undo transform", setup="Delegate to `setups` to set up transform")
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/dispatch.py in __call__(self, *args, **kwargs)
96 if not f: return args[0]
97 if self.inst is not None: f = MethodType(f, self.inst)
---> 98 return f(*args, **kwargs)
99
100 def __get__(self, inst, owner):
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/transforms.py in encodes(self, o)
237 if not self.c: warn("Couldn't infer the number of classes, please pass a value for `c` at init")
238
--> 239 def encodes(self, o): return TensorMultiCategory(one_hot(o, self.c).float())
240 def decodes(self, o): return one_hot_decode(o, None)
241
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/torch_core.py in one_hot(x, c)
490 "One-hot encode `x` with `c` classes."
491 res = torch.zeros(c, dtype=torch.uint8)
--> 492 if isinstance(x, Tensor) and x.numel()>0: res[x] = 1.
493 else: res[list(L(x, use_list=None))] = 1.
494 return res
IndexError: tensors used as indices must be long, byte or bool tensors
Mmmm, are your columns considered as floats by any chance (still needs a fix in fastai2 if that’s the case, just trying to find the problem).
If you %debug, that is x? What is its dtype?
No, they are int64 …
is_very_positive int64
is_positive int64
is_very_negative int64
is_negative int64
is_suggestion int64
So trying using the DataBlock API …
cls_blocks = (
TextBlock.from_df(corpus_cols, vocab=vocab, seq_len=bptt, rules=custom_tok_rules, mark_fields=include_fld_tok),
MultiCategoryBlock(encoded=True, vocab=SENT_LABELS[1:])
)
cls_dblock = DataBlock(blocks=cls_blocks,
get_x=ColReader('text'),
get_y=ColReader(SENT_LABELS[1:]),
splitter=ColSplitter(col='is_valid'))
… does not work as intended (perhaps I’m missing a block???) … dls.show_batch() throws the following exception:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-283-90634fcc3c9e> in <module>
----> 1 dls.show_batch()
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/core.py in show_batch(self, b, max_n, ctxs, show, **kwargs)
90 if b is None: b = self.one_batch()
91 if not show: return self._pre_show_batch(b, max_n=max_n)
---> 92 show_batch(*self._pre_show_batch(b, max_n=max_n), ctxs=ctxs, max_n=max_n, **kwargs)
93
94 def show_results(self, b, out, max_n=9, ctxs=None, show=True, **kwargs):
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/core.py in _pre_show_batch(self, b, max_n)
83 b = self.decode(b)
84 if hasattr(b, 'show'): return b,None,None
---> 85 its = self._decode_batch(b, max_n, full=False)
86 if not is_listy(b): b,its = [b],L((o,) for o in its)
87 return detuplify(b[:self.n_inp]),detuplify(b[self.n_inp:]),its
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/core.py in _decode_batch(self, b, max_n, full)
77 f = self.after_item.decode
78 f = compose(f, partial(getattr(self.dataset,'decode',noop), full = full))
---> 79 return L(batch_to_samples(b, max_n=max_n)).map(f)
80
81 def _pre_show_batch(self, b, max_n=9):
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/foundation.py in map(self, f, *args, **kwargs)
360 else f.format if isinstance(f,str)
361 else f.__getitem__)
--> 362 return self._new(map(g, self))
363
364 def filter(self, f, negate=False, **kwargs):
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/foundation.py in _new(self, items, *args, **kwargs)
313 @property
314 def _xtra(self): return None
--> 315 def _new(self, items, *args, **kwargs): return type(self)(items, *args, use_list=None, **kwargs)
316 def __getitem__(self, idx): return self._get(idx) if is_indexer(idx) else L(self._get(idx), use_list=None)
317 def copy(self): return self._new(self.items.copy())
