Daniel
(深度碎片)
83
Lesson 7 U-net story
30:52-48:32
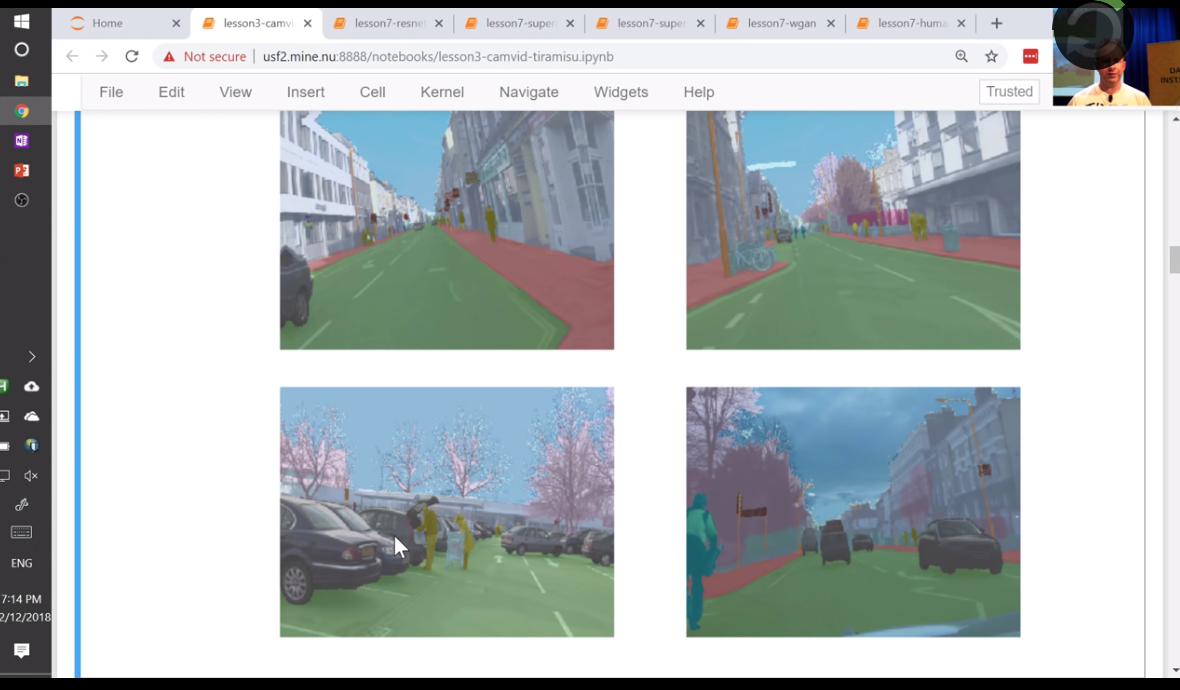
Jeremy 更新了U-net之后在Camvid竞赛中一骑绝尘
Jeremy 更新了U-net之后在Camvid竞赛中一骑绝尘
