This is my first post, and first experience with fastai, so please don’t mind a silly question.
I am trying to train a latin dance style classifier based on images I extracted from a set of dance videos.
My basic approach is to train a pretrained resnet34 on images of 64x64,
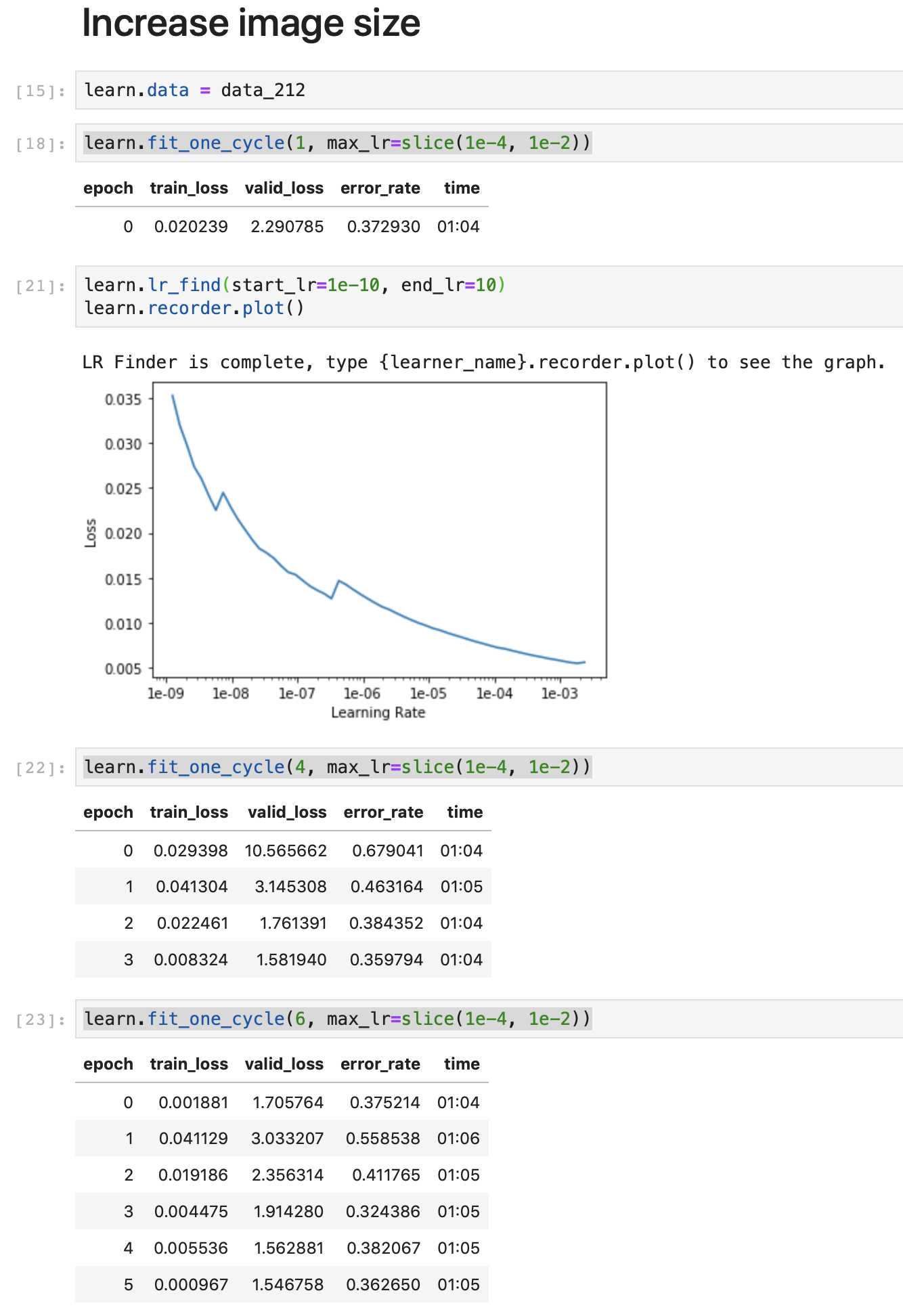
save the weights, and load them into a new resnet34 model that is trained on the same training set but with images of size 212x212.
