Hello everyone
I am trying to build an image captioning model using fastai library.
It has two blocks - CNN and RNN. I have already created these blocks, but now I am stuck in creating learner for them, because fastai has two different learners for ConvNets and RNNs.
Do you have any ideas or suggestions on how to combine them?
3 Likes
I’d try to split your network up into base (image) and head (text) as a starting point. The learner part is pretty simple as they both derive from the base learner class. The only critical part  is the crit, and that’s the same as RNNLearner, assuming you’re going to measure the error in the output sentence. The other functions from the CNN side are possibly helpful, but not necessary. The ismulti option in the CNNLearner sets the crit to BCE so that’s probably your best starting point.
is the crit, and that’s the same as RNNLearner, assuming you’re going to measure the error in the output sentence. The other functions from the CNN side are possibly helpful, but not necessary. The ismulti option in the CNNLearner sets the crit to BCE so that’s probably your best starting point.
1 Like
Thx for the answer!
Another difficult part for me is data loader.
I do not quite understand how to create a batch from pictures and text so that Learner will correctly handle the fit function.
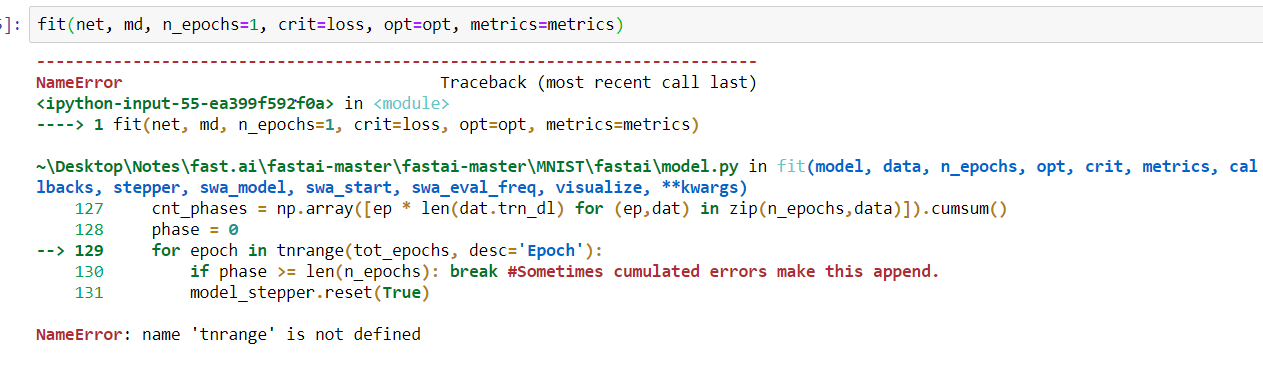
And it is also really difficult for me to understand how the fit function works with dataloaders under the hood, I can’t figure out what is phase in fit function:
phase = 0
for epoch in tnrange(tot_epochs, desc='Epoch'):
model_stepper.reset(True)
cur_data = data[phase]
So the main question for now is - how to create a dataloader for images and texts catpions? Dataloaders for images and text are so different.
What is the main abstraction for dataloader? What methods and attributes should it have to correctly work with Learner?
As you can see, there is a complete mess in my head right now, and I would be very happy if someone helped me to sort this out
We do most of these things in part 2 of the course - might be worth looking for answers there, then posting in that forum if you get stuck?
2 Likes
I’ve been where you are not too long ago, and it was a project similar to yours that provided me the grounding in fast.ai. As @jeremy says, part 2 contains a lot of these answers and a lot more examples to reference from if you’re confused.
Learning the basic functions of the library has really helped my dl development, and I recommend you keep on this project.
One thing that often helps me is to start framing the question on the forum, and then to spend 5 minutes really looking into whether I can answer the question on my own. To be effective the question has to be pretty specific, so it might be ‘what are the inputs to dataloader’ or ‘are there any examples of dataloader that use an image and something else or text and something else that I can look at’.
By framing the question I often find it gives me a clearer sense of where to look in the library or what to do as a next step, and by iterating I often find I can answer my own questions.
Dive into part II, and I think you’ll find the answers you’re looking for though.
