我设置环境已经有2-3个月了, 我不确定具体流程是否有改变. 另外Colab我没有使用过.
- 关于quota的问题, 无论是paperspace还是GCP, 都涉及到GPU的问题. Paperspace default我记得是只有P4000,如果你想要使用P5000,你需要写信给paperspace, 当通过后,你才能创建一个P5000的instance
GCP的话我记得free tier的GPU上限全部是0, 所以如果你run课程的脚本, 会有一个Quota 0.0的报错, 你需要upgrade你的帐号(300credit 保留), 然后写信给google, ask for quota increase.
Paperspace是30分钟通过我的, GCP好像等了半天
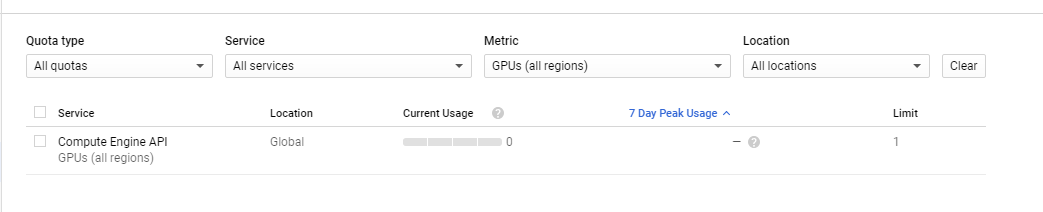
By default, 新帐号的limit应该是0
-
至于GPU方面, 那就得看看浮点数的运算能力. 这个有很多文章评论, 我基本上还是按照课程推荐的设置来进行的, kaggle用的好像是Tesla K80? 而GCP fastai 推荐的是P4
-
另外, 如果不想付费. 因为我不是墙内的用户, 所以我也不太清楚kaggle能不能直接登录
可以在自己的电脑上跑简单的model, 当然, segmentation的问题肯定是时间很长
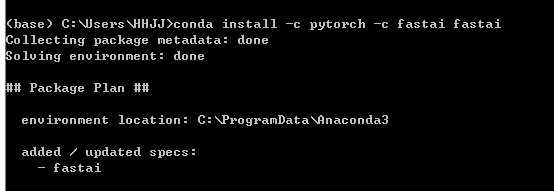
具体设置可以使用conda, 先安装
-
Anaconda3
然后运行Anaconda prompt (windows) -
之后conda install -c pytorch -c fastai fastai
当然, 我个人是很不推荐用这个方法. 因为GPU memory的问题, 建议有能力的话还是用kaggle或者GCP. 另外就是AMD的GPU不支持cuda, 所以如果不是nvdia的GPU基本上就只能用CPU来跑了
特别说明一下, 我自己的电脑因为没有nvdia gpu,所以只能处理一些processing的问题
比如测试一下datablock api, custom item list, hook 以及一些pytorch的功能. 所以我不太清楚这么安装cuda能否工作