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/foundation.py in __call__(cls, x, *args, **kwargs)
39 return x
40
---> 41 res = super().__call__(*((x,) + args), **kwargs)
42 res._newchk = 0
43 return res
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/foundation.py in __init__(self, items, use_list, match, *rest)
304 if items is None: items = []
305 if (use_list is not None) or not _is_array(items):
--> 306 items = list(items) if use_list else _listify(items)
307 if match is not None:
308 if is_coll(match): match = len(match)
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/foundation.py in _listify(o)
240 if isinstance(o, list): return o
241 if isinstance(o, str) or _is_array(o): return [o]
--> 242 if is_iter(o): return list(o)
243 return [o]
244
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/foundation.py in __call__(self, *args, **kwargs)
206 if isinstance(v,_Arg): kwargs[k] = args.pop(v.i)
207 fargs = [args[x.i] if isinstance(x, _Arg) else x for x in self.pargs] + args[self.maxi+1:]
--> 208 return self.fn(*fargs, **kwargs)
209
210 # Cell
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/utils.py in _inner(x, *args, **kwargs)
339 if order is not None: funcs = funcs.sorted(order)
340 def _inner(x, *args, **kwargs):
--> 341 for f in L(funcs): x = f(x, *args, **kwargs)
342 return x
343 return _inner
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/core.py in decode(self, o, full)
271 def __iter__(self): return (self[i] for i in range(len(self)))
272 def __repr__(self): return coll_repr(self)
--> 273 def decode(self, o, full=True): return tuple(tl.decode(o_, full=full) for o_,tl in zip(o,tuplify(self.tls, match=o)))
274 def subset(self, i): return type(self)(tls=L(tl.subset(i) for tl in self.tls), n_inp=self.n_inp)
275 def _new(self, items, *args, **kwargs): return super()._new(items, tfms=self.tfms, do_setup=False, **kwargs)
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/core.py in <genexpr>(.0)
271 def __iter__(self): return (self[i] for i in range(len(self)))
272 def __repr__(self): return coll_repr(self)
--> 273 def decode(self, o, full=True): return tuple(tl.decode(o_, full=full) for o_,tl in zip(o,tuplify(self.tls, match=o)))
274 def subset(self, i): return type(self)(tls=L(tl.subset(i) for tl in self.tls), n_inp=self.n_inp)
275 def _new(self, items, *args, **kwargs): return super()._new(items, tfms=self.tfms, do_setup=False, **kwargs)
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/core.py in decode(self, o, **kwargs)
208 def __iter__(self): return (self[i] for i in range(len(self)))
209 def show(self, o, **kwargs): return self.tfms.show(o, **kwargs)
--> 210 def decode(self, o, **kwargs): return self.tfms.decode(o, **kwargs)
211 def __call__(self, o, **kwargs): return self.tfms.__call__(o, **kwargs)
212 def overlapping_splits(self): return L(Counter(self.splits.concat()).values()).filter(gt(1))
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/transform.py in decode(self, o, full)
195 for f in reversed(self.fs):
196 if self._is_showable(o): return o
--> 197 o = f.decode(o, split_idx=self.split_idx)
198 return o
199
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/transform.py in decode(self, x, **kwargs)
71 def name(self): return getattr(self, '_name', _get_name(self))
72 def __call__(self, x, **kwargs): return self._call('encodes', x, **kwargs)
---> 73 def decode (self, x, **kwargs): return self._call('decodes', x, **kwargs)
74 def __repr__(self): return f'{self.name}: {self.encodes} {self.decodes}'
75
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/transform.py in _call(self, fn, x, split_idx, **kwargs)
