I don’t understand your question. Those patched encodes and decodes are in tabular.core.
1 Like
I guess my question is will we ever support non-encoded multi-categorize? Instead of having to pre-process the one hot encode. Similar to how in the PLANETs we can pass in a delimiter to get_y. (I understand the two are separate from just MultiCategoryBlock, so this may not be straightforward to do)
If not, I’ll emphasize this in the docs 
There is an example of that and the needed patches on MultiCategorize just after in the notebook.
Oh, though it’s not currently working. Guess there is a TODO to fix it missing.
2 Likes
For those interested, I’m working on trying to get fastai2 tabular to support multiple datatypes. This is based on my NumPy tutorial, and as we go along I think we’ll find a good way to integrate it to the ecosystem towards something we could possibly push to the main repo. If you’re interested in helping, see here:
Currently we’re looking at NumPy, cuDF, and others.
2 Likes
Does anyone know what the line
df[prefix + ‘Elapsed’] = field.astype(np.int64) // 10 ** 9
in add_datepart does exactly? I don’t really understand how to interpret the resulting feature.
Here is the full source code:
def add_datepart(df, field_name, prefix=None, drop=True, time=False):
"Helper function that adds columns relevant to a date in the column `field_name` of `df`."
make_date(df, field_name)
field = df[field_name]
prefix = ifnone(prefix, re.sub('[Dd]ate$', '', field_name))
attr = ['Year', 'Month', 'Week', 'Day', 'Dayofweek', 'Dayofyear', 'Is_month_end', 'Is_month_start',
'Is_quarter_end', 'Is_quarter_start', 'Is_year_end', 'Is_year_start']
if time: attr = attr + ['Hour', 'Minute', 'Second']
for n in attr: df[prefix + n] = getattr(field.dt, n.lower())
df[prefix + 'Elapsed'] = field.astype(np.int64) // 10 ** 9
if drop: df.drop(field_name, axis=1, inplace=True)
return df
Hi,
I’m trying to use tabular for a regression problem but am confused about the prediction output of the learner.
When I use learn.show_results(), I see the result in the y_pred column, but when I use learn.get_preds() it outputs 2 tensors and I can’t find documentation on what these are. Are they supposed to be the upper and lower confidence interval for the predictions?
