I have a question about notebook fast.ai v3 lesson 1. I wanted to see what normalize() does to images so I displayed the images after normalize call and without normalize call. I was expecting to see the same picture repeated with some image processing done to first batch. Instead I was given two different image sets. Is normalize() suppose to change the order of the data or is there something else I’m doing wrong?
Thank you.
I have added code and results below:
data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=224, bs=bs, num_workers=0).normalize(imagenet_stats)
data2 = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=224, bs=bs, num_workers=0);
data.show_batch(rows=3, figsize=(7,6))
data2.show_batch(rows=3, figsize=(7,6))
Did you set the seed? ex. np.random.seed(2)?
ImageDataBunch makes training set and validation set. Validation set is set to 0.2 by default.
Training set and validation set are chosen randomly.
So, if you did not set the seed, it is reasonable that your data and data2 generated different training set batches.
I checked random seed is set.
I run :
np.random.seed(2)
pat = re.compile(r’/([^/]+)_\d+.jpg$’)
just before the code.
What else could it be. Could it be a bug/ not suppose to happen?
Thank you!
data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=224, bs=bs, num_workers=0); data2=data.normalize(imagenet_stats);
I am not sure what you mean by “sharing the same counter”.
But, I think you need to do:
import numpy.random
seed(3)
or try
import random
random.seed(3)
I ran the lesson 1 script. I do not know if fastai library implicitly calls numpy library, but np.random.seed() is not working properly without calling the library explicitly.