82 f = getattr(self, fn)
83 if not _is_tuple(x): return self._do_call(f, x, **kwargs)
---> 84 res = tuple(self._do_call(f, x_, **kwargs) for x_ in x)
85 return retain_type(res, x)
86
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/transform.py in <genexpr>(.0)
82 f = getattr(self, fn)
83 if not _is_tuple(x): return self._do_call(f, x, **kwargs)
---> 84 res = tuple(self._do_call(f, x_, **kwargs) for x_ in x)
85 return retain_type(res, x)
86
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/transform.py in _do_call(self, f, x, **kwargs)
86
87 def _do_call(self, f, x, **kwargs):
---> 88 return x if f is None else retain_type(f(x, **kwargs), x, f.returns_none(x))
89
90 add_docs(Transform, decode="Delegate to `decodes` to undo transform", setup="Delegate to `setups` to set up transform")
~/development/_training/ml/nlp-playground/_libs/fastcore/fastcore/dispatch.py in __call__(self, *args, **kwargs)
96 if not f: return args[0]
97 if self.inst is not None: f = MethodType(f, self.inst)
---> 98 return f(*args, **kwargs)
99
100 def __get__(self, inst, owner):
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/data/transforms.py in decodes(self, o)
246 def __init__(self, vocab): self.vocab,self.c = vocab,len(vocab)
247 def encodes(self, o): return TensorCategory(tensor(o).float())
--> 248 def decodes(self, o): return MultiCategory (one_hot_decode(o, self.vocab))
249
250 # Cell
~/development/_training/ml/nlp-playground/_libs/fastai2/fastai2/torch_core.py in one_hot_decode(x, vocab)
496 # Cell
497 def one_hot_decode(x, vocab=None):
--> 498 return L(vocab[i] if vocab else i for i,x_ in enumerate(x) if x_==1)
499
500 # Cell
~/anaconda3/envs/playground-nlp/lib/python3.7/site-packages/torch/tensor.py in __iter__(self)
454 # map will interleave them.)
455 if self.dim() == 0:
--> 456 raise TypeError('iteration over a 0-d tensor')
457 if torch._C._get_tracing_state():
458 warnings.warn('Iterating over a tensor might cause the trace to be incorrect. '
TypeError: iteration over a 0-d tensor
I did notice that each target is a tuple of TensorCategory objects (e.g., (TensorCategory(0.), TensorCategory(0.), TensorCategory(1.), TensorCategory(1.), TensorCategory(0.), TensorCategory(0.), TensorCategory(0.), TensorCategory(0.)))
rather than a single TensorMultiCategory object such as I get when I use a single column with the labels space-delimited.
I think the problem is in EncodedMultiCategorize.
The encodes should return a TensorCategory that is a long:
def encodes(self, o): return TensorCategory(tensor(o).long())
Right now its a float and if you add the OneHotEncode you get an exception … IndexError: tensors used as indices must be long, byte or bool tensors
Sorry, looked again this morning and EncodedMultiCategorize works on its own without OneHotEncode (don’t trust me, trsut the notebook and the tests that are there). For your data block, you should tell your block your categories are onehot encoded by using MultiCategoryBlock(encoded=True) (a block does not have access to the data, so it can’t guess anything).
… unfortunately your tests don’t account for tuples (which is what ColReader returns).
_tfm = EncodedMultiCategorize(vocab=['no', 'yes'])
_tfm([0,1])
# returns TensorCategory([0., 1.]))
_tfm((0,1))
# returns ((TensorCategory(0.), TensorCategory(1.))
I also don’t understand why it returns TensorCategory instead of TensorMultiCategory (the later seems more appropriate given that the transform is for multi-labelled datasets and is what both OneHotEncode and MultiCategorize return via encodes).
Fixed those two things.
Checks out. Thanks!
