Hello all
I am doing lesson 8 and 9 of 2018 , DL2
what does “learn.model.eval()” do in code below ?
x,y = next(iter(md.val_dl))
learn.model.eval()
preds = to_np(learn.model(VV(x)))
Hello all
I am doing lesson 8 and 9 of 2018 , DL2
what does “learn.model.eval()” do in code below ?
x,y = next(iter(md.val_dl))
learn.model.eval()
preds = to_np(learn.model(VV(x)))
we weren’t using “learn.model.eval()” for NLP part of 2018, DL2
for lesson 10 and 11
It tells the model that when it’s called it will be for evaluation/inference, as opposed to training. To go back to training mode, you call model.train(). The difference is that some layers, like BatchNorm and Dropout, have different behaviours during the training and evaluation stage.
For example, Dropout is disabled during evaluation, and BatchNorm only updates the batch statistics during the training stage.
Tanks
completely realized it !
Firstly, I want to thank you for great lectures, followups, fastai v2 and support …
Currently, I’m testing and playing with version 2 on windows almost with no issues. I have couple of feedbacks:
And again thank you very much for your great efforts…
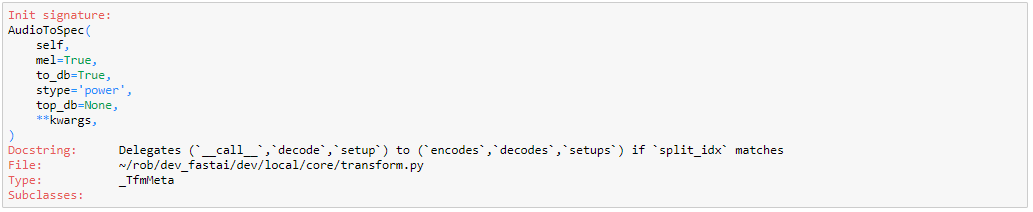
Was there a somewhat recent change to the way @delegates works? I was nesting @delegates with keep=True and this was successfully bringing all the delegated kwargs into my function signature when I tab, but it no longer seems to be doing so. Only the kwargs from _ToDB are getting passed here, but previously all were. Any ideas?
@delegates(_GenSpec.__init__)
@delegates(_GenMelSpec.__init__, keep=True)
@delegates(_ToDB.__init__, keep=True)
class AudioToSpec(Transform):
@sgugger I saw you were adding W&B to the v2. I implemented the original WandbCallback. Are you free some time for a hangout so I can talk about what I tried and how it evolved. I had a few comments that may help you improve your experience and avoid initial hurdles and I’d love to help!
For example in my experience it’s better to log directly the prediction images without passing by pyplot (more robust, I would get random bugs after calling pyplot thousands of times for a run over a night).
Also I guess it would be nice if I could keep the existing callback of v1 consistent with v2. Are you interested in pulling the code directly into fastai v1?
The problem with that is that we can’t get the superimposed images when in segmentation or point tasks.
fastai v2 and v1 won’t be compatible with each other, v2 is a complete rewrite, especially for the callback system. It’s way better and more flexible but comes at the stock of backward compatibility.
Not an intentional one that I recall. Maybe you can check git history/blame and see if something jumps out at you?
Sorry I just meant to check if you wanted to push the callback for v1 directly in fastai v1. I’m just thinking of how to update the documentation of fastai callback on W&B and we could just add a link to fastai documentation.
Here are a few ideas that I had not implemented yet in the callback that you may find interesting:
wandb.init() directly in the callback (can happen only once, similar to wandb.watch) to reduce number of lines needed by people using the callbackafter_batch (cool for learning rate, momentum…) but if you do it also at the start you will get nice reports and summary tables (if you extend the left tableAnd here are few notes on your current implementation:
after_batch before after_epoch. When you use wandb.log, it will increment one step unless you either use commit=false or step=epoch_value. I don’t think the current loop after_batch will work as expected. Even if you added commit=false, then you would overwrite all the values and keep only the last one before incrementing, which happens here (line without commit=false).matplotlib.use('Agg') that we added for non-interactive backends (and tkinter issues)wand_process should be renamed to wandb_process as wandb is an abbreviation for Weights and BiasesHope this will be helpful! Let me know if you’re interested in any idea, I’ll be glad to help.
I was wondering about putting the init in the callback too, there are pros and cons since people might want to have several consecutive runs in the same run on weight&bias.
For logging the hyper-parameters, the problem is that the config approach is too static: learning rate change over training and some other hyper-parameters too, and that’s the general limitation of Weight and bias I don’t like too much: you can’t mix training steps with validation steps well. Ideally I’d like to record my training loss + lr/mom schedules with training iterations, and then the validation loss/metrics/sample preds every validation step but that doesn’t really work. For instance, images don’t display properly in the web interface if you don’t send a sample at each step which means that if you send a training loss + LR at each training step but images only once per epoch, you can’t see them. The alternative, to only send metrics and images at each epoch then try to log a final graph of the LR schedule and training loss doesn’t work either since the graph is sent as an image. So you kind of have to decide between logging training metrics or validation metrics (last version in v2 does that with a bool flag to decide which one to use).
I didn’t know about that, will add.
Oh sorry, that’s a typo. Will fix.
That’s correct, for that we could just pass a **kwargs directly to wandb.init so people have access to all commands such as resume… Their library evolves pretty fast as well so it may be better not to limit to hard coded args. If you want to split between fastai and wandb args you could make them do it as wandb_resume and pass it to wandb.init as resume
I agree though that there are pros & cons and it is probably ok to just have that one line outside of the callback and reference wandb.init doc for custom parameters.
