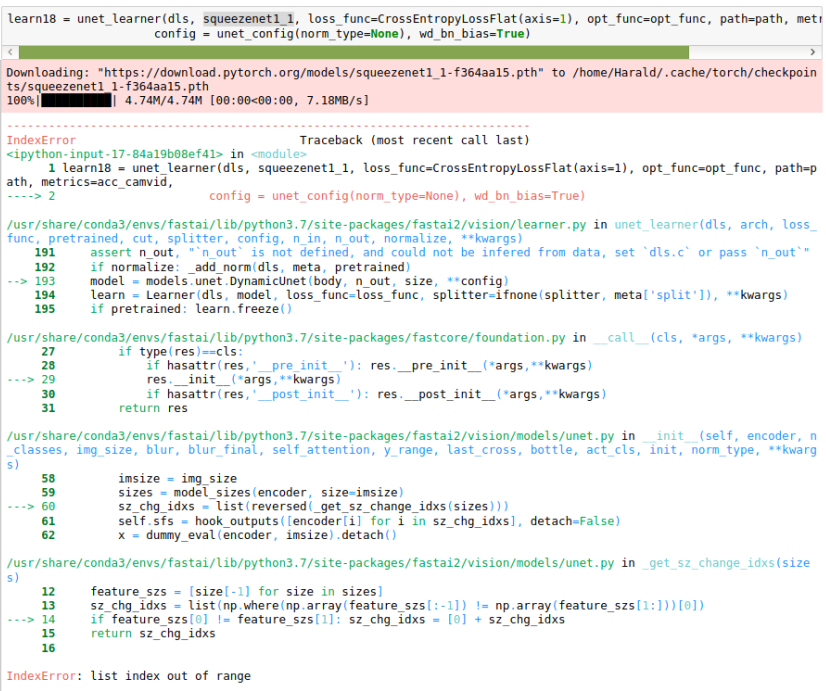
@muellerzr i get below error when i build custom Unet
RuntimeError: running_mean should contain 582 elements not 1164
Any help
171 def _do_one_batch(self):
--> 172 self.pred = self.model(*self.xb)
173 self('after_pred')
174 if len(self.yb):
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
/opt/conda/lib/python3.7/site-packages/fastai/layers.py in forward(self, x)
405 for l in self.layers:
406 res.orig = x
--> 407 nres = l(res)
408 # We have to remove res.orig to avoid hanging refs and therefore memory leaks
409 res.orig, nres.orig = None, None
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1069 input = bw_hook.setup_input_hook(input)
1070
-> 1071 result = forward_call(*input, **kwargs)
1072 if _global_forward_hooks or self._forward_hooks:
1073 for hook in itertools.chain(
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/batchnorm.py in forward(self, input)
176 bn_training,
177 exponential_average_factor,
--> 178 self.eps,
179 )
180
/opt/conda/lib/python3.7/site-packages/torch/nn/functional.py in batch_norm(input, running_mean, running_var, weight, bias, training, momentum, eps)
2274 training=training,
2275 momentum=momentum,
-> 2276 eps=eps,
2277 )
2278 if training:
/opt/conda/lib/python3.7/site-packages/torch/overrides.py in handle_torch_function(public_api, relevant_args, *args, **kwargs)
1250 # Use `public_api` instead of `implementation` so __torch_function__
1251 # implementations can do equality/identity comparisons.
-> 1252 result = overloaded_arg.__torch_function__(public_api, types, args, kwargs)
1253
1254 if result is not NotImplemented:
/opt/conda/lib/python3.7/site-packages/fastai/torch_core.py in __torch_function__(self, func, types, args, kwargs)
338 convert=False
339 if _torch_handled(args, self._opt, func): convert,types = type(self),(torch.Tensor,)
--> 340 res = super().__torch_function__(func, types, args=args, kwargs=kwargs)
341 if convert: res = convert(res)
342 if isinstance(res, TensorBase): res.set_meta(self, as_copy=True)
/opt/conda/lib/python3.7/site-packages/torch/_tensor.py in __torch_function__(cls, func, types, args, kwargs)
1021
1022 with _C.DisableTorchFunction():
-> 1023 ret = func(*args, **kwargs)
1024 return _convert(ret, cls)
1025
/opt/conda/lib/python3.7/site-packages/torch/nn/functional.py in batch_norm(input, running_mean, running_var, weight, bias, training, momentum, eps)
2280
2281 return torch.batch_norm(
-> 2282 input, weight, bias, running_mean, running_var, training, momentum, eps, torch.backends.cudnn.enabled
2283 )
2284
RuntimeError: running_mean should contain 582 elements not 1164
11): ResBlock(
(convpath): Sequential(
(0): ConvLayer(
(0): Conv2d(291, 291, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(1): ConvLayer(
(0): Conv2d(291, 291, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(idpath): Sequential()
(act): ReLU(inplace=True)
)
(12): AdaptiveConcatPool2d(
(ap): AdaptiveAvgPool2d(output_size=1)
(mp): AdaptiveMaxPool2d(output_size=1)
)
(13): Flatten(full=False)
(14): BatchNorm1d(1164, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(15): Dropout(p=0.25, inplace=False)
(16): Linear(in_features=1164, out_features=512, bias=False)
(17): ReLU(inplace=True)
(18): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): Dropout(p=0.5, inplace=False)
(20): Linear(in_features=512, out_features=4, bias=False)
i think output of layer prior to adaptive pool is not correct, 291*2 =582 *2=1164
I user resnext 50 here…