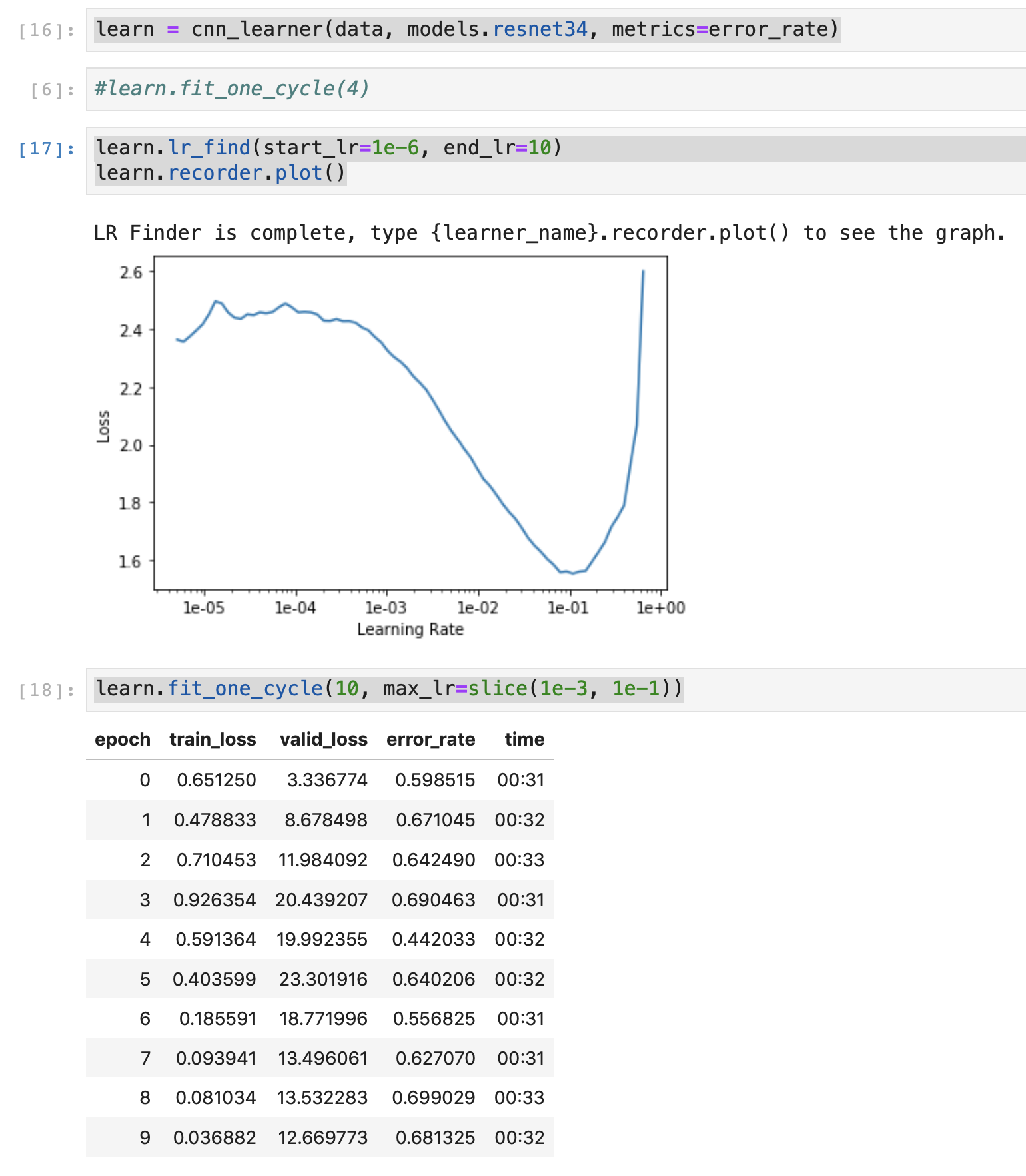
The first training stage (images 64x64) produces the following results
Maybe the problem is too difficult, but I would have expected the net to improve (reduce the error rate) during training.
