Multi-label prediction with Planet Amazon dataset
三行魔法代码
三行魔法代码
%reload_ext autoreload
%autoreload 2
%matplotlib inline
所需library
所需library
from fastai.vision import *
Getting the data
如何从Kaggle下载数据
如何从Kaggle下载数据
The planet dataset isn’t available on the fastai dataset page due to copyright restrictions. You can download it from Kaggle however. Let’s see how to do this by using the Kaggle API as it’s going to be pretty useful to you if you want to join a competition or use other Kaggle datasets later on.
First, install the Kaggle API by uncommenting the following line and executing it, or by executing it in your terminal (depending on your platform you may need to modify this slightly to either add source activate fastai or similar, or prefix pip with a path. Have a look at how conda install is called for your platform in the appropriate Returning to work section of https://course.fast.ai/. (Depending on your environment, you may also need to append “–user” to the command.)
# ! pip install kaggle --upgrade
Then you need to upload your credentials from Kaggle on your instance. Login to kaggle and click on your profile picture on the top left corner, then ‘My account’. Scroll down until you find a button named ‘Create New API Token’ and click on it. This will trigger the download of a file named ‘kaggle.json’.
Upload this file to the directory this notebook is running in, by clicking “Upload” on your main Jupyter page, then uncomment and execute the next two commands (or run them in a terminal). For Windows, uncomment the last two commands.
# ! mkdir -p ~/.kaggle/
# ! mv kaggle.json ~/.kaggle/
# For Windows, uncomment these two commands
# ! mkdir %userprofile%\.kaggle
# ! move kaggle.json %userprofile%\.kaggle
You’re all set to download the data from planet competition. You first need to go to its main page and accept its rules, and run the two cells below (uncomment the shell commands to download and unzip the data). If you get a 403 forbidden error it means you haven’t accepted the competition rules yet (you have to go to the competition page, click on Rules tab, and then scroll to the bottom to find the accept button).
path = Config.data_path()/'planet'
path.mkdir(parents=True, exist_ok=True)
path
PosixPath('/home/ubuntu/.fastai/data/planet')
# ! kaggle competitions download -c planet-understanding-the-amazon-from-space -f train-jpg.tar.7z -p {path}
# ! kaggle competitions download -c planet-understanding-the-amazon-from-space -f train_v2.csv -p {path}
# ! unzip -q -n {path}/train_v2.csv.zip -d {path}
To extract the content of this file, we’ll need 7zip, so uncomment the following line if you need to install it (or run sudo apt install p7zip-full in your terminal).
# ! conda install -y -c haasad eidl7zip
And now we can unpack the data (uncomment to run - this might take a few minutes to complete).
# ! 7za -bd -y -so x {path}/train-jpg.tar.7z | tar xf - -C {path.as_posix()}
Multiclassification
查看CSV,一图多标注
查看CSV,一图多标注
Contrary to the pets dataset studied in last lesson, here each picture can have multiple labels. If we take a look at the csv file containing the labels (in ‘train_v2.csv’ here) we see that each ‘image_name’ is associated to several tags separated by spaces.
df = pd.read_csv(path/'train_v2.csv')
df.head()
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| image_name | tags | |
|---|---|---|
| 0 | train_0 | haze primary |
| 1 | train_1 | agriculture clear primary water |
| 2 | train_2 | clear primary |
| 3 | train_3 | clear primary |
| 4 | train_4 | agriculture clear habitation primary road |
为什么用ImageList而非ImageDataBunch
为什么用ImageList而非ImageDataBunch
To put this in a DataBunch while using the data block API, we then need to using ImageList (and not ImageDataBunch). This will make sure the model created has the proper loss function to deal with the multiple classes.
设置变形细节
设置变形细节
tfms = get_transforms(flip_vert=True, max_lighting=0.1, max_zoom=1.05, max_warp=0.)
We use parentheses around the data block pipeline below, so that we can use a multiline statement without needing to add ‘\’.
