One feature I would recommend is split_by_pct() currently there is only random_split_by_pct() which is more practical but sometimes you just want to just use the last 20% as opposed to random and this way you don’t have to manually find the index in the list that will make the split work. you just say the percentage and the method figures out how to split it 80/20.
Another request will be not to deprecate from single_folder. Sometimes your train and validation folder can be very differently organized or from different distributions. I would like to be able to create a data_bunch and say this is the validation dataset so that it only uses validation transforms. Then we can merge it with a separate training data_bunch or something along this lines.
In my experiments I’m using the SaveModelCallback as my default mechanism for saving models. However, it is often difficult for me to manually track metadata of the resulting models such as hyper parameters, metrics and the used fastai version. The CSV Logger records the training history, but I can’t tell at first which epoch my model was saved in and which metrics apply for the saved model. For this reason I implemented a SaveMetadataCallback, which I use as a supplement to the SaveModelCallback: https://gist.github.com/juriwiens/bcc078fe0df956eec27bffe4cc06e519
It’s a first simple version that saves some basic metadata like metrics and library/python versions. The metadata can easily be extended by specifying a base_metadata dict.
I feel like if your data is ordered it’s probably in a csv or df. So both ways it will allow to use from_df() and create a df object. The solution would be simple as:
I believe the reason of not having a split_by_pct is basically it being a repetition of already existing methods which will allow you to do the desired thing.
The good part about integrating SentencePiece is that it can be used as a transformation to augment text data and also to do TTA (Test-Time Augmentation). However, when I tried that, I couldn’t get good GPU utilization anymore and for now I’m using it just as a pre-processor. It’s something that’s definitely worth integrating to the base library though.
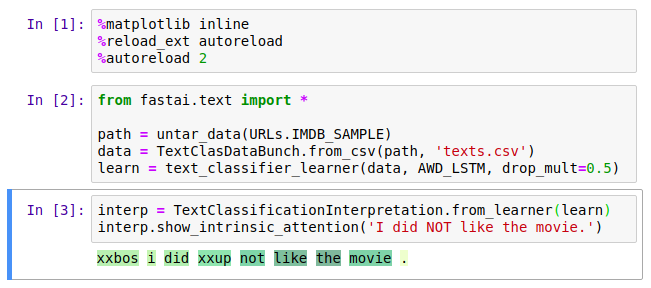
I’m submitting a pull request with a patch that lets users of AWD-LSTM to use pre-computed embeddings as an alternative input (other than tensors with token IDs).This is useful is a few cases, such as computing the sequential Jacobian to inspect the intrinsic attention (sensitivity) over elements of the input sequence. The pull request also includes this new TextClassificationInterpretation class, which is still a bit limited but can already be useful to someone else.
Example (even though the colors are not very indicative in this example because it’s using an untrained model):
Regarding visualization, currently colormaps and the separator are configurable (the default is a RdYlGn cmap and one can make the separator the empty string if using char-level models).
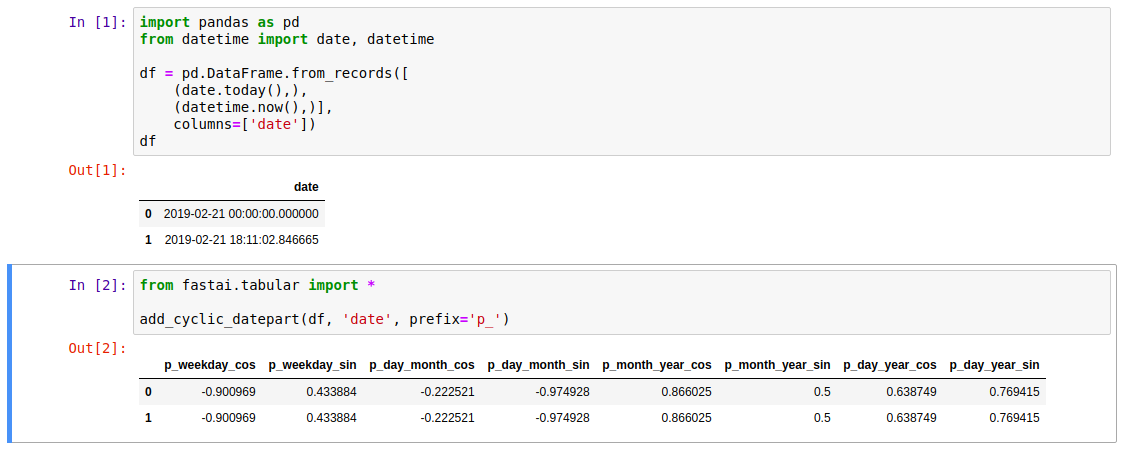
The fastai.tabular package already provides a way to generate date/time features (the add_datepart function), but another useful representation is mapping components to the circle, by taking the sine and cosine parts of modular components of date/time cycles (days of the week, month of the year, etc.). This is know by many names like trigonometric time, cyclic time features, and so on.