做Image Segmentation的基本流程逻辑
Image Segmentation的难点在哪?
Image Segmentation的难点在哪?
- 每个像素需要知道自己的物品归属,想象一下就知道难度很大
- 模型要判断一个像素是属于行人,而非自行车者,需要模型真的能理解区分两者
- 怎样的模型能做到这一步呢?
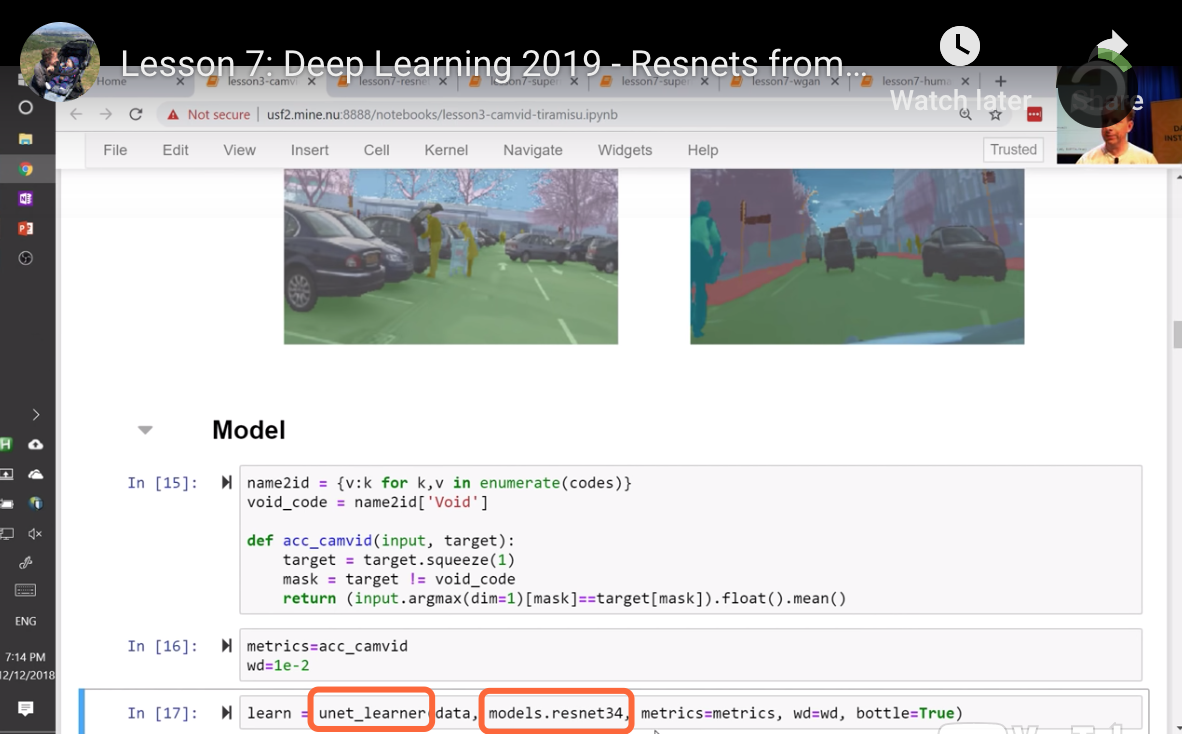
用Resnet 34 预先训练好的模型做成U-net模型
用Resnet 34 预先训练好的模型做成U-net模型
- 没有
pre-train=False,默认状态是True, 使用预训练好的模型
