Pretrained GAN
image to image generation task 有哪些用途
image to image generation task 有哪些用途
- 低像素转高像素
- 黑白转彩色
- 缺失转完整
- 简单线条转名师作画
所需library
所需library
import fastai
from fastai.vision import *
from fastai.callbacks import *
from fastai.vision.gan import *
下载数据,准备文件夹路径
下载数据,准备文件夹路径
path = untar_data(URLs.PETS)
path_hr = path/'images'
path_lr = path/'crappy'
Crappified data
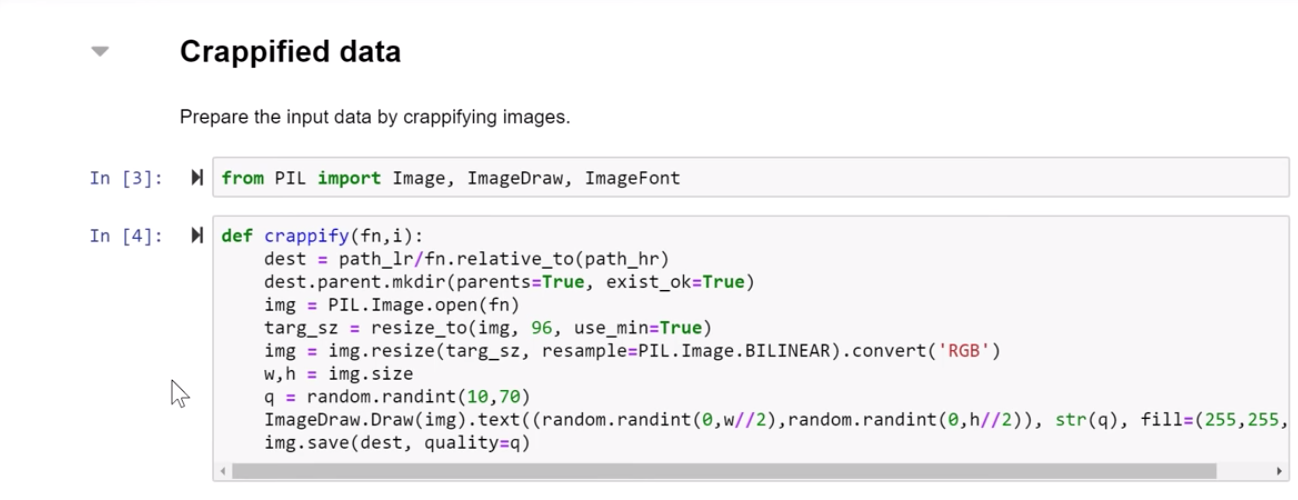
引入crappify函数
引入crappify函数
- 打开图片
- 缩小图片像素至 96x96 (低像素图片)
- 通过bilinear方式缩小图片,保留RGB
- 加入文字jpeg到图片中,文字清晰度随机在10-70间取值(很差,很清晰)
- 文字jpeg位置也是随机
这里是展示创造力的地方
- 从黑白到彩色
- 老照片换新照片
Prepare the input data by crappifying images.
from crappify import *
穿插问题: 为什么concat在2个conv-layer之前进行
穿插问题: 为什么concat在2个conv-layer之前进行
- 为了更多的interaction between downsampling and upsampling
穿插问题: downsampling 和 upsampling是如何能做到concat大小不变?
穿插问题: downsampling 和 upsampling是如何能做到concat大小不变?
- concat只限制在同一个block之中,进入下一个block时,新的concat将重头开始
如何加速crappify图片
如何加速crappify图片
Uncomment the first time you run this notebook.
#il = ImageList.from_folder(path_hr)
#parallel(crappifier(path_lr, path_hr), il.items)
For gradual resizing we can change the commented line here.
bs,size=32, 128
# bs,size = 24,160
#bs,size = 8,256
arch = models.resnet34
Pre-train generator
创建DataBunch
Now let’s pretrain the generator.