If not, is there a way to get a a confidence interval for our prediction? This would be useful in the case of the latest Kaggle challenge for example: https://www.kaggle.com/c/osic-pulmonary-fibrosis-progression/overview/evaluation
Thanks,
Elliot
Can you provide a sample output of get_preds for one sample? (I haven’t played with regression much)
Hey Zach,
I’m trying to run something super simple to get a sense of the way to use fastaiv2 for it.
Get the data into TabularDataLoader:
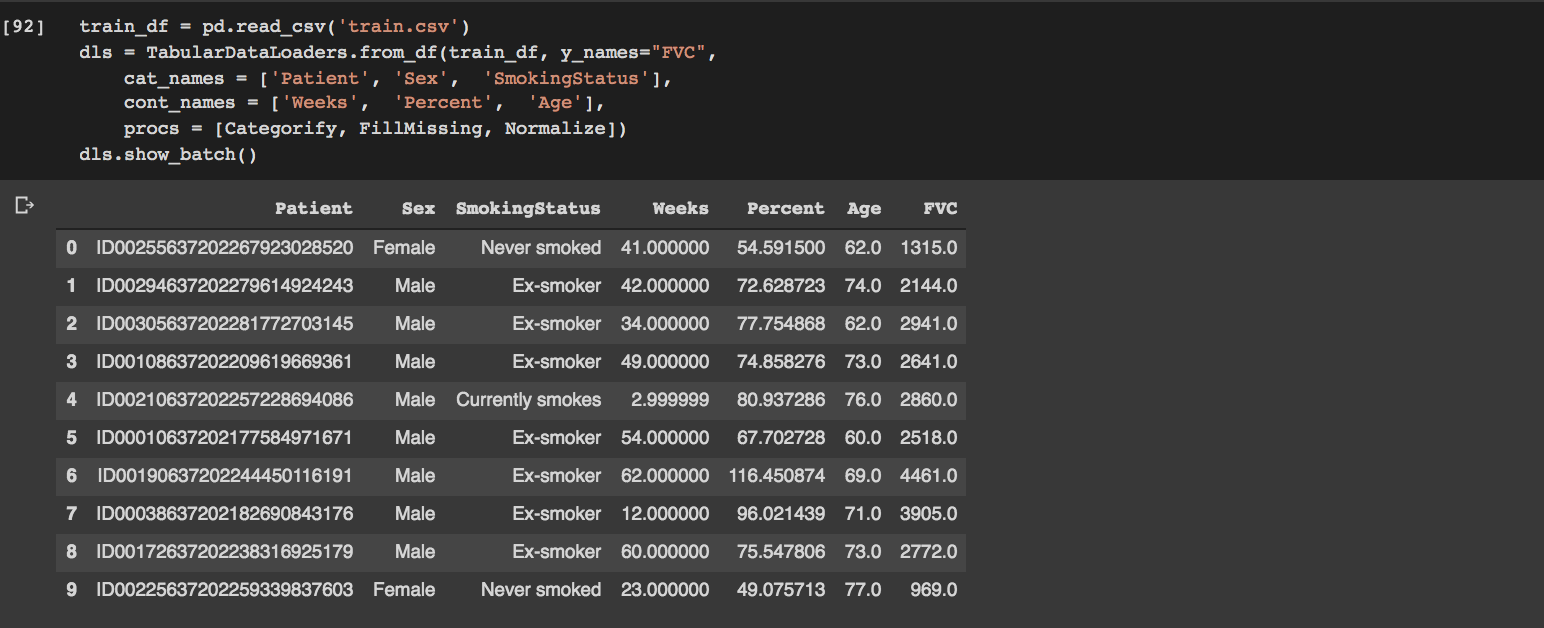
Train the model:
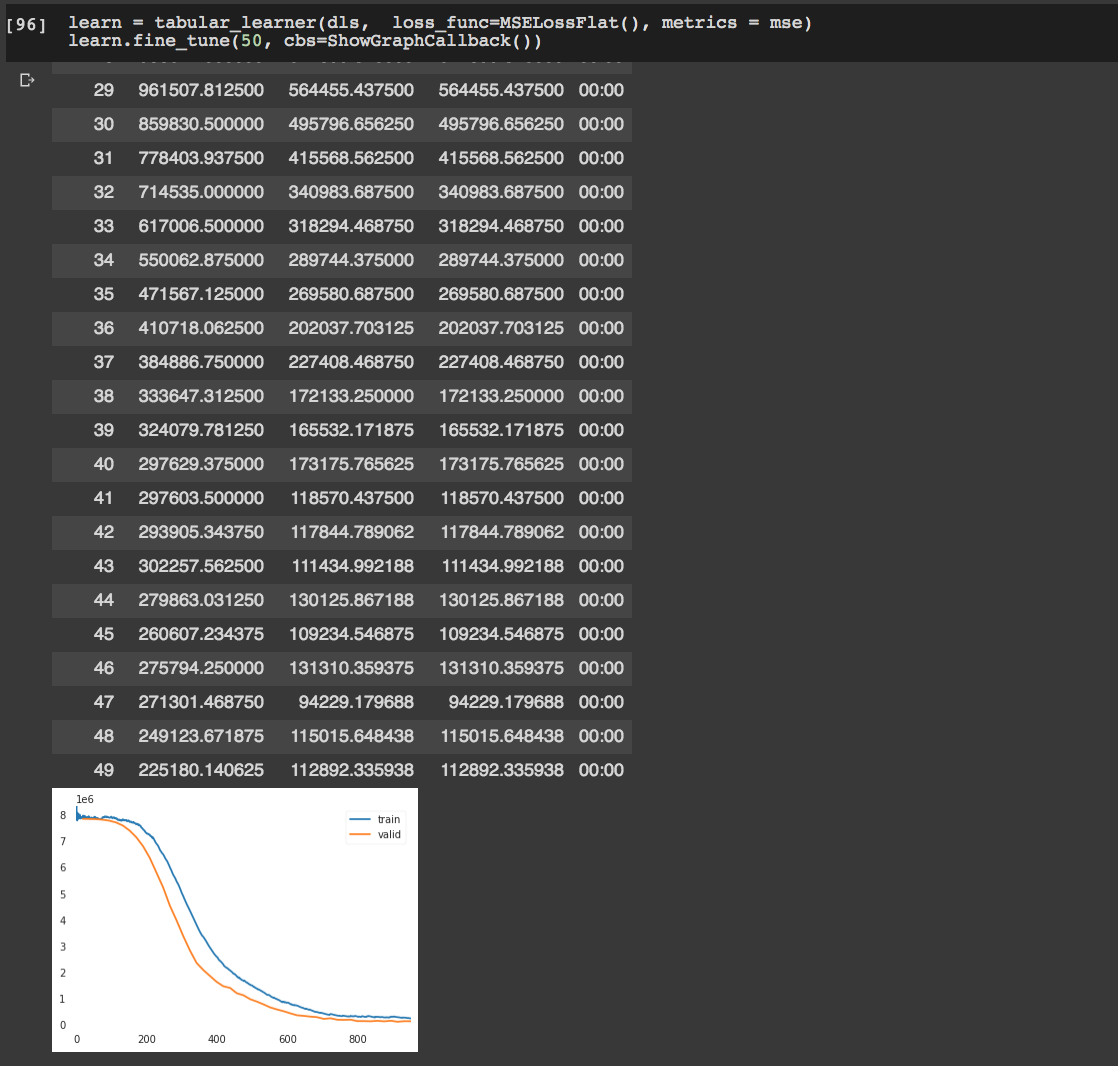
When I use show_results(), that’s what I’m getting:
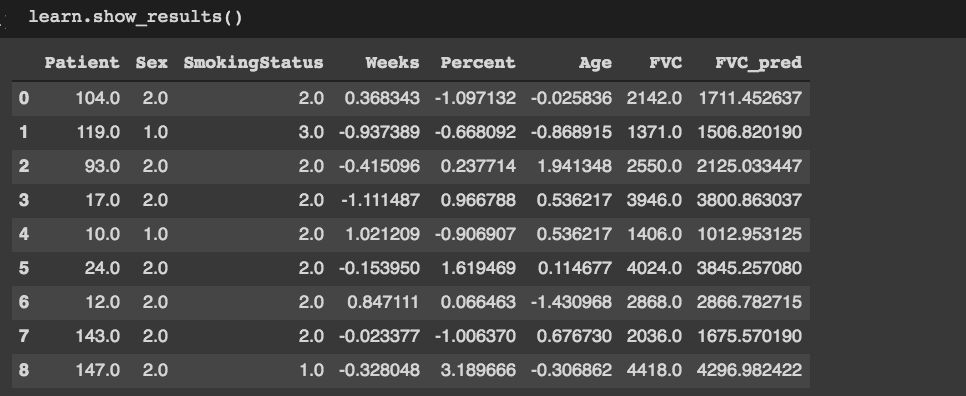
And when I use get_preds() it returns a tuple of tensors looking like this (for the first 5 elements):
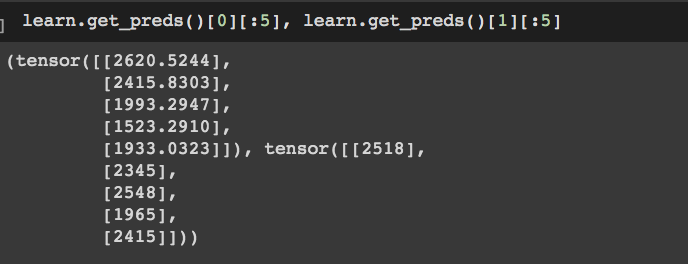
I might be wrong in the way I’m training or something else so please feel free to tell me if I’m completely off.
Thanks!