Do I understand the situation correctly that the model seems to overfill very early, without learning to generalize (huge difference between the training and validation loss).
So the best thing I could do is provide more training data?
Any tipps or suggestions on how to improve the model?
If you are just changing the size of the image, then you don’t have to create different learners. You can just change your data.
src = (ImageList.from_folder(path)
.split_by_folder()
.label_from_folder())
data = (src.transform(get_transforms(), size=(64, 64))
.databunch(bs=256, num_workers=8)
.normalize(imagenet_stats))
# Then for the second time
data = (src.transform(get_transforms(), size=(212, 212))
.databunch(bs=128, num_workers=8)
.normalize(imagenet_stats))
learn.data = data
In the first case, you model is overfitting as your train loss is decreasing but valid loss is increasing. I don’t know much about dance forms so I don’t know if a single image is enough to tell the dance form. But seeing that your model is overfitting the first step is thus to increase your dataset.
Also, you should use learn.unfreeze(). By default in fastai when you create a learner if only trains the last linear layers of the model. By using learn.unfreeze() you train the CNN layers also.
Seeing that 212x212 images do not suffer from overfitting, maybe you don’t need to use 64x64 images, you can use 128x128 images.
Hello @kushaj,
thank you! I have tried training my classifier using your tips (first 128px, than 212px) and using the imagenet_stats normalization, and I get down to an error rate of 0.37.
I do have two follow up questions thought.
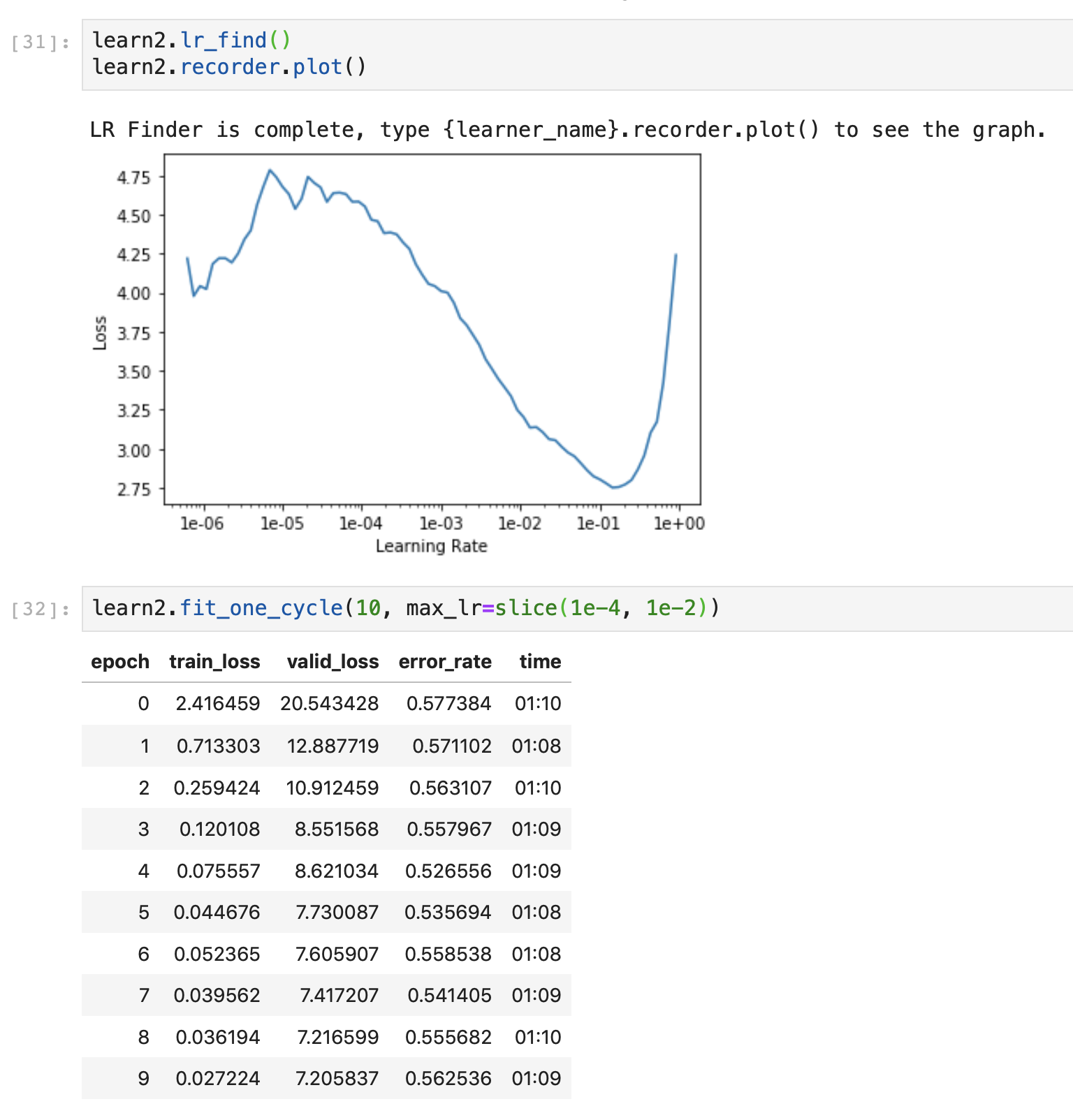
When should I use lr_find()? Only once at the beginning before the first fit? Do I have to find a new learning rate, once I am using the images of increases size?
Running multiple consecutive fit_one_cyle() always produces worse results in the first iterations. Why is that so? I would expect the model to perform similar after another epoch to the results received before. I mean I would the expect the model to continuously improve until it overfitts, but not have this cyclic up and downs.
You can get away with using it in the beginning and then after unfreezing your model. But seeing that it only takes 100 iterations to run, you can run it easily. So whenever I change something, I will do a quick lr_find. By change, I mean some parameter change, regularization change or changes in the learner object.