1 Like
I have already watched Part 2 for two times, and it is great, btw.
I spent about two days trying to create some fastai-based pipeline that can use all Learner benefits (like clr and lr_find) and uses resnet backbone and pretrained LM. I was thinking that it will be pretty easy after the Part 2, but then I started to stuck. The most difficult part was the structure of fastai, and I found this project really helpful.
For now I think I understand what I should do next - custom Dataset, ModelData, DataLoader and Learner.
I went through those same pains, but believe me it’s worth it at the end of the day. The benefits to using fast.ai are huge and now that I’ve built something end to end with custom learner, loss function, model, data loader, etc I understand so much more about what’s going on.
1 Like
Ok, I finally have something concrete to ask.
Here is code for my caption model:
class FeaturesEncoder(nn.Module):
def __init__(self, cnn_encoder, language_model, max_len, stoi, itos):
super().__init__()
self.stoi, self.itos = stoi, itos
self.max_len = max_len
self.cnn = cnn_encoder
self.lm = language_model
def forward(self, inp):
bs = inp.size()[0]
features = self.cnn(inp)
self.lm[0].init_hidden(features) # [0] is for Encoder part. [1] is Linear decoder
bos_idx = self.stoi['xbos']
lm_inp = V(torch.ones(bs).long() * bos_idx).view(1, -1)
res = []
for i in range(self.max_len):
out = self.lm(lm_inp)[0]
res.append(out)
lm_inp = V(out.data.max(1)[1]).view(1, -1)
return torch.stack(res)
cnn_encoder is resnet18 backbone with 3 Linear outputs for each hidden state of language_model, which is pretrained language model.
Here is complete architechture of my model
FeaturesEncoder(
(cnn): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
(2): ReLU(inplace)
(3): MaxPool2d(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), dilation=(1, 1), ceil_mode=False)
(4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
)
)
(5): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True)
)
)
(6): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True)
)
)
(7): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
)
)
(8): FeaturesToHidden(
(drop): Dropout(p=0.25)
(ampool): AdaptiveMaxPool2d(output_size=(7, 7))
(layers): ModuleList(
(0): Linear(in_features=25088, out_features=1150, bias=True)
(1): Linear(in_features=25088, out_features=1150, bias=True)
(2): Linear(in_features=25088, out_features=400, bias=True)
)
)
)
(lm): SequentialRNN(
(0): RNN_EncoderFI(
(encoder): Embedding(37626, 400, padding_idx=1)
(encoder_with_dropout): EmbeddingDropout(
(embed): Embedding(37626, 400, padding_idx=1)
)
(rnns): ModuleList(
(0): WeightDrop(
(module): LSTM(400, 1150)
)
(1): WeightDrop(
(module): LSTM(1150, 1150)
)
(2): WeightDrop(
(module): LSTM(1150, 400)
)
)
(dropouti): LockedDropout(
)
(dropouths): ModuleList(
(0): LockedDropout(
)
(1): LockedDropout(
)
(2): LockedDropout(
)
)
)
(1): LinearDecoder(
(decoder): Linear(in_features=400, out_features=37626, bias=False)
(dropout): LockedDropout(
)
)
)
)
I set all weights of cnn_encoder except the FeaturesToHidden layer trainable feature to false.
The problem is that I got an OOM error even with the batch_size=1 and input images of size (3, 320, 320) on 1080Ti
How to check, where I have memory problems here?
Ok. Memory problems are in for loop. For each iteration it takes about 250 mb of GPU RAM. I had max_len = 32. At 16 it works fine.
I think there is some memory leak, because during LM finetuning process bptt is equal to 70 and it takes only 7 GB of RAM.
Does anybody have an idea what is going on there?
Have a look in the fastai RNNs at how we detach the hidden state from time to time, and also how we don’t include all the time steps in our classifier. These were the things I had to do to avoid running out of memory. The main thing to think about is: what variables do you have, and how much history are you having them remember? Because that’s what they need to backprop thru.
1 Like
I’ve moved this to the part 2 forum FYI.
First of all, congrats! Getting to this stage is no small achievement!