Hello, @muellerzr
I think there is a mistake in the code from the fastbook/09_tabular ,
in the image ,I run the code with the red underline and I got error,
I think it refers to xs_filt …
may you can clarify it ? it will be really nice,
Best regards,
Luis t

I have a random forest model and used TabularPandas() to do the normal preprocessing (Normalize, FillMissing and Categorify). Now I would like to share the model and the preprocessing with a partner without sharing the data. This example is listed in the documentation:
to = TabularPandas(df_main, procs, cat_names, cont_names, y_names="salary", splits=splits)
to_tst = to.new(df_test)
to_tst.process()
But that requires saving the entire to object, which includes the data. I couldn’t find way of just grabbing the procs from the TabularPandas object - any thoughts on this?
I want to test this on my side too but you should be able to do to_export = to.new_empty() and then export it for preprocessing.
1 Like
Yes, that works - thanks a lot! A 4 minute response time is also ok I guess ![]()
For reference, I ended up doing this:
to = TabularPandas(df_main, procs, ...)
to_export = to.new_empty() # to_export only has preprocessing meta-data (eg. means/stds)
to_tst = to_export.new(df_test)
to_tst.process() # tf_tst can now be passed to the model
1 Like
Differences observed between Tabular v1 & v2:
While coding for recent Kaggle Melanoma, I noticed differences between layers generated in fastai v1 & v2 (using 0.0.20)
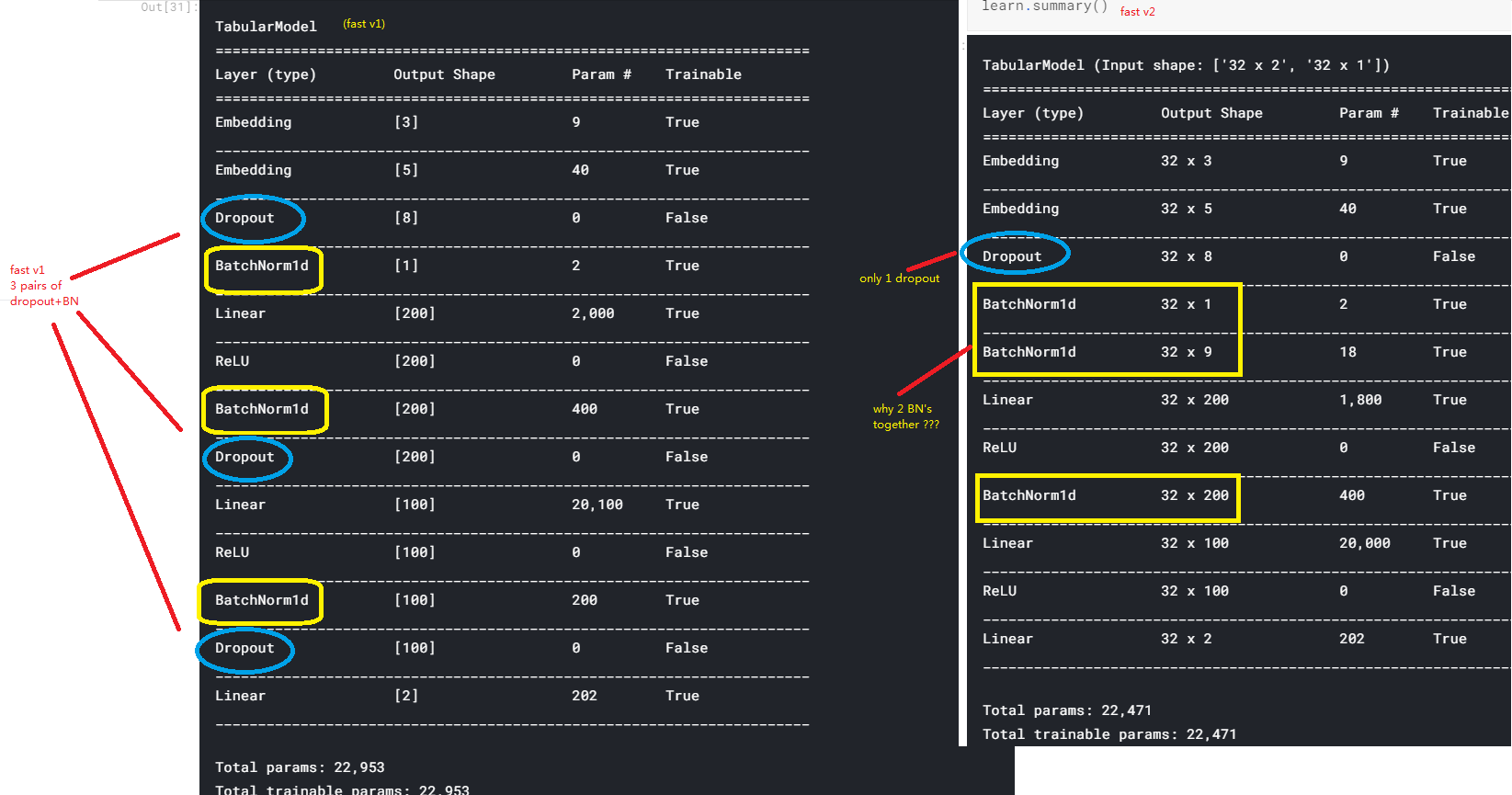
As seen from attached pic, left image is layers generated from v1 Tabular, while right image is layers generated from v2. See my annotations in the pic. Are the differences a Bug or a new Feature ?
Other than above difference, I noticed the LB score by v1 Tabular is about +0.3 points higher than v2 version.
cheers
sid
Not intentional @SidNg. Thanks for pointing this out. When you say “higher” do you mean better loss / accuracy, or worse?
1 Like
@jeremy fastai v1 gets higher LB score (higher roc_auc_score)
1 Like
Hi. I’m currently working on a multiclass classifcation problem with tabular data.
I’m using TabularPandas to prepare the data but I want a specific mapping from target class to integer, so I use: y_block=CategoryBlock(vocab=my_mapping, sort=False) as an argument to TabularPandas. I have noticed that the resulting, transformed target does not match the my_mapping vocab.
