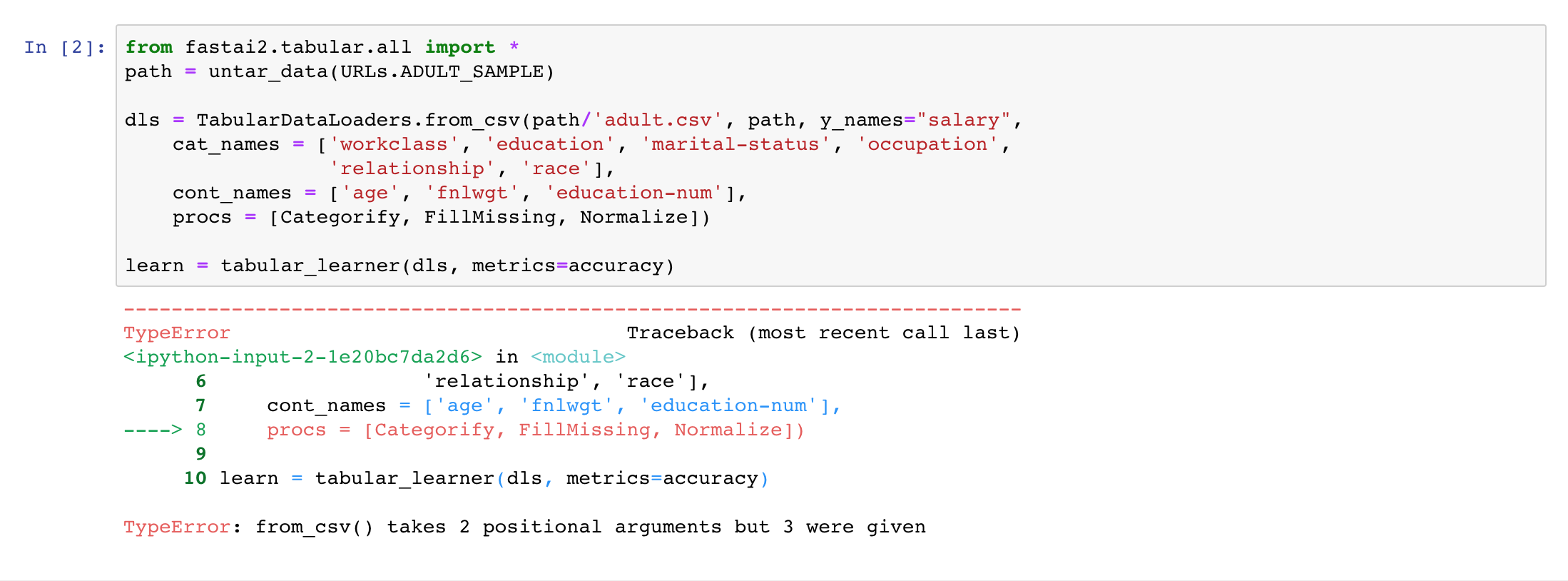
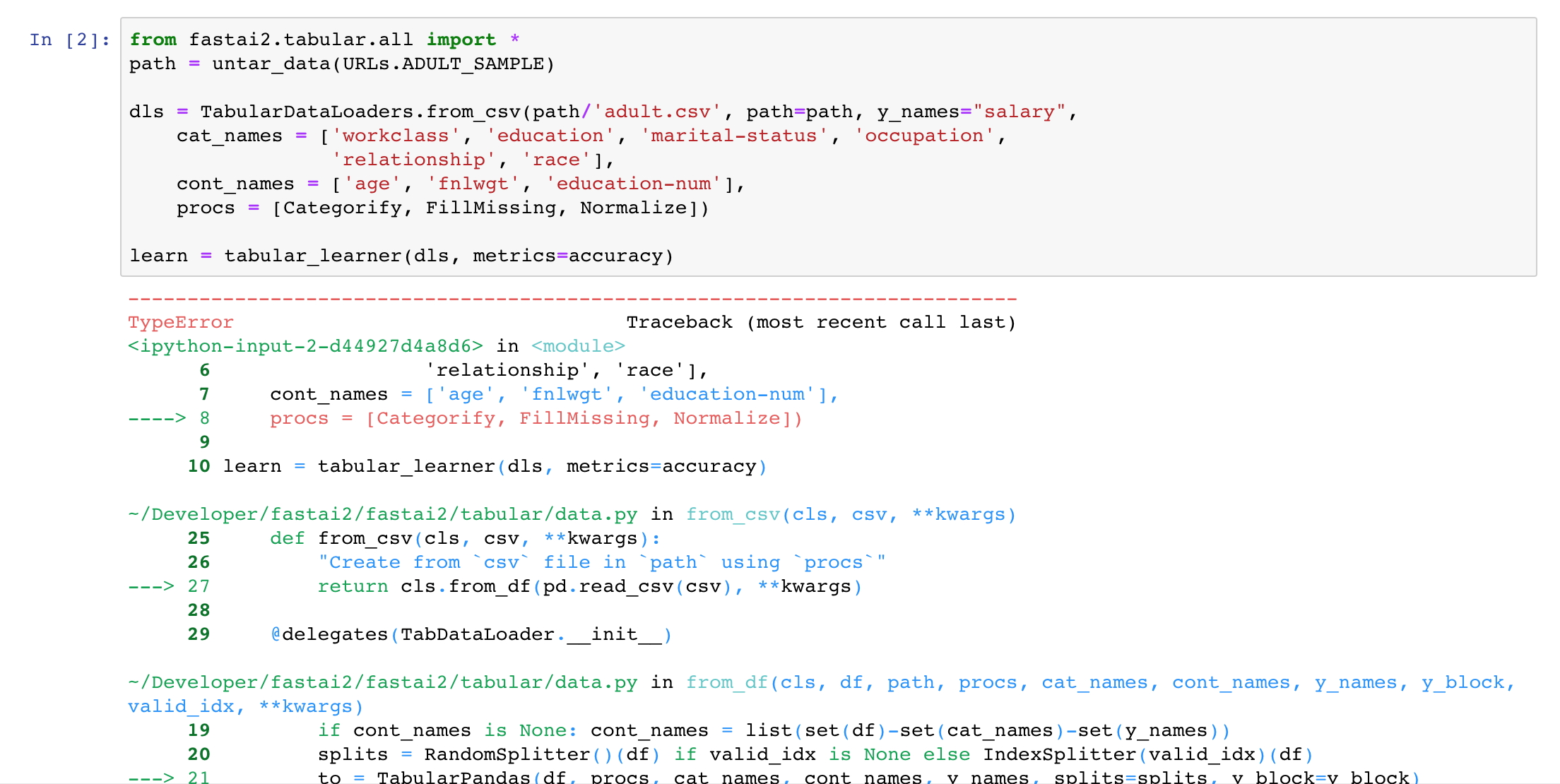
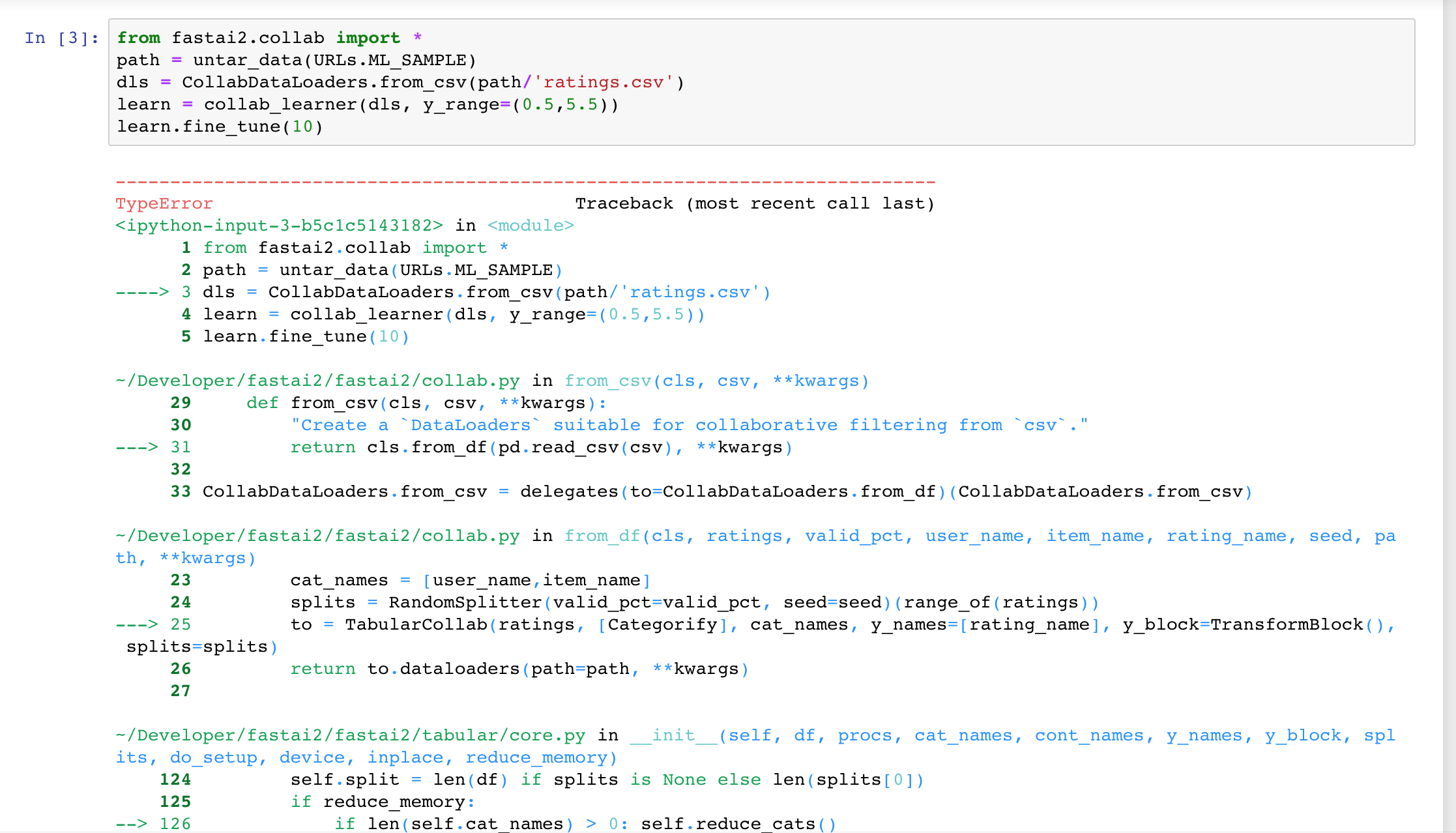
TypeError Traceback (most recent call last)
in
1 from fastai2.collab import *
2 path = untar_data(URLs.ML_SAMPLE)
----> 3 dls = CollabDataLoaders.from_csv(path/‘ratings.csv’)
4 learn = collab_learner(dls, y_range=(0.5,5.5))
5 learn.fine_tune(10)
~/Developer/fastai2/fastai2/collab.py in from_csv(cls, csv, **kwargs)
29 def from_csv(cls, csv, **kwargs):
30 “Create a DataLoaders suitable for collaborative filtering from csv.”
—> 31 return cls.from_df(pd.read_csv(csv), **kwargs)
32
33 CollabDataLoaders.from_csv = delegates(to=CollabDataLoaders.from_df)(CollabDataLoaders.from_csv)
~/Developer/fastai2/fastai2/collab.py in from_df(cls, ratings, valid_pct, user_name, item_name, rating_name, seed, path, **kwargs)
23 cat_names = [user_name,item_name]
24 splits = RandomSplitter(valid_pct=valid_pct, seed=seed)(range_of(ratings))
—> 25 to = TabularCollab(ratings, [Categorify], cat_names, y_names=[rating_name], y_block=TransformBlock(), splits=splits)