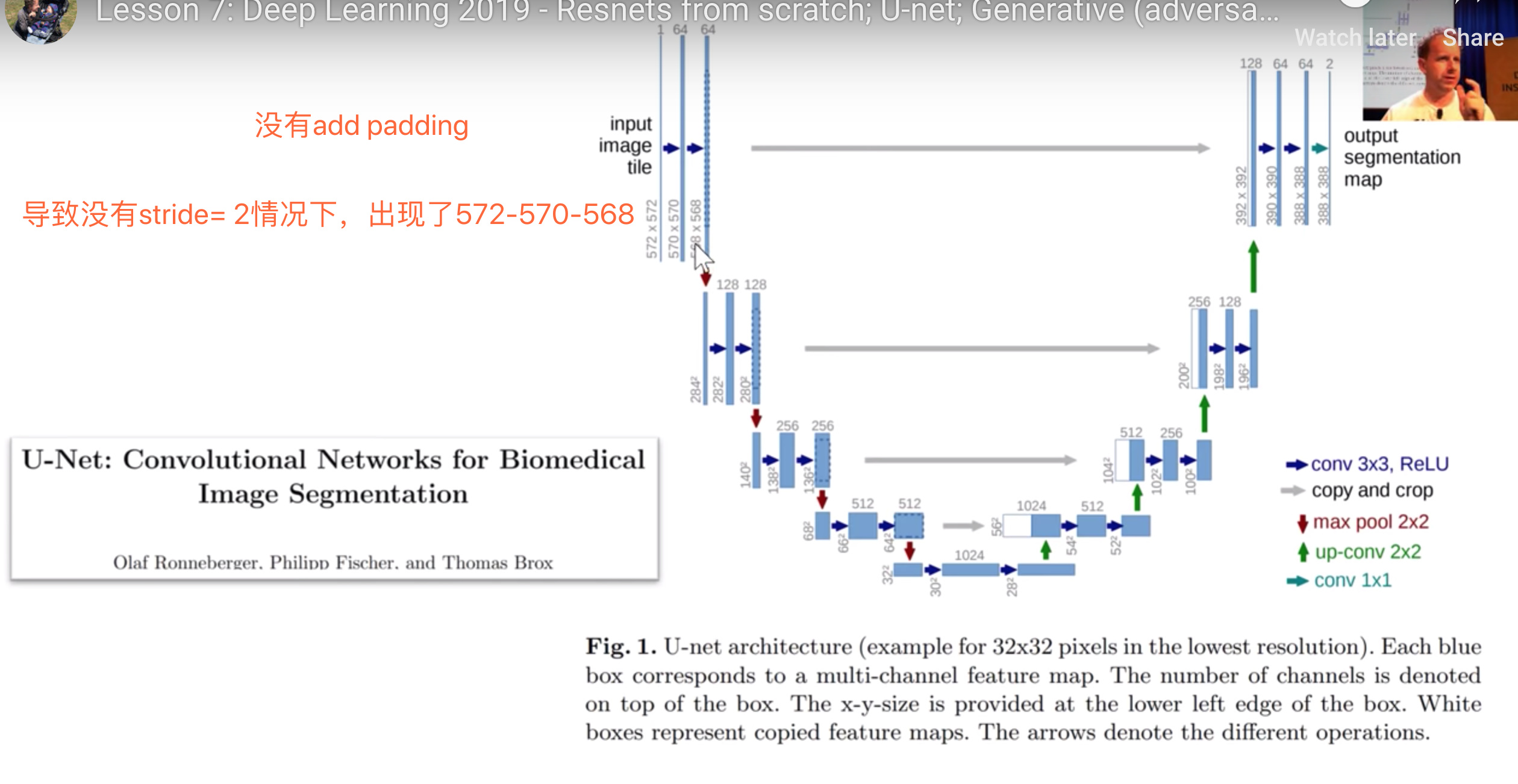
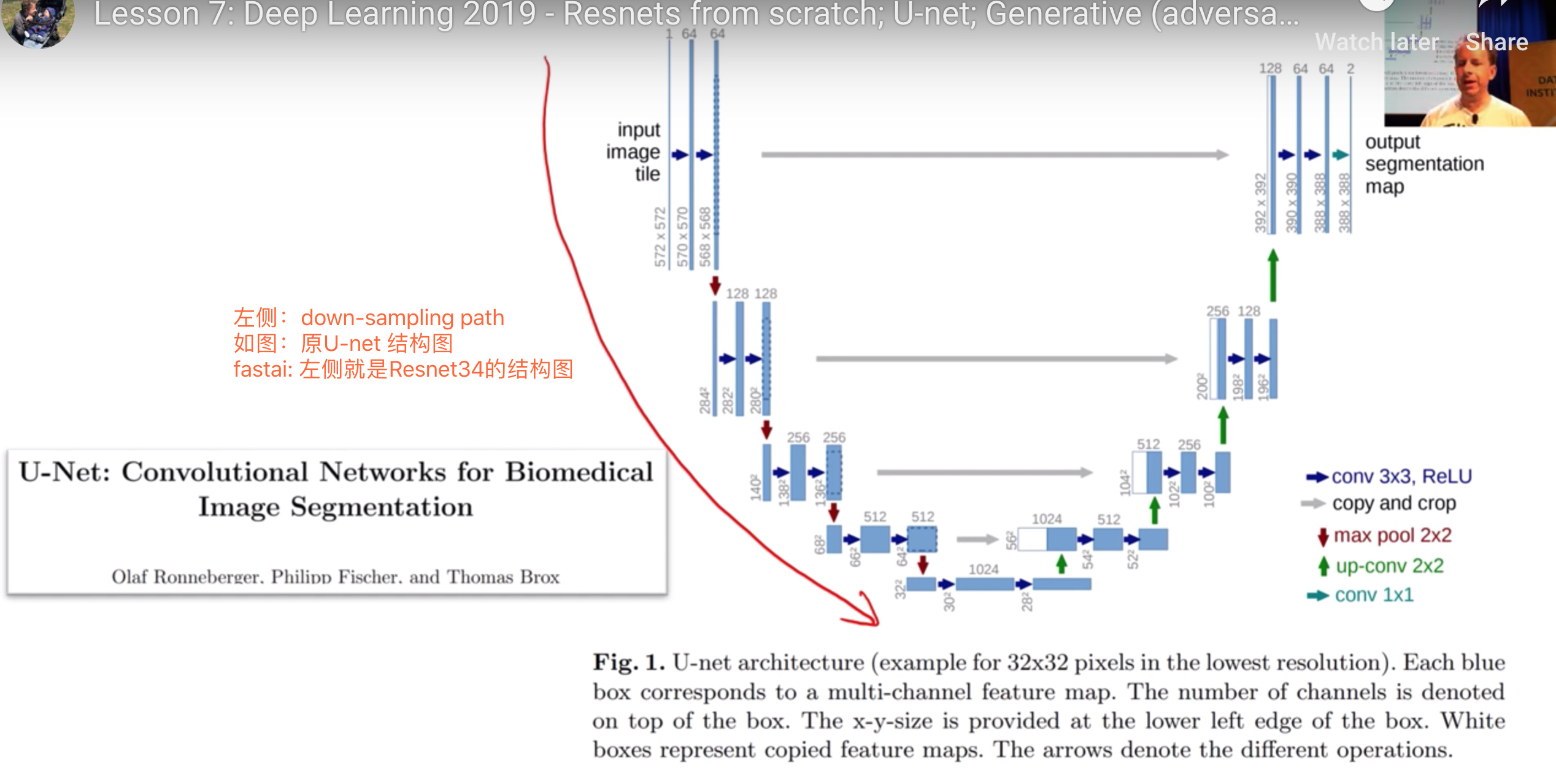
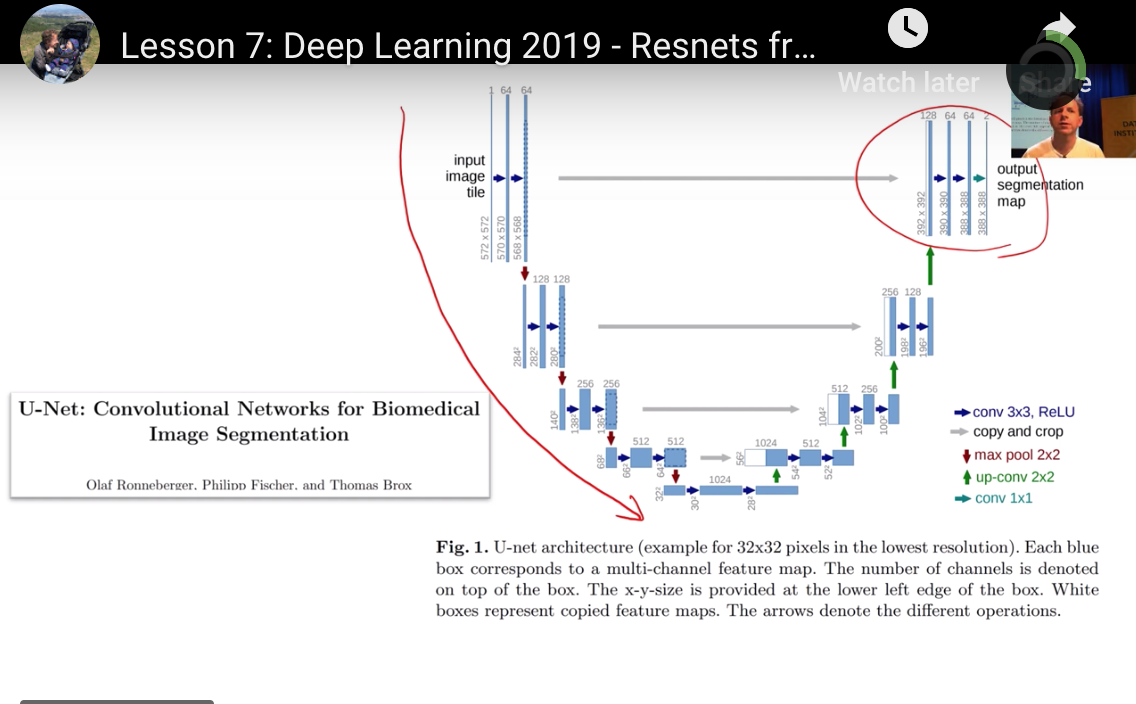
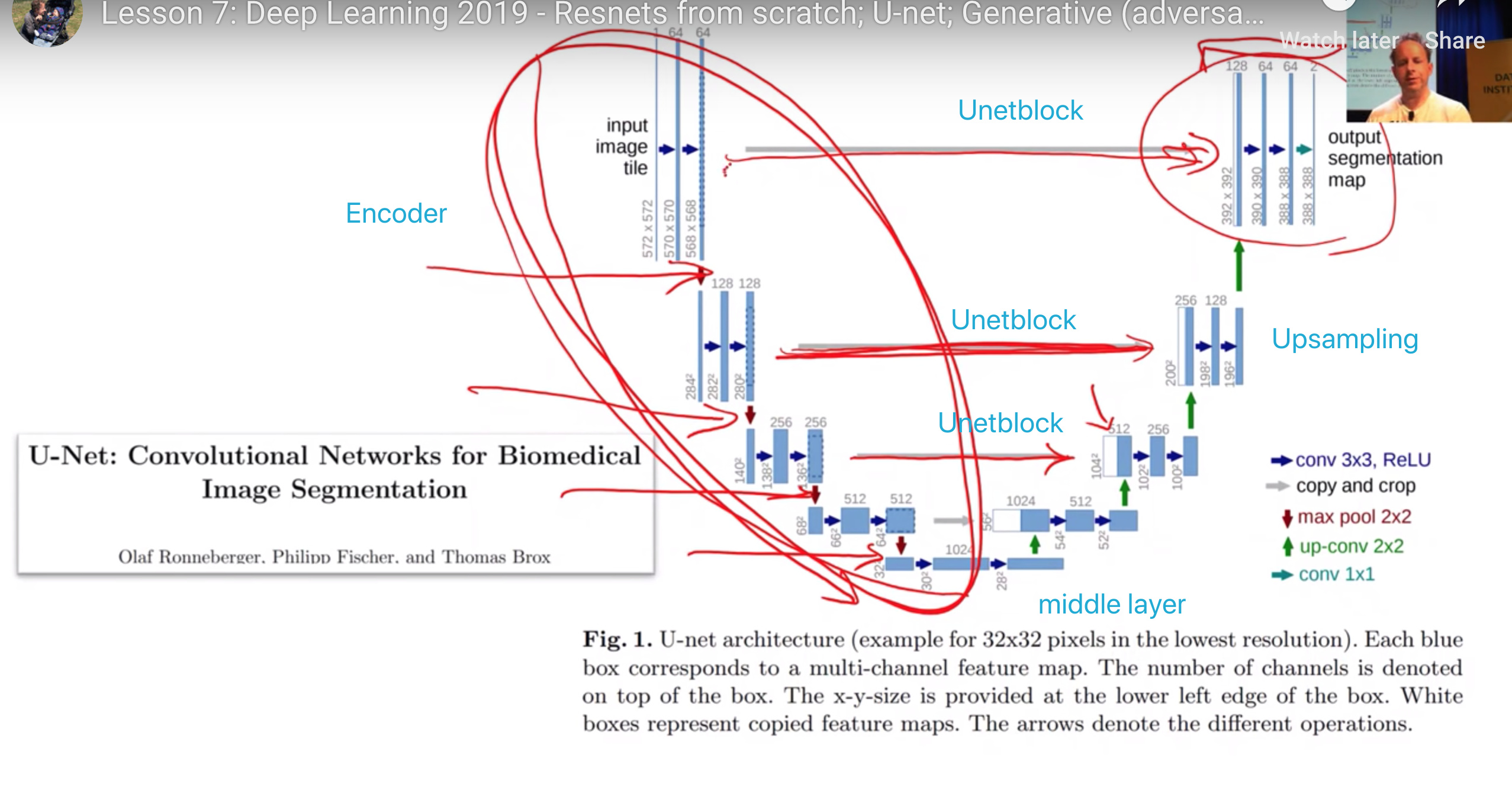
如何理解U-net的构成?