创建DataBunch
- 先在src中用crappy文件夹中图片,在分割成训练和验证集
- 在data中用原图来做标注图
- 再变形和转化为DataBunch
arch = models.resnet34
src = ImageImageList.from_folder(path_lr).random_split_by_pct(0.1, seed=42)
def get_data(bs,size):
data = (src.label_from_func(lambda x: path_hr/x.name)
.transform(get_transforms(max_zoom=2.), size=size, tfm_y=True)
.databunch(bs=bs).normalize(imagenet_stats, do_y=True))
data.c = 3
return data
data_gen = get_data(bs,size)
展示图片(crappy和原图)
展示图片(crappy和原图)
data_gen.show_batch(4)

wd = 1e-3
y_range = (-3.,3.)
loss_gen = MSELossFlat()
为什么要用pretrained models
为什么要用pretrained models
- 输入值:低像素,有杂质图片
- label:高像素,无杂质
- 目标:学会去除杂志,提升清晰度
- 所以需要模型本身就知道图片中的所有物品包括杂志
arch = models.resnet34
part 2将讲解的内容
part 2将讲解的内容
norm_type, self_attention, y_range?
def create_gen_learner():
return unet_learner(data_gen, arch, wd=wd, blur=True, norm_type=NormType.Weight,
self_attention=True, y_range=y_range, loss_func=loss_gen)
如何创建模型和训练
如何创建模型和训练
learn_gen = create_gen_learner()
learn_gen.fit_one_cycle(2, pct_start=0.8)
Total time: 01:35
| epoch | train_loss | valid_loss |
|---|---|---|
| 1 | 0.061653 | 0.053493 |
| 2 | 0.051248 | 0.047272 |
如何做全模型训练
如何做全模型训练
learn_gen.unfreeze()
learn_gen.fit_one_cycle(3, slice(1e-6,1e-3))
Total time: 02:24
| epoch | train_loss | valid_loss |
|---|---|---|
| 1 | 0.050429 | 0.046088 |
| 2 | 0.049056 | 0.043954 |
| 3 | 0.045437 | 0.043146 |
为什么提升像素不成功?
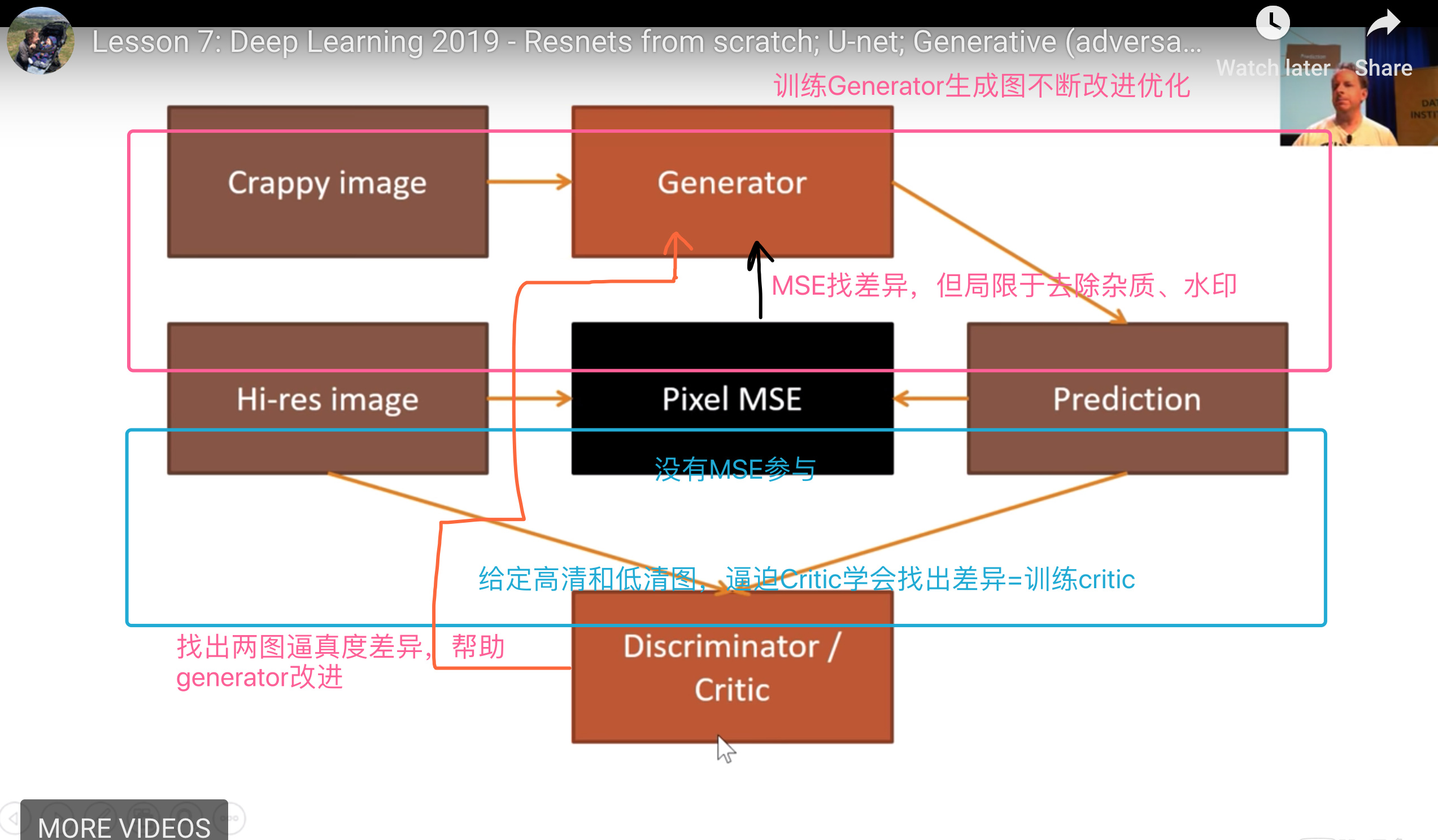
为什么提升像素不成功?