One thing you have to remember that every epoch is different as you are using random augmentations. As you have limited training set this thing amplifies where your 2 epochs can vary by a large margin. So seeing inconsistent fit_one_cycle values is not that uncommon.
This is one of the thing that also bugged me a lot. The solution that I had to remember was that data augmentations are random and if my training set is small then 2 epochs can have completely different training sets.
One thing you have to remember that every epoch is different as you are using random augmentations. > As you have limited training set this thing amplifies where your 2 epochs can vary by a large margin. So > seeing inconsistent fit_one_cycle values is not that uncommon.
I would have never thought that data augmentation could produce such different training results. The error rate during training is varying between 0.18-0.41. I guess I would need a lot more data for the problem, or find another way to analyze videos (something like a sequence model?)
This effect of data augmentation I never saw in any other framework. How do you cope with it? I guess the effects should get less prominent, increasing the number of augmented images per original image. Are you tuning the data augmentation transforms?
fit_one_cycle increases then decreases the learning rate over a “cycle”. So it can get worse loss if the learning rate is high, and it jumps away from its current solution.
Should be able to use normal fit to continue from where you were at. Or you can progressively lower your maximum learning rate for the cycle.
I got the concept about one cycle learning and had a look at the paper, but I meant that the accuracy/error rate its changing vastly between epochs when training with fit_one_cycle().
So its changing a lot between cycles, and can go in either direction.
You don’t have to worry much about error rates. It does not matter much if the error rate is less and increases. Your main aim is to train a model that generalizes and not overfits.
That is the problem you can easily overfit the validation set by selecting different values of the hyperparameters. But it does not mean that your model has generalized.
That is why you also need an independent dataset that you will initially throw away and after all the hyperparameter tuning and using all the tricks for training the model, you use the test set to see if the model performs well on unseen data.