左侧第一个block情况
左侧第一个block情况
- 输入值是原图尺寸 572x572
- 同一个block的conv-layers生成的feature map不会缩小尺寸,但是没有add padding, 所以
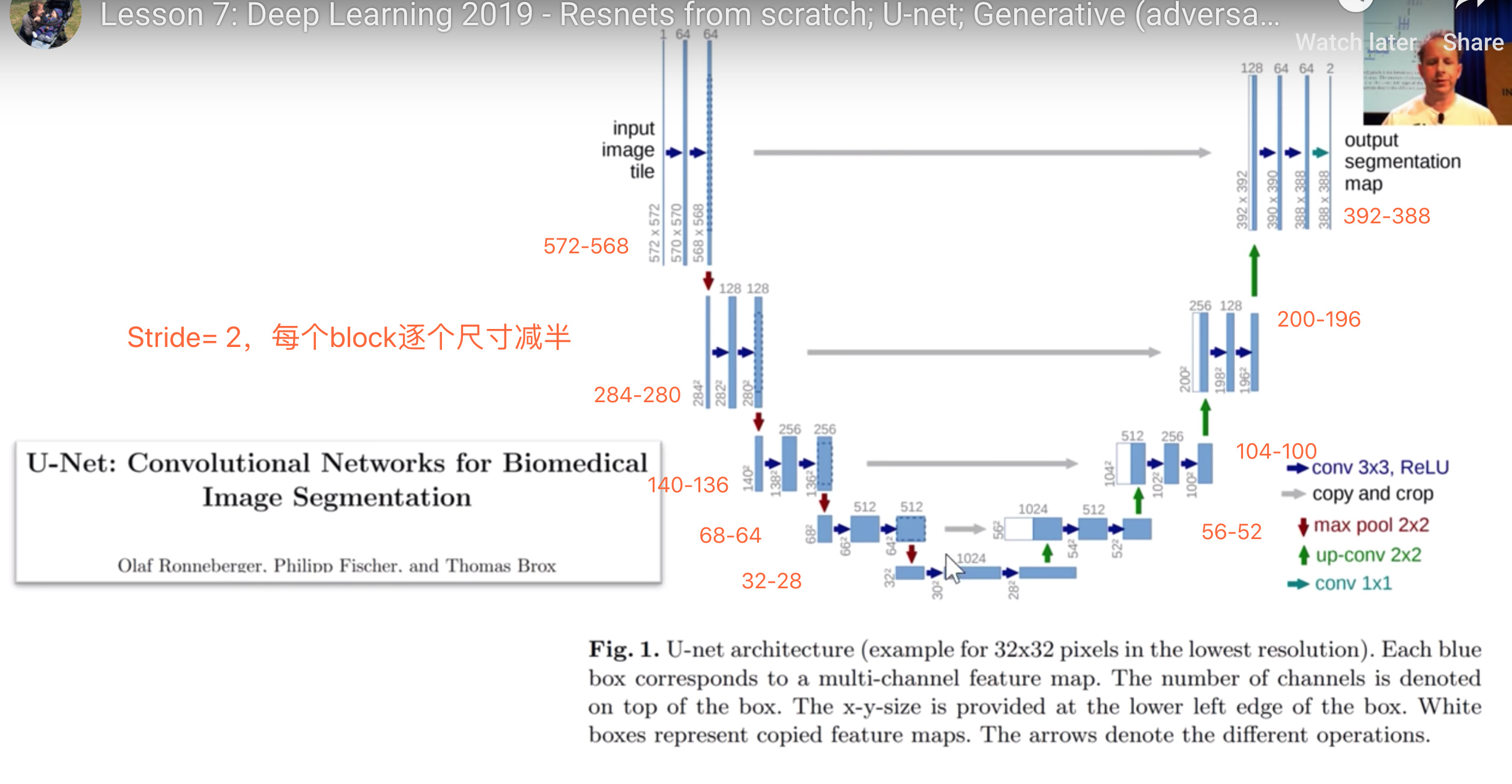
左侧blocks逐个尺寸减半
左侧blocks逐个尺寸减半
右侧blocks逐个翻倍尺寸,如何做到的呢
右侧blocks逐个翻倍尺寸,如何做到的呢?