- MSE loss: 无法体现低像素图(消除了水印)与原图的差异
- 高清和纹路的差异,无法在MSE的差异中体现
- 我们需要更新的损失函数
- GAN是一种解决方案
为什么GAN 训练很痛苦?
为什么GAN 训练很痛苦?
- 痛苦在起步,成功起步后就比较快了
- 为什么起步痛苦?
- 因为起步时生成器和分辨器都很无知,无法相互帮助促进
- 好比两个刚刚失明的人要帮助对方行走一样无助
fastai 版本的GAN如何解决这个问题?
fastai 版本的GAN如何解决这个问题?
- 提供预先训练好的生成器和辨别器,直接给出优秀的起步状态
- 这是fast.ai首创(极可能)
保存生成图到新文件夹
保存生成图到新文件夹
- 要训练critic (二元分类),需要原图和生成图对比
- 原图已有,生成图需要新生成
learn_gen.load('gen-pre2'); # 准备生成器模型
name_gen = 'image_gen'
path_gen = path/name_gen # 准备路径
# shutil.rmtree(path_gen)
path_gen.mkdir(exist_ok=True) # 创建文件夹
part2 会有更多自己写源代码的机会(如下)
def save_preds(dl):
i=0
names = dl.dataset.items # 提取文件路径
for b in dl: # 提取一个一个的批量
preds = learn_gen.pred_batch(batch=b, reconstruct=True) # 生成图
for o in preds:
o.save(path_gen/names[i].name) # 提成和保存到指定文件名
i += 1
save_preds(data_gen.fix_dl) # fix_dl ????
查看新生成文件夹中图片
PIL.Image.open(path_gen.ls()[0])

Train critic
如何释放空间,无需重启kernel?
如何释放空间,无需重启kernel?
learn_gen=None
gc.collect() # 能行,只是NVDIA msi 无法展示实际情况,因为Pytorch的设置
3755
Pretrain the critic on crappy vs not crappy.
如何生成critic DataBunch
如何生成critic DataBunch
def get_crit_data(classes, bs, size):
src = ImageList.from_folder(path, include=classes).random_split_by_pct(0.1, seed=42)
# path = PETS 总path, include=classes, subfolders 就是classes
ll = src.label_from_folder(classes=classes) # classes = subfolders (images, image_gen)
data = (ll.transform(get_transforms(max_zoom=2.), size=size)
.databunch(bs=bs).normalize(imagenet_stats))
data.c = 3
return data
data_crit = get_crit_data([name_gen, 'images'], bs=bs, size=size)
data_crit.show_batch(rows=3, ds_type=DatasetType.Train, imgsize=3) # 注意 imgsize=3

BCE loss + AdaptiveLoss ??
BCE loss + AdaptiveLoss ??
loss_critic = AdaptiveLoss(nn.BCEWithLogitsLoss())
如何创建critic模型Learner?
如何创建critic模型Learner?
