Hi all – I downloaded about 500 train and images for each category, and 50 validation images from google image search. I found some corrupted ones after some initial training hangs at x%, and was able to get it to progress further. However, I am now hanging like this (below) and cannot complete training. Suggestions?
53%|█████▎ | 8/15 [00:03<00:03, 2.32it/s]
AttributeError Traceback (most recent call last)
~/fastai/courses/dl1/fastai/dataset.py in open_image(fn)
227 try:
→ 228 im = cv2.imread(str(fn), flags).astype(np.float32)/255
229 if im is None: raise OSError(f’File not recognized by opencv: {fn}')
AttributeError: ‘NoneType’ object has no attribute ‘astype’
The above exception was the direct cause of the following exception:
Hope bumping isn’t against forum rules (I looked but didn’t see anything clarifying it.) Going to be spending some time on fast.ai tonight and would love any suggestions on next steps (other than get a different image set.)
To me it looks like another corrupted or missing image. cv2.imread returns none instead of a numpy array of the image. You could try setting the pdb magic command
%pdb on
which will enter a debugging session after the exception occurs. You should be able to look at the variable fn and figure out which image is the offending one. If that doesn’t work try writing a for loop over all the images that you downloaded reading every one using
for filename in filenamelist:
print(filename)
cv2.imread(filename).astype(np.float32)/255
This will crash when you encounter problematic images and you will know the filename.
Perfect, exactly what I needed, thanks. I had started down the imagemagick rabbit hole, but wasn’t sure how to get just the fails outputted in a python context – I’m coming from R so there’s some adjustment.
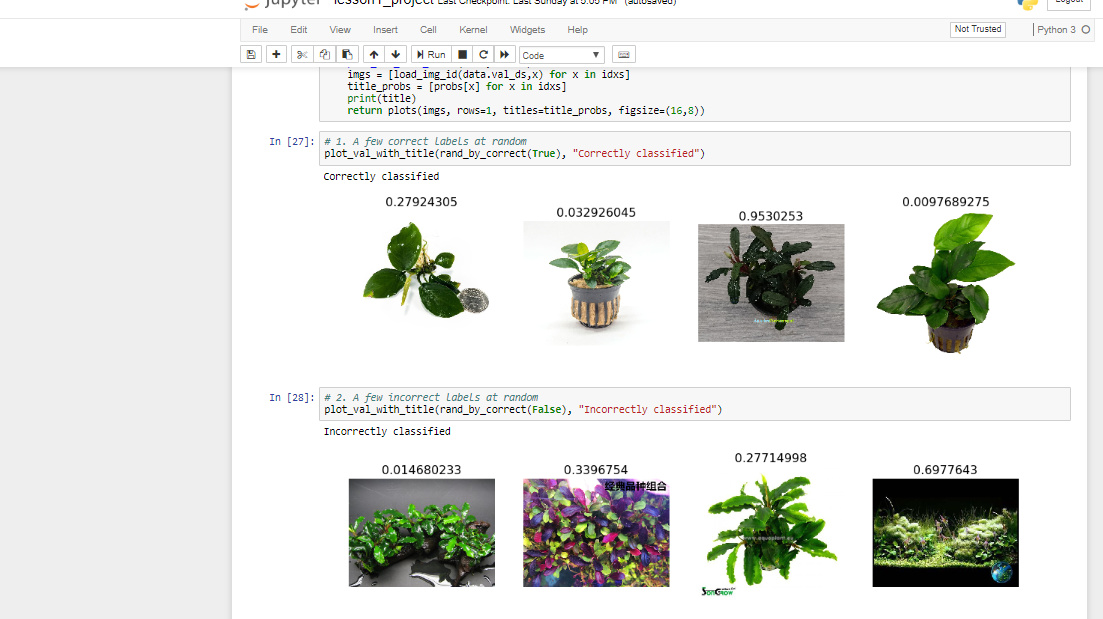
I purposefully chose data I thought would give poor results… Two families of Arum that are used as aquarium plants – Anubias and Bucephelandra. They look very similar, have identical structure and there are certain species that I mistake for each other all the time.
With ~ 450 images of each, 7 epochs, the model returned 90% accuracy (with some images that are just wrong – full aquarium shots, etc mixed in)… I haven’t done tweaking, augmentation, etc yet… I’ve doing data science professionally for some time but just… wow. See below for how visually similar there things are.
I am having the error AttributeError: ‘NoneType’ object has no attribute ‘astype’ . I used Google-image-download to collect my images but I can’t find out if they are corrupt or not.
Hey @bbrandt , is there a way to add a line to remove the corrupted / missing image ? I used batch downloaded 1000 files and now am manually removing each bad image …
Hi I am also having this issue - my path variable is correct and running cv2.imread using listdir works - how can I use this path with the fastai methods:
arch=resnet34
data= ImageClassifierData.from_paths(PATH,tfms=tfms_from_model(arch,sz))
learn= ConvLearner.pretrained(arch,data,precompute=True)
learn.fit(0.01,3)