TL, DR: Used subset of Labeled Faces In the Wild dataset to attempt Face recognition. Hit a brick wall as the number of people got progressively higher (accompanied by a lesser number of images per person).
Data collection: There are a total of 13233 images and 5749 people in the database, and each face has been labeled with the name of the person pictured. The number of images per person varies a lot, most of the people have just one image. For eg., there were only 62 people with 20 images each. I used some pandas/scripting to group the images into 4 sets so that they could be classified (train and valid folders)
lfw-100 - 5 people with 100 images per person, 90 training/10 validation
lfw-20 - 62 people with 20 images per person, 15 training/5 validation
lfw-10 - 158 people with 10 images per person, 7 training/ 3 validation
lfw-5 - 423 people with 5 images per person, 4 training/1 validation
I’ve uploaded the data to GitHub (lfw-classification) with all the accompanying Jupyter files, so they should be reproducible
These are the best results after several hours of iterations using most of the techniques discussed (used only dropout, no other regularization yet)
lfw-100 - 5 people with 100 images per person, 90 training/10 validation : 94% ![]()
lfw-20 - 62 people with 20 images per person, 15 training/5 validation: 89%
lfw-10 - 158 people with 10 images per person, 7 training/ 3 validation: 71.5%
lfw-5 - 423 people with 5 images per person, 4 training/1 validation: 48% ![]()
One major question I have is …how ‘bad’ is 48% in terms of FaceID detection? Since 48% of the time, the model is correctly predicting 1 from 423 classes with just training 4 images per class.
Another major learning (re-learning I should say) is that the model is very sensitive to learning rate. This is more important with small data-sets since I could not effectively use the lr_find - the number of validation images was too less, or the plot was too ‘coarse’. @jeremy maybe something worth looking into? For eg., for lfw-10 the plot is as shown.
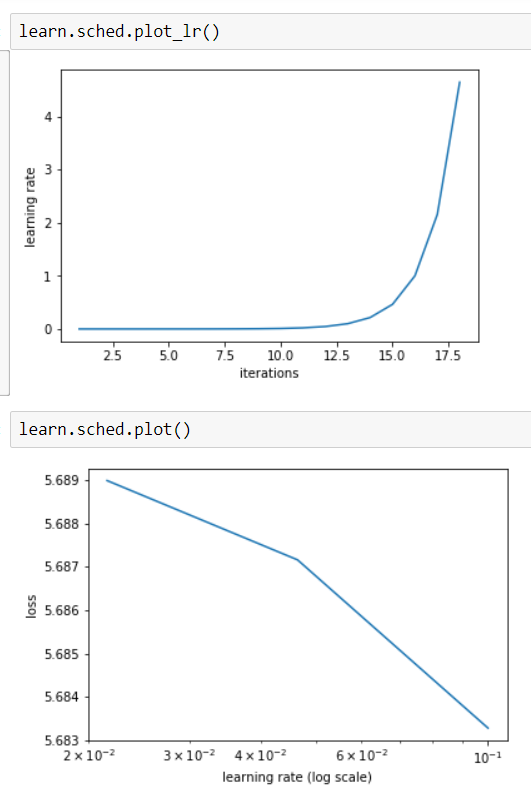
Here are some of the iterations I went through for lfw-20:
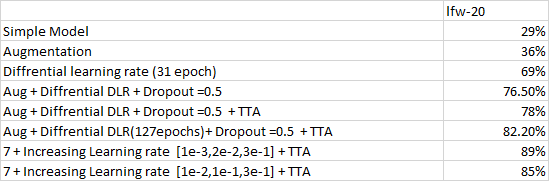
I seem to have hit a plateau after reaching the accuracy numbers above. Are there any other things/techniques I could use? Suggestions welcome!