I’m submitting the add_cyclic_datepart function, with a similar form of use:
In think there is a bug in add_cyclic_datepart functionality. When add_cyclic_datepart is used on DataFrame with indexing scheme other than standard values 0,1,2,…n it produces data frame with additional empty row(s). Below is a code to reproduce bug:
Result of running this code is that data frame df_mod contains 4 additional rows with NaN values (9 rows in total vs 5 rows in original data frame df).
Over the past few days, I stumbled a dozen times across issues of being unable to reproduce fast.ai code examples, in some cases even from the official API documentation and in virtually all cases it came down to a version mismatches between the used API and the referenced documentation. I understand that the fast.ai API evolves really fast and the official documentation on the website may lag a bit, and that’s okay.
However, as a workaround of the fast changes, please add an API version number to the web API documentation.
Also, it would be marvelous to tag obsolete methods with the @deprecated decorator for some time with a reference what to use instead before removing them. Over the past few days, I had to fix so many “no method” glitches exactly because the underlying method has been removed or moved in a release after the code example was written and a tiny deprecated annotation with a hint what to use instead would have been saved some time and hazzles.
That being said, the fast.ai 1.0+ API is pretty amazing so thanks for all the good work.
The docs are always up to date with the latest release (we try to keep it up to date with master but there might be a delay). It’s tricky to have frozen versions of docs but we can add a version flag to say what it’s supposed to run with.
As for the deprecation warnings, we are trying to get better with that. The last breaking changes (create_cnn -> cnn_learner and co) were all elft with the old function deprecated. i didn’t know there was a decorator that did that automatically, will check that!
Is there a plan to add CoordConv networks to fast.ai?
According to the authors:
“CoordConv models have 10-100 times fewer parameters, train in seconds rather than over an hour (150 times faster) as needed for the best-performing standard CNNs.”
Or maybe even implementing a moving average for the derivative of loss with respect to learning rate, and use the argmin of that (I read this on a Medium post).
Hi Ricardo,
I haven’t used this yet, but I am really excited about it, especially for my area of interest - NLP in medicine. Google has a great example of the impact of this “interpretation” on page 6 of this article: https://arxiv.org/ftp/arxiv/papers/1801/1801.07860.pdf
This example showed why the network thought that the patient was likely to die, and the highlighted phrases were right on target (cancer, malignant pleural effusion, etc).
I have long felt that the barriers to success of DL in medicine will be
Not enough labels - ULMFiT solves that
Providers don’t trust black-box prediction - you are making interpretation easy for all of us!
Often, in a classification problem, papers will provide a table showing metrics by class, it’s useful to compare results to industry benchmarks and can also help gain insights on which class is underperforming.
Is there a way to do this already? If not I’m willing to contribute a PR
Similarly, for multi-label problems, it would be great to be able to compute the traditional metrics directly (Precision, recall, FBeta, etc.), most metrics in the library currently do not work for multi-label scenarios.
Eventually I would like to combine these 2 features (multi-label, per class metrics).
Hi, can I submit a PR for returning results from functions show_results instead of just displaying them?
The reason is that I want to do a callback for logging losses, metrics & results at each epoch.
Option 1 (raw data):
return (xs, ys, zs), whether it is text or images
Option 2 (formatted data):
text: return pd.DataFrame
images: return plt
I’m a bit more in favor of option 2 as we benefit from the formatting done by the show_results functions.