用ImageList构建数据src,然后再建DataBunch
用ImageList构建数据src,然后再建DataBunch
np.random.seed(42)
src = (ImageList.from_csv(path, 'train_v2.csv', folder='train-jpg', suffix='.jpg')
.random_split_by_pct(0.2)
.label_from_df(label_delim=' '))
data = (src.transform(tfms, size=128)
.databunch().normalize(imagenet_stats))
查看数据
查看数据
show_batch still works, and show us the different labels separated by ;.
data.show_batch(rows=3, figsize=(12,9))

如何设计thresh_accuracy
如何设计thresh_accuracy
To create a Learner we use the same function as in lesson 1. Our base architecture is resnet34 again, but the metrics are a little bit differeent: we use accuracy_thresh instead of accuracy. In lesson 1, we determined the predicition for a given class by picking the final activation that was the biggest, but here, each activation can be 0. or 1. accuracy_thresh selects the ones that are above a certain threshold (0.5 by default) and compares them to the ground truth.
As for Fbeta, it’s the metric that was used by Kaggle on this competition. See here for more details.
挑选模型结构
挑选模型结构
arch = models.resnet50
设计含threshold的accuracy和F-score
设计含threshold的accuracy和F-score
acc_02 = partial(accuracy_thresh, thresh=0.2)
f_score = partial(fbeta, thresh=0.2)
构建模型
构建模型
learn = create_cnn(data, arch, metrics=[acc_02, f_score])
Downloading: "https://download.pytorch.org/models/resnet50-19c8e357.pth" to /home/ubuntu/.torch/models/resnet50-19c8e357.pth
100%|██████████| 102502400/102502400 [00:01<00:00, 100859665.66it/s]
寻找学习率,作图,挑选最优值
寻找学习率,作图,挑选最优值
We use the LR Finder to pick a good learning rate.
learn.lr_find()
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
learn.recorder.plot()
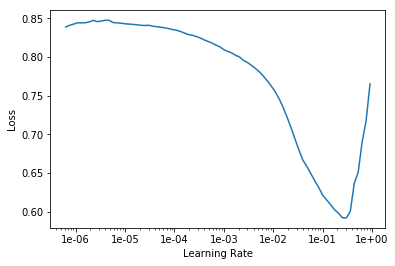
Then we can fit the head of our network.
lr = 0.01
训练模型
训练模型
learn.fit_one_cycle(5, slice(lr))
learn.save('stage-1-rn50')
解冻,再次寻找学习率,再训练
解冻,再次寻找学习率,再训练
…And fine-tune the whole model:
learn.unfreeze()
learn.lr_find()
learn.recorder.plot()
LR Finder complete, type {learner_name}.recorder.plot() to see the graph.
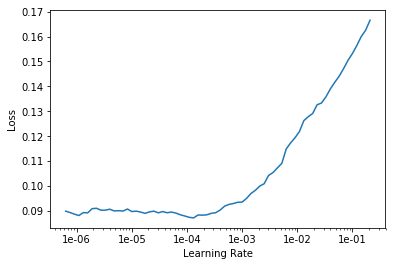
learn.fit_one_cycle(5, slice(1e-5, lr/5))
Total time: 04:00
| epoch | train_loss | valid_loss | accuracy_thresh | fbeta |
|---|---|---|---|---|
| 1 | 0.097016 | 0.094868 | 0.952004 | 0.916215 |
| 2 | 0.095774 | 0.088899 | 0.954540 | 0.922340 |
| 3 | 0.090646 | 0.085958 | 0.959249 | 0.924921 |
| 4 | 0.085097 | 0.083291 | 0.958849 | 0.928195 |
| 5 | 0.079197 | 0.082855 | 0.958602 | 0.928259 |
learn.save('stage-2-rn50')
放大图片,生成新的Databunch
放大图片,生成新的Databunch
data = (src.transform(tfms, size=256)
.databunch().normalize(imagenet_stats))
learn.data = data
data.train_ds[0][0].shape
torch.Size([3, 256, 256])
封冻模型,只训练最后一层
封冻模型,只训练最后一层
learn.freeze()
寻找学习率,作图,选择最优值
寻找学习率,作图,选择最优值
learn.lr_find()
learn.recorder.plot()
LR Finder complete, type {learner_name}.recorder.plot() to see the graph.