- 模型框架需要spectral norm
- Resnet 内无此设置,未来可能会植入
- 目前采用gan_critic()模型框架, 内置了spectral norm
def create_critic_learner(data, metrics):
return Learner(data, gan_critic(), metrics=metrics, loss_func=loss_critic, wd=wd)
learn_critic = create_critic_learner(data_crit, accuracy_thresh_expand)
# accuracy_thresh_expand = 为GAN critic定制的accuracy
learn_critic.fit_one_cycle(6, 1e-3)
Total time: 09:40
| epoch | train_loss | valid_loss | accuracy_thresh_expand |
|---|---|---|---|
| 1 | 0.678256 | 0.687312 | 0.531083 |
| 2 | 0.434768 | 0.366180 | 0.851823 |
| 3 | 0.186435 | 0.128874 | 0.955214 |
| 4 | 0.120681 | 0.072901 | 0.980228 |
| 5 | 0.099568 | 0.107304 | 0.962564 |
| 6 | 0.071958 | 0.078094 | 0.976239 |
learn_critic.save('critic-pre2')
GAN
再度释放内容
Now we’ll combine those pretrained model in a GAN.
再度释放内容
learn_crit=None
learn_gen=None
gc.collect()
15794
创建databunch, critic和generator
创建databunch, critic和generator
data_crit = get_crit_data(['crappy', 'images'], bs=bs, size=size)
learn_crit = create_critic_learner(data_crit, metrics=None).load('critic-pre2')
learn_gen = create_gen_learner().load('gen-pre2')
fastai 如何简化GAN建模流程
fastai 如何简化GAN建模流程
To define a GAN Learner, we just have to specify the learner objects for the generator and the critic. The switcher is a callback that decides when to switch from discriminator to generator and vice versa. Here we do as many iterations of the discriminator as needed to get its loss back < 0.5 then one iteration of the generator.
The loss of the critic is given by learn_crit.loss_func. We take the average of this loss function on the batch of real predictions (target 1) and the batch of fake predicitions (target 0).
The loss of the generator is weighted sum (weights in weights_gen) of learn_crit.loss_func on the batch of fake (passed throught the critic to become predictions) with a target of 1, and the learn_gen.loss_func applied to the output (batch of fake) and the target (corresponding batch of superres images).
switcher = partial(AdaptiveGANSwitcher, critic_thresh=0.65)
learn = GANLearner.from_learners(learn_gen, learn_crit,
weights_gen=(1.,50.), # MSEpixel loss set 50x larger,
# critic loss set just 1 scale
show_img=False, switcher=switcher,
# set momentum to 0 in betas, 因为GAN不喜欢momentum
opt_func=partial(optim.Adam, betas=(0.,0.99)), wd=wd)
learn.callback_fns.append(partial(GANDiscriminativeLR, mult_lr=5.))