I am having issues getting a text model up and running in fastai v2. I am worked with protein sequences, hence I need to define a custom tokenizer.
from fastai2.basics import *
from fastai2.text.all import *
BOS,EOS,FLD,UNK,PAD = 'xxbos','xxeos','xxfld','xxunk','xxpad'
TK_MAJ,TK_UP,TK_REP,TK_WREP = 'xxmaj','xxup','xxrep','xxwrep'
defaults.text_spec_tok = [PAD]
class MolTokenizer(BaseTokenizer):
def __init__(self, split_char=' '):
self.split_char = ' '
def __call__(self, items):
return ( ['GO']+list(t.upper() )+['END'] for t in items)
I then begin with the following
bs = 64
corpus_train = pd.read_csv('./processed/train.csv.gzip',index_col=None, compression='gzip')
corpus_valid = pd.read_csv('./processed/valid.csv.gzip',index_col=None, compression='gzip')
corpus_train['is_valid'] = False
corpus_valid['is_valid'] = True
corpus = corpus_train.append(corpus_valid, ignore_index=True)
path = './test/'
df_tok, count = tokenize_df(corpus, 'sequence', rules=[], tok_func=partial(MolTokenizer))
dls_lm = TextDataLoaders.from_df(df_tok, path=path, text_vocab=make_vocab(count,min_freq=1), text_col='text', is_lm=True, valid_col='is_valid')
everything checks out for my vocab
dls_lm.train_ds.vocab
['xxpad', 'L', 'A', 'G', 'V', 'E', 'S', 'I', 'K', 'R', 'D', 'T', 'P', 'N', 'Q', 'F', 'Y', 'M', 'H', 'C', 'W', 'GO', 'END', 'xxfake']
and df_tok looks good
df_tok.text.head(2)
0 [GO, M, A, N, Y, T, A, A, D, I, K, A, L, R, E, R, T, G, A, G, M, M, D, V, K, K, A, L, D, E, A, N, G, D, A, E, K, A, I, E, I, I, R, I, K, G, L, K, G, A, T, K, R, E, G, R, S, T, A, E, G, L, V, A, A, K, V, N, G, G, V, G, V, M, I, E, V, N, C, E, T, D, F, V, A, K, A, D, K, F, I, Q, L, A, D, K, V, L, N, V, ...]
1 [GO, M, P, K, S, R, R, A, V, S, L, S, V, L, I, G, A, V, I, A, A, L, A, G, A, L, I, A, V, T, V, P, A, R, P, N, R, P, E, A, D, R, E, A, L, W, K, I, V, H, D, R, C, E, F, G, Y, R, R, T, G, A, Y, A, P, C, T, F, V, D, E, Q, S, G, T, A, L, Y, K, A, D, F, D, P, Y, Q, F, L, L, I, P, L, A, R, I, T, G, I, E, D, ...]
However, there is something going on either during numericalization or generating the batches
xx, yy = dls_lm.one_batch()
xx[:5]
tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
device='cuda:1')
All my data gets numericalized to a zero token. Does anyone see what I am doing wrong?
It seems the FastAI/Fastbook tutorials/lectures for NLP focus on English, especially with the use of Spacy. If more effort would be given to non-western languages, especially from the global south, or at the very least using a neutral tokenizer (such as sentencepiece) as the default, rather than an western opinionated tokenizer (Spacy) as the default it would go a long way to greater inclusion and diversity.
How would one use FastAI’s sentencepiece into this fastbook tutorial? https://github.com/fastai/fastbook/blob/master/10_nlp.ipynb?
I’ve had to manually build the sentencepiece model, vocab – but unsure how to plug this into the provide notebook. In particular how would I plug sentencepiece to FastAI2’s Tokenizer class?
I’m curious, what languages do you have in mind? Is tokenization so different in these cases? I know for some languages (Chinese being an obvious example) tokenization is very different.
I’m focusing on Nguni languages (Southern Africa) and In previous FastAI versions (pt.2 2018) I was able to use SentencePiece. The FastAI2 version is not so clear on how to go from
SentencePieceTokenizer to dls_lm
dls_lm = DataBlock(
blocks=TextBlock.from_folder(path, is_lm=True),
get_items=get_imdb, splitter=RandomSplitter(0.1)
).dataloaders(path, path=path, bs=128, seq_len=80)```
and finally to
dls_lm, AWD_LSTM, drop_mult=0.3,
metrics=[accuracy, Perplexity()]).to_fp16()