¿How can I extract the feature vectors from my embeddings layers?. If I’m not wrong, these feature vectors are the weights of the layers
¿Can I use the feature vectors to feed them into others models, like Randon Forest?, ¿Do I need a separate trained NN just for the embeddings, so that the can be used in others models?
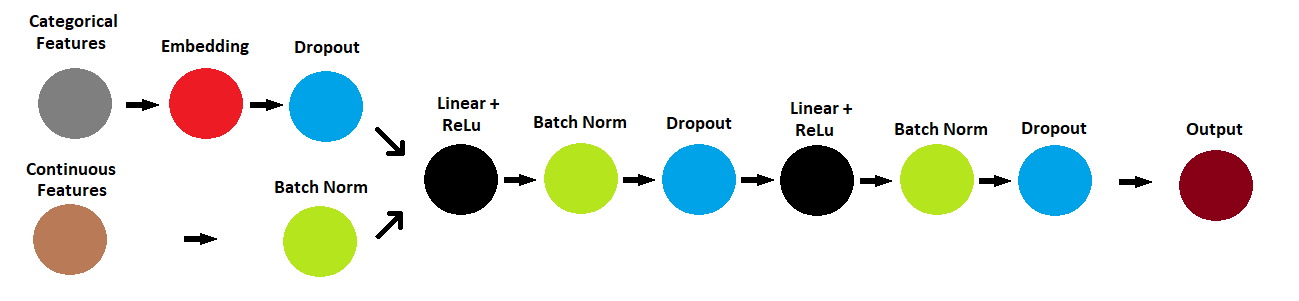
If I were to train an NN just for the embbedings, ¿wich would be the target variable?. According to above arquitecture, the target needs also the continius features to be predicted.
¿What am I supposed to do in the case, let’s say, that the test/validation set contains a level for some categorical value, wich it’s not present in the training set? In that case, the trained embedding layers won’t have a feature vector for that absent level in test/validation
You can simply do list(model.children()) (or list(learn.model.children() if you have directly defined a learner) and see the index of the embedding vector, and tap the .parameters() attribute of that layer.
Well, the answer is not definitive. I would expect the RF model to work somewhat accurately if i were to directly take out the embedding vector from a trained NN. But to make it work well, you’d need to train it in the RF as well. Thats because the parameters of the embedding vectors themselves dont make any sense, only the combination of various layers of parameters makes sense, if you understand what I’m trying to say.
Please elaborate on this a little. I think i dont understand your point. Sorry for that.
You cant use the test data in that case. First of all, the model has no mechanism to take data as inputs, that are not compatible with the architecture. Then, there are no weights to handle extra features. You’d either have to remove the extra features from the test/valid set, or access training data that has those extra features as well
What I mean is, instead of using One-Hot on Random Forest, replace the original categorical features with the feature vector of each level (values) of the categorical features, which are the embeddings coming from an NN
Jeremy, in the Movie Lens dataset, explained the use of embeddins for user and movies, to predict de rating. In the arquitecture above, the target no only depends on the categorical variables, but also the continius (in Movie Lens there were just categoricals). Let’s suppose I want to use embedding in Random Forest, instead of One-Hot… the question is ¿Do I need firstly to train an NN for the embeddings?. I this were the case, I don’t know how to proceed, because in Movie Lens there were just two categorical variables which was enough to predict de rating …
I the arquitecture above, the target depends on the cantegorical and continius features, and if I were to train an NN just for the embeddins (to feed them into a Random Forest) I got confused about the predicted target.
I think you misunderstood. I posed and scenario similiar to that when you have a training set and use LabelEncoder(), and then on validation/test the model found a label which wasn’t fitted on training by LabelEncoder() (because that label wasn’t present on some categorical feature)
Thanks for your time and help. I hope I’ve explained myself well
Oh i see. Thats a good idea. You can try that and see how the model would perform. The only issue is that the embedding vectors are not true values. For example, the input categorical data represents ground truth. But all your parameters in the model represent a function which is meant to be close to the actual mapping function, but almost never the same. So the information represented by embedding vectors is not the same as the actual information that your categorical input represents. This would affect your accuracy a little. However, What you’re trying to do would work, and maybe even give good results. But the right approach (theoretically) would be to use the ground truth data as your input
I’m still a little confused. From what I understand, you want to feed all continuous variables and the embedding vectors into the RF model. Am i right? In that case, you would want to simply pick up the embedding vector parameters from the NN model, and feed it to the RF.
The targets are always class categories. Eg - Positive or Negative ; Cat or Dog, etc. So you would have to train any model with the output being the classes that you’re trying to classify.
Ah okay, I understand. You cant do anything. Your model will give some output, but it will definitely be a wrong prediction. Your model can only work well on the type of data that you’ve trained your model on. But still, is there anything specific in your mind?
But the categorical features ground truth dont’t have any semantic relationshipt between them. That’s why I want to use the embeddings instead, which already have captured relationships between the categorical features and their levels. Yes, I now embeddings vectors are not true values, but I think the semantic captured in the embeddings would help the model to perform well instead of using other encoding thecnique like LabelEncoder or OneHot.
So, my features for my Random Forest model would be the embedding vectors plus the origin continius features
I trained a model using a fully conected NN with embeddings. The target es the column income. The model performs well (you can see the metrics).
But now, I want to use XGBoost and give it a try. However, considering the originals dataset’s, income is predicted using the categorical and continius features. So, I don’t want to use OneHot o similars, because I would be losing the semantic between the categorical features, and that’s why I want to feed the embeddings vectors into XGBoost, with the others continius features obviously. So, my questions are:
Can I just take the weights from my nn.Embedding layers from my model UciAdultsClassifier and feed them into XGBoost? As I said, with also the others continius features. I’m just replacing the form of the categorical features
Do I need to train a separate fully connected NN with just the categorical variables using nn.Embedding layers and predict income? is this correct or the right way of using embeddings vectors in others models than NN’s? Is this approach correct, that is, train a new NN with just nn.Embedding layers to predict income (and not consider the continius features. Danger !!), and then use those embedding vectors or weights to use them in XGBoost?
To be honest, I dont see how it makes any sense. If you recall, the way embedding vectors work are, for each category of a categorical variable a separate embedding vector is fed to the neural network. The embedding vector is nothing but the collection of embedding vectors related to each category of a categorical variable.
For example. if my categorical variable is a n feature vector (a nx1 vector) and my embedding matrix is a mxn matrix. Then if the input is one hot encoded at, say the, i’th position, then the output from the embedding matrix would be nothing but the i’th column of the embedding matrix.
So now, if you feed all the weights from the embedding layer to a neural network as its continuous variables, it would be like feeding information for a categorical variable, which is not one-hot encoded, but rather, all-hot encoded (if that’s a word)
You must have understood how this wont work either. You only train the i’th column if the input is one hot encoded at the ith place. Rest all are not trained. So each column of the embedding matrix is trained to represent only one of the categories of all possible categories in a categorical variable. Now if you train all weights together, you’ll end up “mixing” all the information. Also I don’t see how you would proceed to train such a model. What would be the input of the model?
Cheers!
Thanks my friend for yours answers … I think I wont’ continue with this approache. Nevertheless, I share with you the following Medium, which it’s my motivation for all this thread
I hope you can examinate with time, and give me your feedback