- stride = 1/2,而不是 = 2
- 这个过程叫deconvolution or transpose-convolution
常规deconvolution的方法
常规deconvolution的方法
- 所有cells为0,很多计算都是浪费资源
- 不同的filter扫描区的信息量不同,也不合理
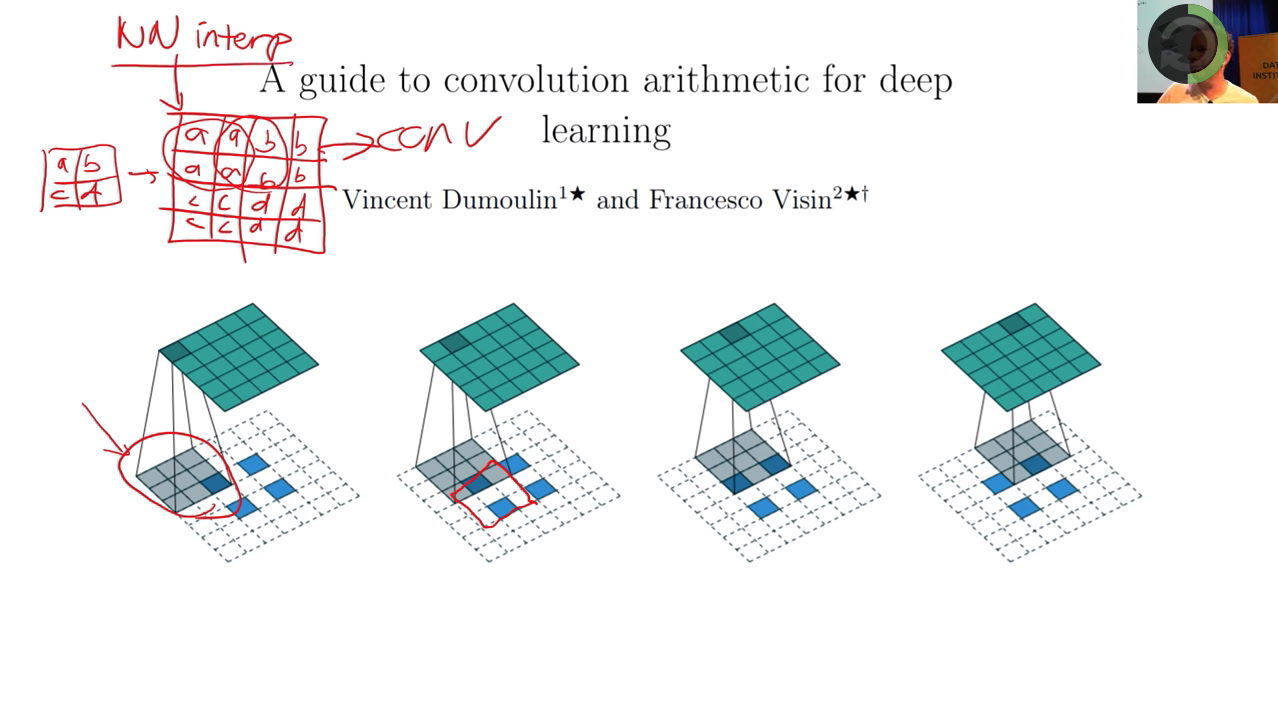
新的deconvolution的方法
新的deconvolution的方法
- 先做Nearest Neighbor interpolation (不存在0浪费计算和信息量不均的问题)
- 再做conv1
另一种方法:bilinear-interpolation
另一种方法:bilinear-interpolation