For logging variable hyper-parameters such as learning rate, you have the right approach that is commonly used (which is logging as if it was a metric). I think it can be convenient to log all the initial values in the config (whether they are fixed or not) because then you can have a summary table of all your runs and create reports that are convenient for hyper-parameter tuning.
You can separate logging during training and validation, just make sure to use commit=False during training though only the last value will actually be logged (so may be better to do at the end of training vs end of each batch).
A cleaner approach may be to accumulate all the data you want to log in a dict and log it all in once at the end of the epoch.
Do you need to log more than one training loss + LR per epoch or would the average be satisfactory? This would be the easiest way to log everything.
Also if you want to log a graph independent from the epoch there is an option that some people use (I’ve not played with it yet) to log summary graphs (I’ve not played with it myself yet).
Here is an example (see summary table) from Lavanya which I think is what you are looking for.
For that, I believe you log the image through wandb.config.update instead of wandb.log and it will overwrite it at each step.
I remember trying to log different data at different steps (passing the step arg) but I had no success. If it is really needed I can reach W&B and see how to do it. I wanted it to limit the number of prediction samples I log as I had quick epochs. If you want I can investigate it further if you think there will be an application here.
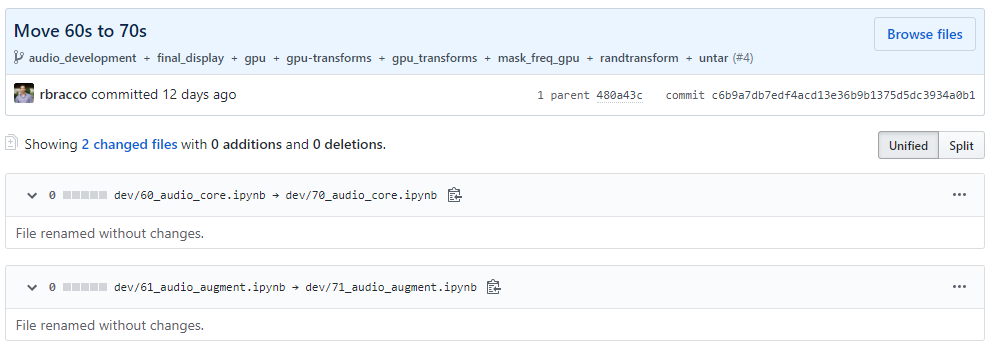
Thanks, it turns out the bug started earlier than I thought. Assuming I’m doing this properly I traced it to commit c6b9a7db… on Oct 21st, this is the first broken version, shift-tab on AudioToSpec looks like this
On the previous commit, 480a43c6… it was working properly and shift-tab yields
The breaking commit appears to not have made any code changes but just renamed the nbs to move them from 60s->70s after the medical imaging started using the 60s.
I have no idea how this could be having an impact. Is there something I could be missing? Please let me know if there’s any additional work I can do or info to provide to help track this down. Thank you!
The average definitely isn’t satisfactory, I’m afraid…
Ok, the easy and fast way would be to log custom pyplot graphs at the end of each epoch.
However to benefit the most from the interface (for example show training and validation loss on same graph and zoom in, or define custom graphs on user workspace), the best would be to log the actual values.
Right now I can see 2 approaches. Let’s say we have 20 training batch/step per epoch and 5 validation batch/step per epoch:
Did I understand correctly what we want to do?
For anyone else who struggled to understand the DataBlock API, like I did, I have written an article about the DataBlock API giving an overview of the same by using the Pets lesson as a starting point.
This is only a top level overview to start with and there are many more articles to come 
Note that in option A, any image you log at step 5, 10, 15 doesn’t show on the UI web interface. If there’s not one image per set, it breaks. I had this working for just scalar values but reverted because of the predictions being broken.
To be completely clear, are we trying to achieve something similar to below picture:
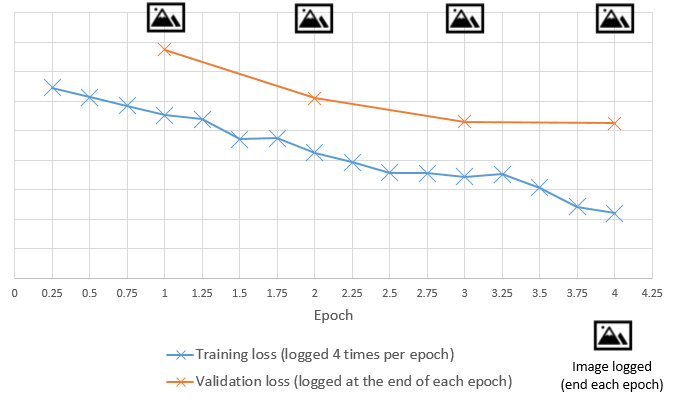
Feel free to edit the picture: run_log.xlsx
@sgugger yes I had the same issue in the past. Let me check if there’s an easy fix.
I just had a quick question please.
if dsrc is DataSource, shouldn’t dsrc.train always equal dsrc.subset(0).
path = untar_data(URLs.PETS); path
path_anno = path/'annotations'
path_img = path/'images'
np.random.seed(2)
pat = r'/([^/]+)_\d+.jpg$'
items = get_image_files(path/'images')
tfms = L([PILBase.create], [RegexLabeller(pat), Categorize])
splits = RandomSplitter(0.2)(items)
dsrc = DataSource(items, tfms=tfms, splits=splits)
dsrc.train == dsrc.subset(0)
>> False
Why would the two not be equal please?
I think it’s just python being weird in the sense that DataSource.train is an attribute of DataSource, while DataSource.subset(0) is the result of a method. If you do the same thing with the underlying items/tfms, you’ll have True.