Hi,
I am having trouble understanding the interface between Multihead attention and the Feed Forward layer in Transformers. I am using this picture from Jay Alammar’s wonderful blog on The illustrated Transformer
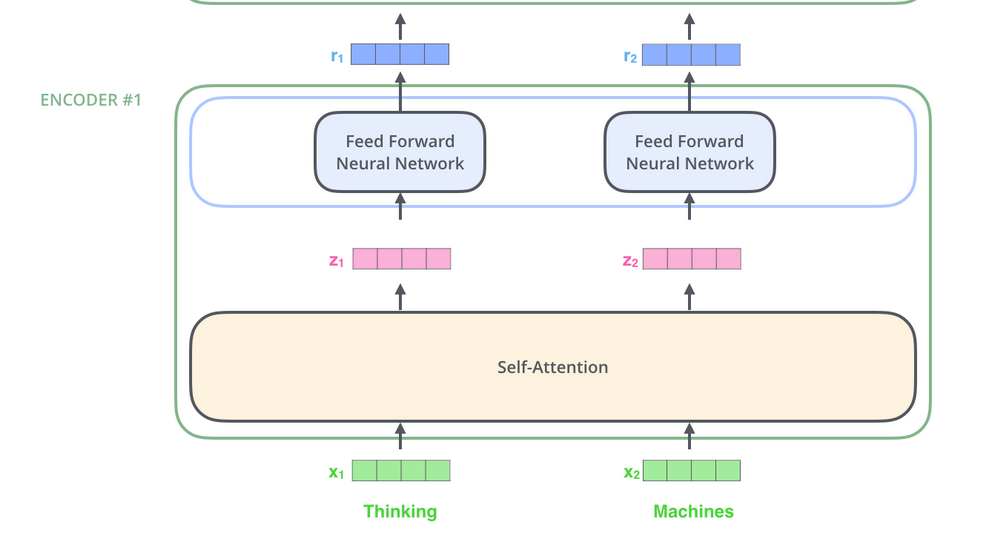
The output of the attention layer would a tensor (bs,x_len,d_model). The input dimension of the feed_forward layer is d_model . So we would need x_len of these feed_forwards in parallel with weight sharing.
However, in the fastai implementation, we only have a single feed_forward after the attention layer in . How is that possible? It is as if fastai is broadcasting the ff layer to match (d_model), with (x_len,d_model). I must be missing something.
Any clarification would be greatly appreciated.
Regards
Satish