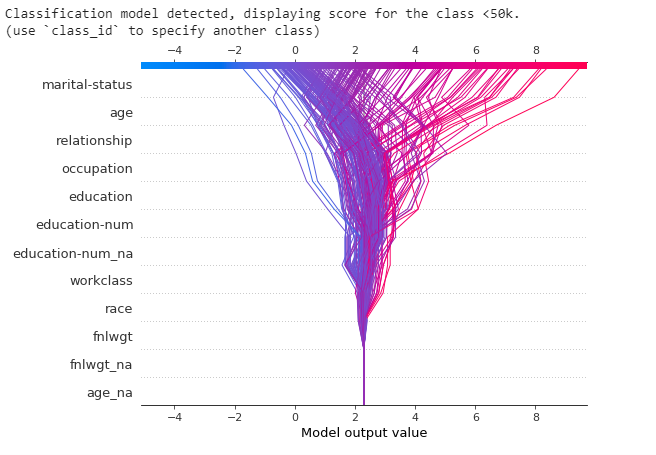
Following the Integration Example from the docs using NCAA tournament data, I’m getting a TypeError: can't convert CUDA tensor to numpy. Seems to result from the loss function (sklearn log_loss), but I don’t know how to fix it. Tried other loss functions, but no luck.
dep_var = 'result'
cat_vars = ['Season', 'TeamId_1', 'TeamId_2', 'Coach_1', 'Coach_2',
'Top5_1', 'Top5_2', 'Top25_1', 'Top25_2', 'Top50_1', 'Top50_2',
'ConfAbbrev_1', 'ConfAbbrev_2', 'Is_ConfGm', 'isMajor_1', 'isMajor_2']
cont_vars = [c for c in df.columns if c not in cat_vars]
cont_vars.remove('result')
procs=[FillMissing, Categorify, Normalize]
splits = RandomSplitter()(range_of(df))
to = TabularPandas(df, procs, cat_vars, cont_vars, y_names=dep_var, splits=splits)
dls = to.dataloaders()
learn = tabular_learner(dls, layers=[200,100], n_out=1, loss_func=log_loss,
metrics=[accuracy])
learn.lr_find()
learn.recorder.plot()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-44-c7a9c29f9dd1> in <module>
----> 1 learn.lr_find()
2 learn.recorder.plot()
~/git/fastai2/nbs/mine/fastai2/callback/schedule.py in lr_find(self, start_lr, end_lr, num_it, stop_div, show_plot, suggestions)
196 n_epoch = num_it//len(self.dls.train) + 1
197 cb=LRFinder(start_lr=start_lr, end_lr=end_lr, num_it=num_it, stop_div=stop_div)
--> 198 with self.no_logging(): self.fit(n_epoch, cbs=cb)
199 if show_plot: self.recorder.plot_lr_find()
200 if suggestions:
~/git/fastai2/nbs/mine/fastai2/learner.py in fit(self, n_epoch, lr, wd, cbs, reset_opt)
292 try:
293 self.epoch=epoch; self('begin_epoch')
--> 294 self._do_epoch_train()
295 self._do_epoch_validate()
296 except CancelEpochException: self('after_cancel_epoch')
~/git/fastai2/nbs/mine/fastai2/learner.py in _do_epoch_train(self)
267 try:
268 self.dl = self.dls.train; self('begin_train')
--> 269 self.all_batches()
270 except CancelTrainException: self('after_cancel_train')
271 finally: self('after_train')
~/git/fastai2/nbs/mine/fastai2/learner.py in all_batches(self)
245 def all_batches(self):
246 self.n_iter = len(self.dl)
--> 247 for o in enumerate(self.dl): self.one_batch(*o)
248
249 def one_batch(self, i, b):
~/git/fastai2/nbs/mine/fastai2/learner.py in one_batch(self, i, b)
253 self.pred = self.model(*self.xb); self('after_pred')
254 if len(self.yb) == 0: return
--> 255 self.loss = self.loss_func(self.pred, *self.yb); self('after_loss')
256 if not self.training: return
257 self.loss.backward(); self('after_backward')
~/anaconda3/lib/python3.7/site-packages/sklearn/metrics/_classification.py in log_loss(y_true, y_pred, eps, normalize, sample_weight, labels)
2239 The logarithm used is the natural logarithm (base-e).
2240 """
-> 2241 y_pred = check_array(y_pred, ensure_2d=False)
2242 check_consistent_length(y_pred, y_true, sample_weight)
2243
~/anaconda3/lib/python3.7/site-packages/sklearn/utils/validation.py in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, warn_on_dtype, estimator)
529 array = array.astype(dtype, casting="unsafe", copy=False)
530 else:
--> 531 array = np.asarray(array, order=order, dtype=dtype)
532 except ComplexWarning:
533 raise ValueError("Complex data not supported\n"
~/anaconda3/lib/python3.7/site-packages/numpy/core/_asarray.py in asarray(a, dtype, order)
83
84 """
---> 85 return array(a, dtype, copy=False, order=order)
86
87
~/anaconda3/lib/python3.7/site-packages/torch/tensor.py in __array__(self, dtype)
447 def __array__(self, dtype=None):
448 if dtype is None:
--> 449 return self.numpy()
450 else:
451 return self.numpy().astype(dtype, copy=False)
TypeError: can't convert CUDA tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.