Yes @MadeUpMasters that would be very helpful - we actually have a TODO in the code for just this! 
1 Like
Hey guys,
quick question what is the correct way in new fastai to add model to multi gpu ?
when I use
learn.model = nn.DataParallel(learn.model)
I get following error

I don’t know if this helps, but the code for distributed GPUs in fastai v1 is over here.
For distributed training, you can wrap the model with DistributedDataParallel and you have to change the sampler of the DataLoader to a DistributedSampler.
So I tried to PR test_warns but I’m not sure how to do it cleanly as my fork is full of audio stuff.
My best guess was to create a new branch, force pull the latest version of fastai_dev master, remove my audio notebooks, commit, make the new test_warns function and a few tests that test it, commit (I’m at this point now). Do I just PR that then? Is there a better way? Thanks.
Edit: Nevermind, @baz helped me through it. I was making the mistake of merging my audio feature branches into master, instead of a secondary audio branch. Deleted master and got a clean version and setup my audio work to be based off a new audio_development branch. In case anyone else is facing a similar issue, my workflow is
- branch off of audio_development for new features, merge them to audio_development when they are complete. Never merge to master.
- if I need to PR to core, update master, branch off, implement feature and PR from there.
Edit 2: PR submitted! Let me know if there are any issues with it. I’m actually forked off a fork, so hopefully that doesnt cause problems.
My PR failed checks, but the error message isn’t clear. Any idea where I went wrong?
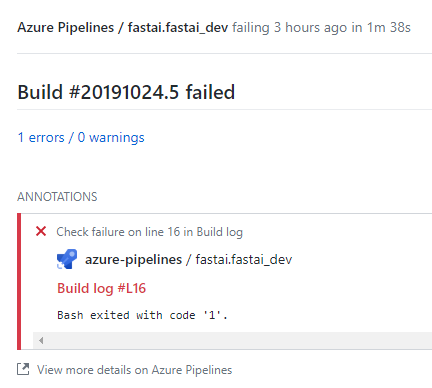
It’s just that you hadn’t run the export cell at the bottom of the nb, so the notebooks and scripts didn’t match up. It’s not a big deal - I’ve pulled it and will run the cell and push back.
@tank13 and anyone else having issues with Google Colab and the Image import issue, you need the newest installation of PIL to get it working.
!pip install Pillow --upgrade
3 Likes
It works, thank you very much!
Hi,
As far as this weekend I can tell, suggestion=True is not in the plot anymore…
And there is no plot function, in v2 you need to call learn.recorder.plot_lr_find() or something similar.
In addition, the callbacks are changed, SaveModelCallback and EarlyStoppingCallback has few minor changes, now you don’t have to put learn object inside, be aware of some other parameters changed. I highly suggest peaking the source code before calling them.
I’ve been able to get it to plot with just learn.lr_find(). That is intentional
It is by default, unless you set show_plot=False in lr_find, then you have to call learn.recorder.plot_lr_find to show the graph I believe
I was trying to find suggestion option in v1 which tells you the optimal lr
1 Like
Ah yes, seems that is not in there yet. You are right
Has anyone else experienced instead of fit printing out the pretty style we’re used to it just shows the L? Eg:
(#5) [0,0.3795085847377777,0.3632674515247345,0.8341862559318542,00:40]
(#5) [1,0.40276384353637695,0.3697092533111572,0.8348686695098877,00:40]
This is happening on Colab, unsure what to do about this.
When can we expect support for distributed training? I was hoping to experiment with @jeremy’s RSNA kernels with multiple GPUs in GCP however it seems like distributed training is not yet implemented.
I assume the answer is not soon?
Don’t do that please.
I was just trying to say I assume distributed training right now is not something that will be developed soon (within the next couple weeks) by your team for fastai v2 as you are having other things to focus on for fastai v2. Therefore, I will work on projects accordingly. I didn’t mean to offend anyone.
The main issue is that you asked your question twice. Within a 24 hour period. If your question isn’t answered, please don’t ask it again. Especially so soon. And there’s no point making assumptions about our priorities, because if we have priorities to share we’ll share them, and if we don’t and haven’t then there’s no point making up guesses.
As it happens, distributed was next on our list, and Sylvain finished it today (although it’s not well tested yet).
2 Likes
I noticed that at the transformer and transformer-XL archs are commented out at https://github.com/fastai/fastai_dev/blob/master/dev/local/text/models/core.py#L13.
Is this because the code for the transformers hasn’t been ported yet? Would you like someone to pick up the work, or is someone already working on it (as far as you know)?
EDIT: I also noticed there’s no way to use pretrained word embeddings. Should that be a concern?
Sorry about that. I thought it had been more than 24 hours.
Thanks for letting us know that distributed training is almost ready and thanks @sgugger for porting over the code. Please let us know when it’s ready for use!
1 Like