If I’m correct, the cause is, when reduce_memory=True in TabularPandas, df_shrink is called and transforms the target variable (if object type) independently to the y_block specified. I’m not sure if this is intentional and if not, what the best alternative is, but a note about this in the docs or code might be helpful in the future.
I’m also willing to help where I can (I’m new to v2) if this is something that needs fixing.
I am also working on a similar problem. When I pass y_block= CategoryBlock to either TabularPandas or tabular_learner the model cannot be trained anymore and fails with ValueError: Expected input batch_size (64) to match target batch_size (13184). I also cannot find an example on TabularPandas for classification anywhere.
There are plenty, first the tabular tutorial in the fastai docs:
https://docs.fast.ai/tutorial.tabular
And in Walk with fastai2:
@Jan did setting reduce_memory to False fix it?
Yes, it seems fastai v2 cannot handle this anymore. It was working with v1.
Can you provide a reproducible example of what’s going on here? I’ve been actively using fastai tabular for months now without issue with both classification and regression problems, and I’m not sure exactly what’s happening to do this.
EDIT: @soerendip very important question: what’s your loss function. I believe you may not be using CrossEntropyLossFlat() which could be affecting it
Currently I’ve tried setting it up in a scenario similar to what I believe yours could be:
path = untar_data(URLs.ADULT_SAMPLE)
df = pd.read_csv(path/'adult.csv')
new_dict = {'<50k':0,
'>=50k':1}
df[y_names].replace(new_dict, inplace=True)
cat_names = ['workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race']
cont_names = ['age', 'fnlwgt', 'education-num']
procs = [Categorify, FillMissing, Normalize]
y_names = 'salary'
y_block = CategoryBlock
splits = RandomSplitter()(range_of(df))
to = TabularPandas(df, procs=procs, cat_names=cat_names, cont_names=cont_names,
y_names=y_names, y_block=y_block, splits=splits)
dls = to.dataloaders()
learn = tabular_learner(dls, layers=[200,100], metrics=accuracy)
And can train without issue. Can you tell me how your DataFrame setup may differ?