lr = 1e-4
learn.fit(40,lr)
Total time: 1:05:41
| epoch | train_loss | gen_loss | disc_loss |
|---|---|---|---|
| 1 | 2.071352 | 2.025429 | 4.047686 |
| 2 | 1.996251 | 1.850199 | 3.652173 |
| 3 | 2.001999 | 2.035176 | 3.612669 |
| 4 | 1.921844 | 1.931835 | 3.600355 |
| 5 | 1.987216 | 1.961323 | 3.606629 |
| 6 | 2.022372 | 2.102732 | 3.609494 |
| 7 | 1.900056 | 2.059208 | 3.581742 |
| 8 | 1.942305 | 1.965547 | 3.538015 |
| 9 | 1.954079 | 2.006257 | 3.593008 |
| 10 | 1.984677 | 1.771790 | 3.617556 |
| 11 | 2.040979 | 2.079904 | 3.575464 |
| 12 | 2.009052 | 1.739175 | 3.626755 |
| 13 | 2.014115 | 1.204614 | 3.582353 |
| 14 | 2.042148 | 1.747239 | 3.608723 |
| 15 | 2.113957 | 1.831483 | 3.684338 |
| 16 | 1.979398 | 1.923163 | 3.600483 |
| 17 | 1.996756 | 1.760739 | 3.635300 |
| 18 | 1.976695 | 1.982629 | 3.575843 |
| 19 | 2.088960 | 1.822936 | 3.617471 |
| 20 | 1.949941 | 1.996513 | 3.594223 |
| 21 | 2.079416 | 1.918284 | 3.588732 |
| 22 | 2.055047 | 1.869254 | 3.602390 |
| 23 | 1.860164 | 1.917518 | 3.557776 |
| 24 | 1.945440 | 2.033273 | 3.535242 |
| 25 | 2.026493 | 1.804196 | 3.558001 |
| 26 | 1.875208 | 1.797288 | 3.511697 |
| 27 | 1.972286 | 1.798044 | 3.570746 |
| 28 | 1.950635 | 1.951106 | 3.525849 |
| 29 | 2.013820 | 1.937439 | 3.592216 |
| 30 | 1.959477 | 1.959566 | 3.561970 |
| 31 | 2.012466 | 2.110288 | 3.539897 |
| 32 | 1.982466 | 1.905378 | 3.559940 |
| 33 | 1.957023 | 2.207354 | 3.540873 |
| 34 | 2.049188 | 1.942845 | 3.638360 |
| 35 | 1.913136 | 1.891638 | 3.581291 |
| 36 | 2.037127 | 1.808180 | 3.572567 |
| 37 | 2.006383 | 2.048738 | 3.553226 |
| 38 | 2.000312 | 1.657985 | 3.594805 |
| 39 | 1.973937 | 1.891186 | 3.533843 |
| 40 | 2.002513 | 1.853988 | 3.554688 |
learn.save('gan-1c')
learn.data=get_data(16,192)
learn.fit(10,lr/2)
Total time: 43:07
| epoch | train_loss | gen_loss | disc_loss |
|---|---|---|---|
| 1 | 2.578580 | 2.415008 | 4.716179 |
| 2 | 2.620808 | 2.487282 | 4.729377 |
| 3 | 2.596190 | 2.579693 | 4.796489 |
| 4 | 2.701113 | 2.522197 | 4.821410 |
| 5 | 2.545030 | 2.401921 | 4.710739 |
| 6 | 2.638539 | 2.548171 | 4.776103 |
| 7 | 2.551988 | 2.513859 | 4.644952 |
| 8 | 2.629724 | 2.490307 | 4.701890 |
| 9 | 2.552170 | 2.487726 | 4.728183 |
| 10 | 2.597136 | 2.478334 | 4.649708 |
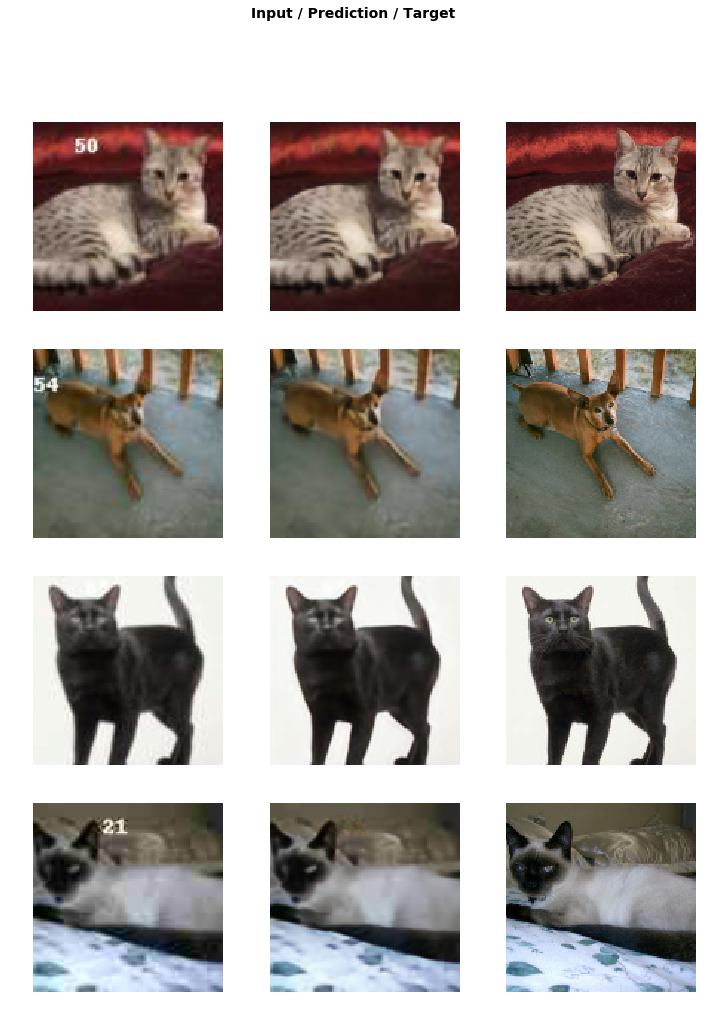
learn.show_results(rows=16)

learn.save('gan-1c')