In terms of the memory component, I think Jeremy has pointed you in the right direction.
Hi ,I have also started working on Image Captioning.This is how i have thought of implementing it:
1)Encode the image using a pretrained CNN
2)Pass the Encoded Image along with the last generated word to generate the new word
The problem that i am encountering is stacking of those encoded image along with the previous predicted word using nn.rnn or nn.LSTM.I watched the lesson 6 of the course v2 and am able to do it using loops.At output of each loop i am concatenating the current output with the encoded image vector.But am not really sure how to do it using nn.RNN
@jeremy Could you please point me in the right direction
I tried modifying the translate notebook’s Seq2Seq architecture to work on Image Captioning
here the input is the encoded image which is a tensor of embedding size=300 and is the very initial hidden state for the model
class Im_cap(nn.Module):
def __init__(self,em_sz,vocab_sz,max_len):
super(Im_cap,self).__init__()
self.em=nn.Embedding(vocab_sz,em_sz)
self.lstm=nn.GRU(input_size=em_sz,hidden_size=nh,num_layers=2,batch_first=True,dropout=0.3
,bidirectional=False)
self.out=nn.Linear(nh,vocab_sz)
self.max_len=max_len
def forward(self,h):
bs=h.shape[0]
print(h.shape)
dec_inp = V(torch.zeros(bs).long())
print(dec_inp.shape)
res = []
for i in range(self.max_len):
emb = self.em(dec_inp).unsqueeze(0)
outp, h = self.lstm(emb, h)
outp = self.out(self.out_drop(outp[0]))
res.append(outp)
dec_inp = V(outp.data.max(1)[1])
if (dec_inp==1).all(): break
return torch.stack(res)
But i am receiving the following error
torch.Size([2, 300])
torch.Size([2])
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-323-c3e1f0736258> in <module>
----> 1 model(test)
c:\users\dark_nuke\anaconda3\envs\py35\lib\site-packages\torch\nn\modules\module.py in __call__(self,
*input, **kwargs)
475 result = self._slow_forward(*input, **kwargs)
476 else:
--> 477 result = self.forward(*input, **kwargs)
478 for hook in self._forward_hooks.values():
479 hook_result = hook(self, input, result)
<ipython-input-314-8ed4be418a64> in forward(self, h)
17 for i in range(self.max_len):
18 emb = self.em(dec_inp).unsqueeze(0)
---> 19 outp, h = self.lstm(emb, h)
20 outp = self.out(self.out_drop(outp[0]))
21 res.append(outp)
c:\users\dark_nuke\anaconda3\envs\py35\lib\site-packages\torch\nn\modules\module.py in __call__(self,
*input, **kwargs)
475 result = self._slow_forward(*input, **kwargs)
476 else:
--> 477 result = self.forward(*input, **kwargs)
478 for hook in self._forward_hooks.values():
479 hook_result = hook(self, input, result)
c:\users\dark_nuke\anaconda3\envs\py35\lib\site-packages\torch\nn\modules\rnn.py in forward(self, input,
hx)
176 flat_weight = None
177
--> 178 self.check_forward_args(input, hx, batch_sizes)
179 func = self._backend.RNN(
180 self.mode,
c:\users\dark_nuke\anaconda3\envs\py35\lib\site-packages\torch\nn\modules\rnn.py in
check_forward_args(self, input, hidden, batch_sizes)
149 'Expected hidden[1] size {}, got {}')
150 else:
--> 151 check_hidden_size(hidden, expected_hidden_size)
152
153 def forward(self, input, hx=None):
c:\users\dark_nuke\anaconda3\envs\py35\lib\site-packages\torch\nn\modules\rnn.py in
check_hidden_size(hx, expected_hidden_size, msg)
141 def check_hidden_size(hx, expected_hidden_size, msg='Expected hidden size {}, got {}'):
142 if tuple(hx.size()) != expected_hidden_size:
--> 143 raise RuntimeError(msg.format(expected_hidden_size, tuple(hx.size())))
144
145 if self.mode == 'LSTM':
RuntimeError: Expected hidden size (2, 1, 256), got (2, 300)