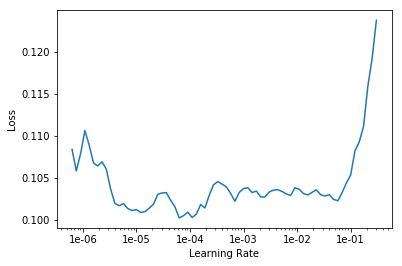
lr=1e-2/2
训练,保存
训练,保存
learn.fit_one_cycle(5, slice(lr))
Total time: 09:01
| epoch | train_loss | valid_loss | accuracy_thresh | fbeta |
|---|---|---|---|---|
| 1 | 0.087761 | 0.085013 | 0.958006 | 0.926066 |
| 2 | 0.087641 | 0.083732 | 0.958260 | 0.927459 |
| 3 | 0.084250 | 0.082856 | 0.958485 | 0.928200 |
| 4 | 0.082347 | 0.081470 | 0.960091 | 0.929166 |
| 5 | 0.078463 | 0.080984 | 0.959249 | 0.930089 |
learn.save('stage-1-256-rn50')
解冻,调节学习效率,再训练
解冻,调节学习效率,再训练
learn.unfreeze()
learn.fit_one_cycle(5, slice(1e-5, lr/5))
Total time: 11:25
| epoch | train_loss | valid_loss | accuracy_thresh | fbeta |
|---|---|---|---|---|
| 1 | 0.082938 | 0.083548 | 0.957846 | 0.927756 |
| 2 | 0.086312 | 0.084802 | 0.958718 | 0.925416 |
| 3 | 0.084824 | 0.082339 | 0.959975 | 0.930054 |
| 4 | 0.078784 | 0.081425 | 0.959983 | 0.929634 |
| 5 | 0.074530 | 0.080791 | 0.960426 | 0.931257 |
画出训练中的损失值变化图
画出训练中的损失值变化图
learn.recorder.plot_losses()
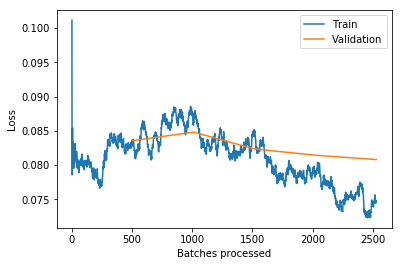
learn.save('stage-2-256-rn50')
Finish
生成预测值,上传Kaggle
生成预测值,上传Kaggle
You won’t really know how you’re going until you submit to Kaggle, since the leaderboard isn’t using the same subset as we have for training. But as a guide, 50th place (out of 938 teams) on the private leaderboard was a score of 0.930.
learn.export()
(This section will be covered in part 2 - please don’t ask about it just yet!  )
)
#! kaggle competitions download -c planet-understanding-the-amazon-from-space -f test-jpg.tar.7z -p {path}
#! 7za -bd -y -so x {path}/test-jpg.tar.7z | tar xf - -C {path}
#! kaggle competitions download -c planet-understanding-the-amazon-from-space -f test-jpg-additional.tar.7z -p {path}
#! 7za -bd -y -so x {path}/test-jpg-additional.tar.7z | tar xf - -C {path}
test = ImageList.from_folder(path/'test-jpg').add(ImageList.from_folder(path/'test-jpg-additional'))
len(test)
61191
learn = load_learner(path, test=test)
preds, _ = learn.get_preds(ds_type=DatasetType.Test)
thresh = 0.2
labelled_preds = [' '.join([learn.data.classes[i] for i,p in enumerate(pred) if p > thresh]) for pred in preds]
labelled_preds[:5]
['agriculture cultivation partly_cloudy primary road',
'clear haze primary water',
'agriculture clear cultivation primary',
'clear primary',
'partly_cloudy primary']
fnames = [f.name[:-4] for f in learn.data.test_ds.items]
df = pd.DataFrame({'image_name':fnames, 'tags':labelled_preds}, columns=['image_name', 'tags'])
df.to_csv(path/'submission.csv', index=False)
! kaggle competitions submit planet-understanding-the-amazon-from-space -f {path/'submission.csv'} -m "My submission"
Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /home/ubuntu/.kaggle/kaggle.json'
100%|██████████████████████████████████████| 2.18M/2.18M [00:02<00:00, 1.05MB/s]
Successfully submitted to Planet: Understanding the Amazon from Space
Private Leaderboard score: 0.9296 (around 80th)