This topic is to suggest any new feature that should be added to the library. Development is limited to debug for now, as we are focused on the documentation, but ideas are definitely welcome!
Here are a few things we didn’t get a chance to implement yet:
save/load the optimizer state on top of the model
data augmentation when the target is a list of points
I think almost everything can be handled via the wonderful callback api. I am not sure if this has any easy solution with callbacks, but how do we train two models simultaneously like in gans?
A not so elegant solution I have found is to have one model with both the discriminator and generator and have some property to decide which one to execute and use callbacks to change that property. Would love to know if there is something simpler.
I hope to add GAN support to fastai by the time we get to the mid-point of the course, including CycleGAN. Ideally we’ll add it as a loss function, although I haven’t fully thought it through yet.
I think we should also have a dataclass which supports something like pascal multi (I couldn’t find such a notebook in dev_nb). To be precise, it should take a csv file with image_id bbox cls for each bounding box (multiple bbox goes to different rows).
In the previous version, it was done via ConcatLibDataset, however that requires pre-processing of csv files, and I believe the image_id bbox cls is a standard format and it would be nice to support that.
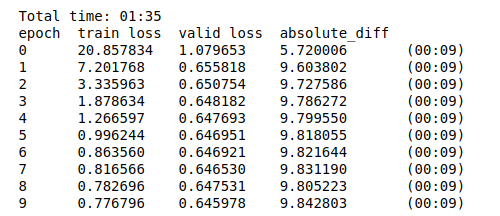
Not exactly related to fastai, but fastprogress. Not a very crucial thing but currently the output looks like this:
Would be great if the values are in a more tabular format, like having only the value of training loss below training loss. It is slightly tough on the eye to decipher the values.
I’ve tried my best, but the widget is in HTML, so the spaces are all messed up. Since it’s only during training and the final output is clean, we decided it wasn’t worth spending more time on for now.
This post https://medium.com/@keeper6928/how-to-unit-test-machine-learning-code-57cf6fd81765 has some outlines to unit test deep learning modules. While many of the problems that have been stated would be easy to find if one uses a good IDE, there are still quite a few bugs which go un-noticed. A few examples could be vanishing/exploding gradients, models not being initialized properly, loss becoming negative etc.
Thank you for the wonderful courses, Jeremy, Rachel, and Sylvain!
I am very interested in applying what I have learned from the fast.ai courses to medical imaging. In such applications, I often face inputs with an arbitrary number of channels, for example, 1-channel gray images, N-channel 3D data set, M-channel multi-parametric maps, K-channel multi-contrast images, L-channel complex-part and real-part of data acquired from multiple receivers, and etc. (where N, M, K, L, … are any arbitrary integer such as 1, 2, 3, 4, 5, … and up to 128 or even 256).
I was wondering if the fast.ai library could be supporting data with an arbitrary number of channels input data?
To implement TTA to segmentation, you need to keep the transformation params and a way of applying the inverse of the transformation. There may be transformations that are not inversible.
So that would entail adding in a separate set of only inversible transforms for the test dl instead of utilizing the validation ones, modifying the test dl to capture the transform parameters, and then the tta function to do the inversion on the prediction?
Here was another thread on the topic:
And also, not all of them would need to be inversed, only those that change pixel locations. Crops probably wouldn’t work.
Maybe there is an easier way, but that was what I thought was needed when I had this problem. If you want, we could work together on trying to solve this.