Now, the two DataBunch with and without normalization should show you similar output from show_batch(). They might be little different because of normalization, which is just taking each data, subtract the average of the entire data, and divide that by the standard deviation.
I tried both
import random
and
import numpy.random
Same behaviour. It still shows me different animals for data.show_batch() and data2.show_batch().
I must say that I run in inside kaggle notebook. Maybe their code is not up to date or maybe there is something wrong with their enviroment?
This is notebook i based my own on: https://www.kaggle.com/hortonhearsafoo/fast-ai-v3-lesson-1
I couldn’t figure out why show_batch() shows different pictures every time, but try these:
data.train_ds.x[0]
data2.train_ds.x[0]
These grab a specific element in the training dataset. You should see the same picture for both, confirming that the dataset order does not change after normalizing.
What happens there is basically an invocation of one_batch(), which is in the same file. This appears to be an iterator and returns the next batch of data, so never the same. I assume that the entire dataset is in random order, but cannot be sure.
I’m not 100% sure but from my experience data and data2 are the same thing, for example if you build two databunches from the same labeledlist and name it data1 and data2, the data2(most recently executed line) will share the parameters with the data1 and becomes an exact copy of data2.
Here is an example:
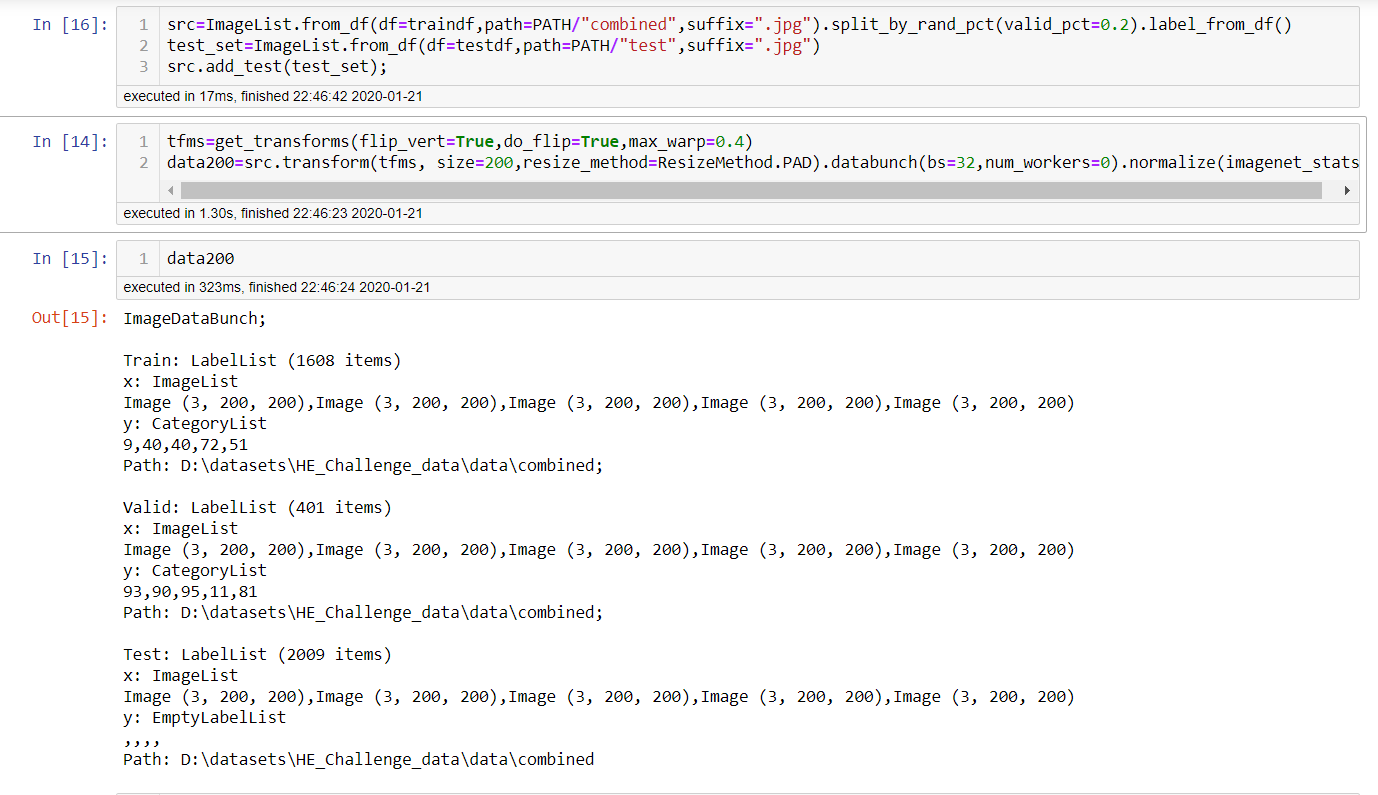
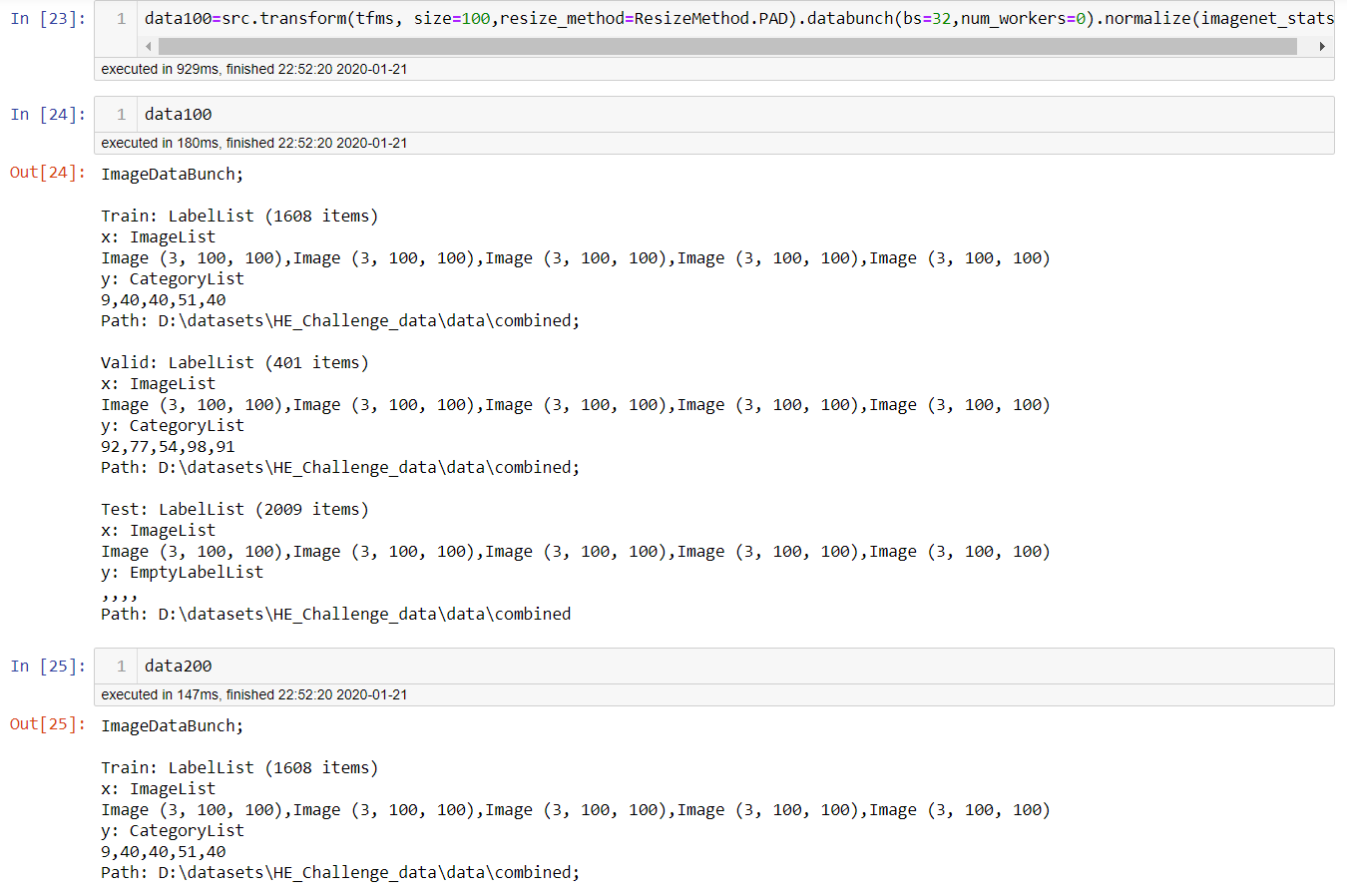
create a databunch with images of size 200 and name it data200
now create a databunch from same src with size 100 and name it data100, and if you print what data200 has now, you can notice data200 has become data100. data200 now has images with size 100x100.

.png?generation=1578931978168360&alt=media)