- 不再是复制粘贴周边cell的值,而是取周边所有cell的均值
fastai 的deconvolution方法
fastai 的deconvolution方法
- pixel shuffle or subpixel convolution
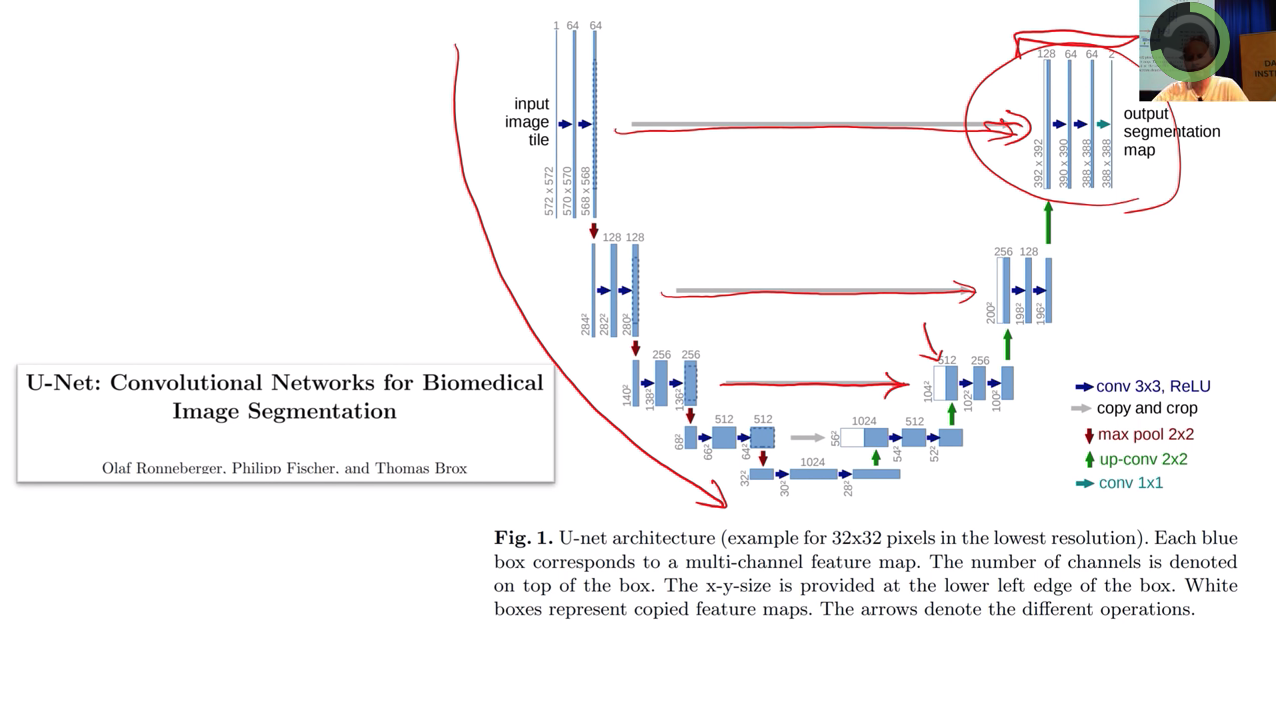
downsampling-convolutions + deconvolution + ? = U-net
downsampling-convolutions + deconvolution + ? = U-net
- 增加skip connection
- skip between the same level