26 return to.dataloaders(path=path, **kwargs)
27
~/Developer/fastai2/fastai2/tabular/core.py in init(self, df, procs, cat_names, cont_names, y_names, y_block, splits, do_setup, device, inplace, reduce_memory)
124 self.split = len(df) if splits is None else len(splits[0])
125 if reduce_memory:
–> 126 if len(self.cat_names) > 0: self.reduce_cats()
127 if len(self.cont_names) > 0: self.reduce_conts()
128 if do_setup: self.setup()
~/Developer/fastai2/fastai2/tabular/core.py in reduce_cats(self)
136 def decode(self): return self.procs.decode(self)
137 def decode_row(self, row): return self.new(pd.DataFrame(row).T).decode().items.iloc[0]
–> 138 def reduce_cats(self): self.train[self.cat_names] = self.train[self.cat_names].astype(‘category’)
139 def reduce_conts(self): self[self.cont_names] = self[self.cont_names].astype(np.float32)
140 def show(self, max_n=10, **kwargs): display_df(self.new(self.all_cols[:max_n]).decode().items)
~/anaconda3/lib/python3.7/site-packages/fastcore/foundation.py in getitem(self, k)
276 def init(self, items): self.items = items
277 def len(self): return len(self.items)
–> 278 def getitem(self, k): return self.items[k]
279 def setitem(self, k, v): self.items[list(k) if isinstance(k,CollBase) else k] = v
280 def delitem(self, i): del(self.items[i])
~/anaconda3/lib/python3.7/site-packages/pandas/core/frame.py in getitem(self, key)
2686 return self._getitem_multilevel(key)
2687 else:
-> 2688 return self._getitem_column(key)
2689
2690 def _getitem_column(self, key):
~/anaconda3/lib/python3.7/site-packages/pandas/core/frame.py in _getitem_column(self, key)
2693 # get column
2694 if self.columns.is_unique:
-> 2695 return self._get_item_cache(key)
2696
2697 # duplicate columns & possible reduce dimensionality
~/anaconda3/lib/python3.7/site-packages/pandas/core/generic.py in _get_item_cache(self, item)
2485 “”“Return the cached item, item represents a label indexer.”""
2486 cache = self._item_cache
-> 2487 res = cache.get(item)
2488 if res is None:
2489 values = self._data.get(item)
TypeError: unhashable type: ‘L’