- not add, but concat
- 一直做到将第一层的input image 和最后一层output feature maps的联系到一起的skip connection, 带给模型做segmentation的优势
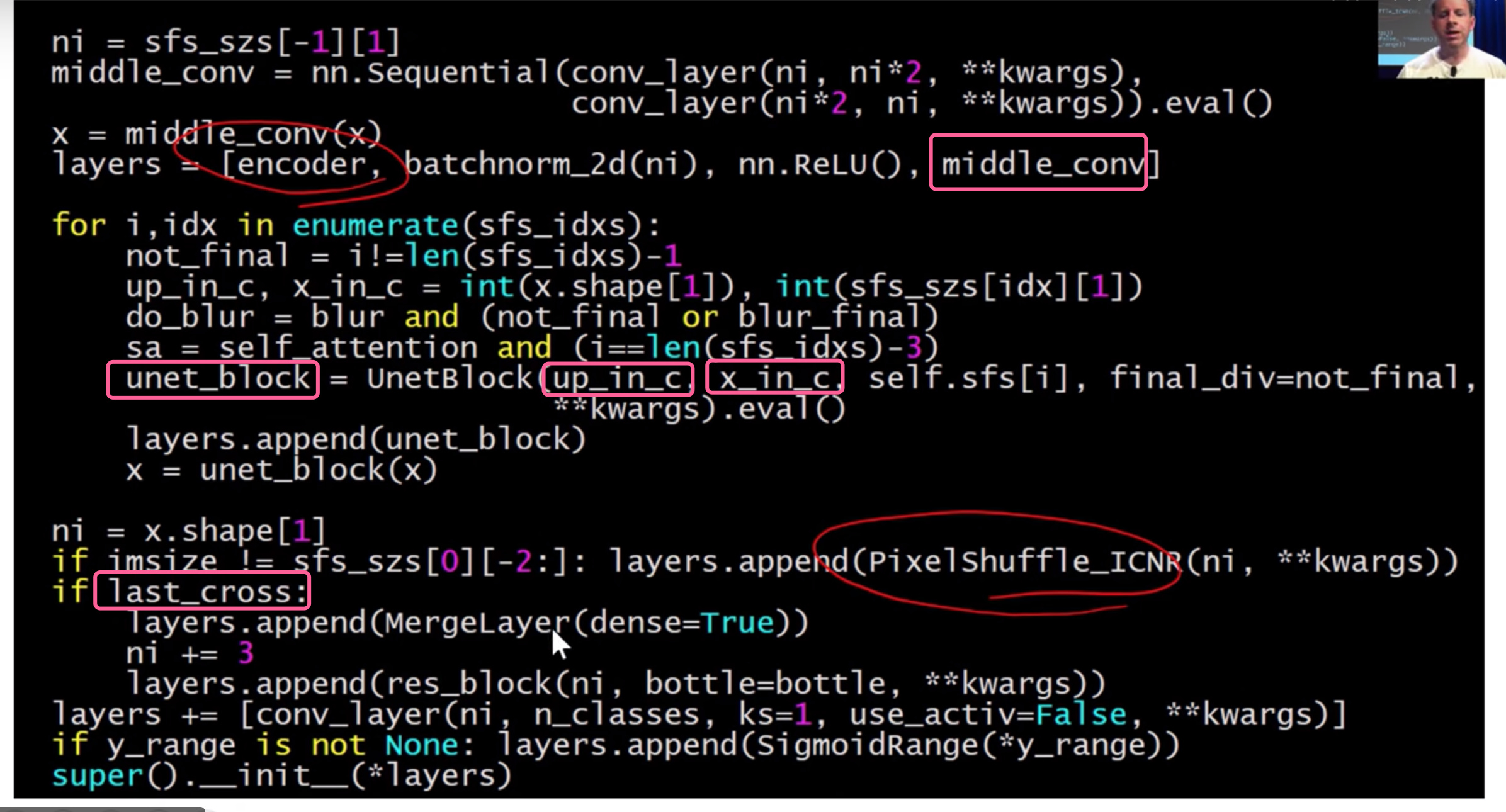
Unet source code
Unet source code
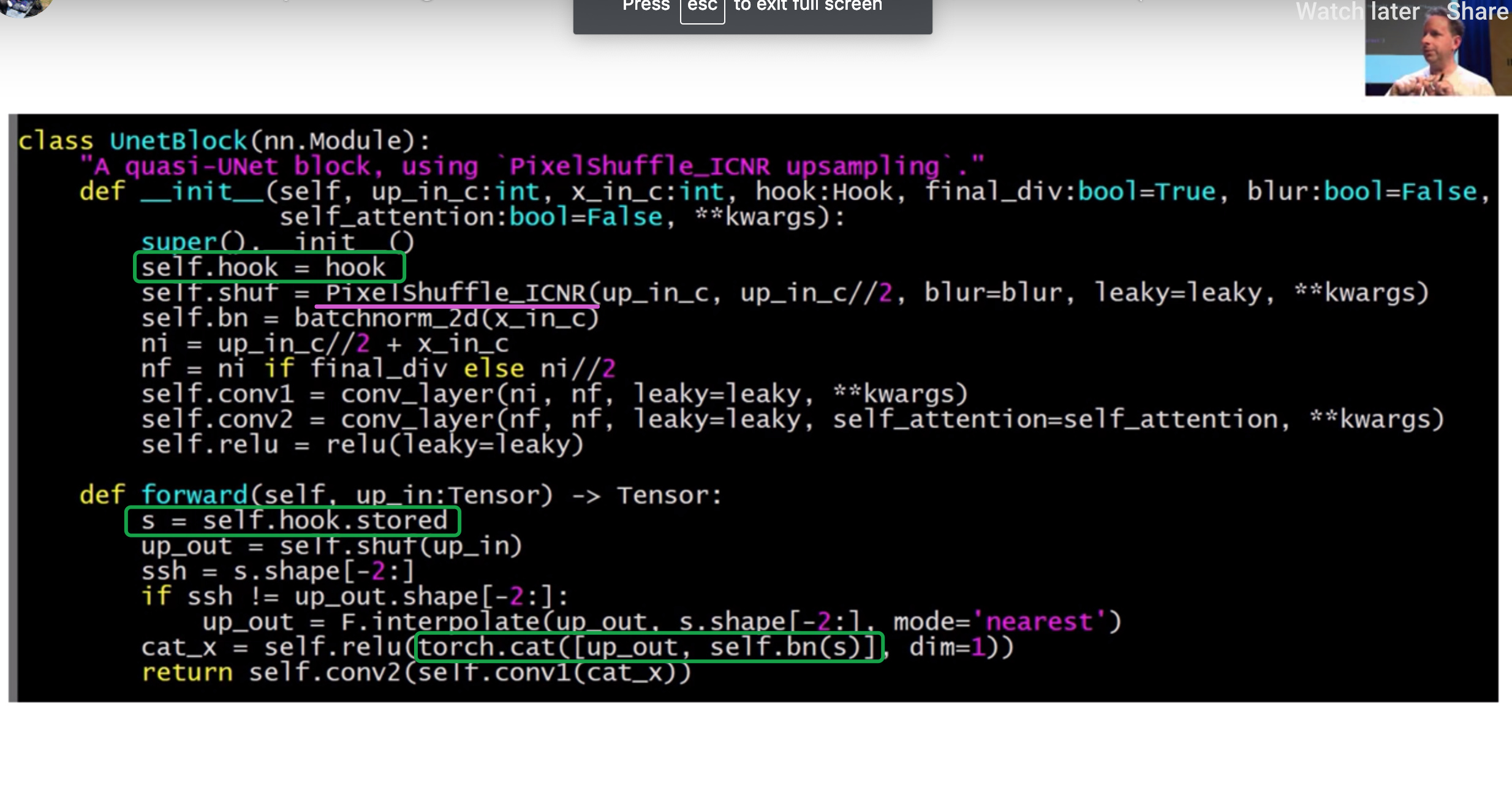
UnetBlock长什么样子
UnetBlock长什么样子
Unet是如何被发现的
- 首先发表在了医学数据科学期刊里,不为深度学习社区所知
- Kaggle竞赛有人使用,开始被Jeremy关注到
- 后有人多次使用,进一步被先知先觉的人关注和研究